Wird Kernel-Speicherplatz verwendet, wenn Kernel im Namen des Benutzerprogramms ausgeführt wird, d. h. Systemaufruf? Oder ist es der Adressraum für alle Kernel-Threads (zB Scheduler)?
Ja und ja.
Bevor wir weitermachen, sollten wir dies über das Gedächtnis sagen.
Speicher wird in zwei verschiedene Bereiche unterteilt:
- Der Benutzerbereich , das ist eine Reihe von Speicherorten, an denen normale Benutzerprozesse ausgeführt werden (d. h. alles andere als der Kernel). Die Rolle des Kernels besteht darin, Anwendungen, die in diesem Bereich laufen, davon abzuhalten, sich gegenseitig und die Maschine zu verwirren.
- Der Kernel-Space , das ist der Ort, an dem der Code des Kernels gespeichert ist und ausgeführt wird unter.
Prozesse, die im Benutzerbereich ausgeführt werden, haben nur Zugriff auf einen begrenzten Teil des Speichers, während der Kernel Zugriff auf den gesamten Speicher hat. Prozesse, die im User Space laufen, tun dies nicht Zugriff auf den Kernelspace haben. Userspace-Prozesse können nur auf einen kleinen Teil des Kernels zugreifen über eine vom Kernel verfügbar gemachte Schnittstelle - die Systemaufrufe . Wenn ein Prozess einen Systemaufruf ausführt, wird ein Software-Interrupt an den Kernel gesendet, der dann den entsprechenden Interrupt-Handler absetzt und seine Arbeit fortsetzt, nachdem der Handler beendet ist.
Kernel-Space-Code hat die Eigenschaft, im "Kernel-Modus" ausgeführt zu werden, was (in Ihrem typischen Desktop-x86- Computer) das ist, was Sie Code nennen, der unter Ring 0 ausgeführt wird . Normalerweise gibt es in der x86-Architektur 4 Schutzringe . Ring 0 (Kernel-Modus), Ring 1 (kann von Hypervisoren oder Treibern virtueller Maschinen verwendet werden), Ring 2 (kann von Treibern verwendet werden, da bin ich mir jedoch nicht so sicher). Unter Ring 3 laufen typische Anwendungen. Es ist der am wenigsten privilegierte Ring, und Anwendungen, die darauf ausgeführt werden, haben Zugriff auf eine Teilmenge der Anweisungen des Prozessors. Ring 0 (Kernel Space) ist der privilegierteste Ring und hat Zugriff auf alle Anweisungen der Maschine. Beispielsweise kann eine "einfache" Anwendung (wie ein Browser) die x86-Assembleranweisungen lgdt nicht verwenden um die globale Deskriptortabelle zu laden oder hlt um einen Prozessor anzuhalten.
Wenn es das erste ist, bedeutet das dann, dass ein normales Benutzerprogramm nicht mehr als 3 GB Speicher haben kann (wenn die Aufteilung 3 GB + 1 GB ist)? Wie kann der Kernel in diesem Fall High Memory verwenden, denn welcher virtuellen Speicheradresse werden die Seiten aus dem High Memory zugeordnet, da 1 GB Kernel-Speicherplatz logisch zugeordnet wird?
Eine Antwort darauf finden Sie in der hervorragenden Antwort von wag hier
CPU-Ringe sind die deutlichste Unterscheidung
Im geschützten x86-Modus befindet sich die CPU immer in einem von 4 Ringen. Der Linux-Kernel verwendet nur 0 und 3:
- 0 für Kernel
- 3 für Nutzer
Dies ist die härteste und schnellste Definition von Kernel vs. Userland.
Warum Linux die Ringe 1 und 2 nicht verwendet:https://stackoverflow.com/questions/6710040/cpu-privilege-rings-why-rings-1-and-2-arent-used
Wie wird der aktuelle Ring bestimmt?
Der aktuelle Ring wird ausgewählt durch eine Kombination aus:
-
globale Deskriptortabelle:eine speicherinterne Tabelle mit GDT-Einträgen, und jeder Eintrag hat ein Feld
Privldie den Ring kodiert.Der LGDT-Befehl setzt die Adresse auf die aktuelle Deskriptortabelle.
Siehe auch:http://wiki.osdev.org/Global_Descriptor_Table
-
die Segmentregister CS, DS usw., die auf den Index eines Eintrags in der GDT zeigen.
Beispiel:
CS = 0bedeutet, dass der erste Eintrag der GDT derzeit für den ausführenden Code aktiv ist.
Was kann jeder Ring?
Der CPU-Chip ist physisch so aufgebaut, dass:
-
Ring 0 kann alles tun
-
Ring 3 kann nicht mehrere Befehle ausführen und in mehrere Register schreiben, insbesondere:
-
kann seinen eigenen Ring nicht ändern! Andernfalls könnte es sich selbst auf Ring 0 setzen und Ringe wären nutzlos.
Mit anderen Worten, kann den aktuellen Segmentdeskriptor, der den aktuellen Ring bestimmt, nicht ändern.
-
kann die Seitentabellen nicht ändern:https://stackoverflow.com/questions/18431261/how-does-x86-paging-work
Mit anderen Worten, das CR3-Register kann nicht geändert werden, und das Paging selbst verhindert die Änderung der Seitentabellen.
Dies verhindert, dass ein Prozess den Speicher anderer Prozesse aus Gründen der Sicherheit / Einfachheit der Programmierung sieht.
-
kann Interrupt-Handler nicht registrieren. Diese werden durch Beschreiben von Speicherstellen konfiguriert, was ebenfalls durch Paging verhindert wird.
Handler laufen in Ring 0 und würden das Sicherheitsmodell brechen.
Mit anderen Worten, die LGDT- und LIDT-Anweisungen können nicht verwendet werden.
-
kann keine IO-Anweisungen wie
inausführen undout, und haben somit beliebige Hardwarezugriffe.Andernfalls wären beispielsweise Dateiberechtigungen nutzlos, wenn jedes Programm direkt von der Festplatte lesen könnte.
Genauer gesagt dank Michael Petch:Es ist tatsächlich möglich, dass das Betriebssystem IO-Anweisungen auf Ring 3 zulässt, dies wird tatsächlich durch das Task-Statussegment gesteuert.
Was nicht möglich ist, ist, dass Ring 3 sich selbst die Erlaubnis dazu gibt, wenn er sie überhaupt nicht hatte.
Linux verbietet es immer. Siehe auch:https://stackoverflow.com/questions/2711044/why-doesnt-linux-use-the-hardware-context-switch-via-the-tss
-
Wie wechseln Programme und Betriebssysteme zwischen Ringen?
-
Wenn die CPU eingeschaltet wird, beginnt sie, das anfängliche Programm in Ring 0 auszuführen (naja, irgendwie, aber es ist eine gute Annäherung). Sie können sich dieses anfängliche Programm als Kernel vorstellen (aber normalerweise ist es ein Bootloader, der dann den Kernel immer noch in Ring 0 aufruft).
-
Wenn ein Userland-Prozess möchte, dass der Kernel etwas für ihn tut, z. B. in eine Datei schreibt, verwendet er eine Anweisung, die einen Interrupt generiert, wie z. B.
int 0x80odersyscallum den Kernel zu signalisieren. x86-64-Linux-Systemaufruf-Hello-World-Beispiel:.data hello_world: .ascii "hello world\n" hello_world_len = . - hello_world .text .global _start _start: /* write */ mov $1, %rax mov $1, %rdi mov $hello_world, %rsi mov $hello_world_len, %rdx syscall /* exit */ mov $60, %rax mov $0, %rdi syscallkompilieren und ausführen:
as -o hello_world.o hello_world.S ld -o hello_world.out hello_world.o ./hello_world.outGitHub-Upstream.
Wenn dies geschieht, ruft die CPU einen Interrupt-Callback-Handler auf, den der Kernel beim Booten registriert hat. Hier ist ein konkretes Bare-Metal-Beispiel, das einen Handler registriert und verwendet.
Dieser Handler läuft in Ring 0, der entscheidet, ob der Kernel diese Aktion zulässt, die Aktion ausführt und das Userland-Programm in Ring 3 neu startet. x86_64
-
wenn die
execSystemaufruf verwendet wird (oder wenn der Kernel/initstartet ), bereitet der Kernel die Register und den Speicher des neuen Userland-Prozesses vor, springt dann zum Einstiegspunkt und schaltet die CPU auf Ring 3 -
Wenn das Programm versucht, etwas Unanständiges zu tun, wie z. B. in ein verbotenes Register oder eine Speicheradresse zu schreiben (wegen Paging), ruft die CPU auch einen Kernel-Callback-Handler in Ring 0 auf.
Aber da das Userland unartig war, könnte der Kernel diesmal den Prozess beenden oder ihn mit einem Signal warnen.
-
Wenn der Kernel bootet, richtet er eine Hardware-Uhr mit einer festen Frequenz ein, die periodisch Interrupts erzeugt.
Diese Hardware-Uhr erzeugt Interrupts, die Ring 0 ausführen, und ermöglicht es ihr, zu planen, welche Userland-Prozesse aufwachen sollen.
Auf diese Weise kann die Planung auch dann erfolgen, wenn die Prozesse keine Systemaufrufe durchführen.
Welchen Sinn haben mehrere Ringe?
Es gibt zwei Hauptvorteile der Trennung von Kernel und Userland:
- Es ist einfacher, Programme zu erstellen, da Sie sicherer sind, dass das eine das andere nicht stört. Beispielsweise muss sich ein Userland-Prozess nicht darum kümmern, den Speicher eines anderen Programms aufgrund von Paging zu überschreiben oder Hardware für einen anderen Prozess in einen ungültigen Zustand zu versetzen.
- es ist sicherer. Z.B. Dateiberechtigungen und Speichertrennung könnten verhindern, dass eine Hacking-App Ihre Bankdaten ausliest. Dies setzt natürlich voraus, dass Sie dem Kernel vertrauen.
Wie spielt man damit herum?
Ich habe ein Bare-Metal-Setup erstellt, das eine gute Möglichkeit sein sollte, Ringe direkt zu manipulieren:https://github.com/cirosantilli/x86-bare-metal-examples
Ich hatte leider nicht die Geduld, ein Userland-Beispiel zu machen, aber ich bin so weit gegangen, wie das Paging eingerichtet wurde, also sollte Userland machbar sein. Ich würde gerne einen Pull-Request sehen.
Alternativ laufen Linux-Kernel-Module in Ring 0, sodass Sie damit privilegierte Operationen ausprobieren können, z. Lesen Sie die Steuerregister:https://stackoverflow.com/questions/7415515/how-to-access-the-control-registers-cr0-cr2-cr3-from-a-program-getting-segmenta/7419306#7419306
Hier ist ein bequemes QEMU + Buildroot-Setup, um es auszuprobieren, ohne Ihren Host zu töten.
Der Nachteil von Kernelmodulen ist, dass andere kthreads laufen und Ihre Experimente stören könnten. Aber theoretisch können Sie alle Interrupt-Handler mit Ihrem Kernel-Modul übernehmen und das System besitzen, das wäre tatsächlich ein interessantes Projekt.
Negative Ringe
Während im Intel-Handbuch nicht wirklich auf negative Ringe verwiesen wird, gibt es tatsächlich CPU-Modi, die über weitere Fähigkeiten als Ring 0 selbst verfügen und daher gut zum Namen "negativer Ring" passen.
Ein Beispiel ist der bei der Virtualisierung verwendete Hypervisor-Modus.
Weitere Einzelheiten finden Sie unter:
- https://security.stackexchange.com/questions/129098/what-is-protection-ring-1
- https://security.stackexchange.com/questions/216527/ring-3-exploits-and-existence-of-other-rings
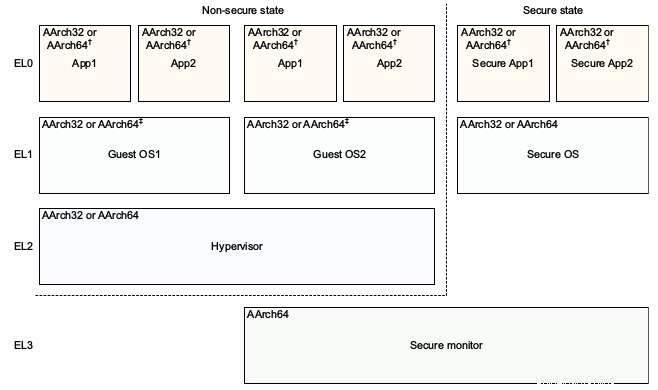
ARM
In ARM werden die Ringe stattdessen Ausnahmestufen genannt, aber die Hauptideen bleiben gleich.
Es gibt 4 Ausnahmeebenen in ARMv8, die üblicherweise verwendet werden als:
-
EL0:Benutzerland
-
EL1:Kernel ("Supervisor" in der ARM-Terminologie).
Eingegeben mit dem
svcAnweisung (SuperVisor Call), früher bekannt alsswivor der einheitlichen Assemblierung, das ist die Anweisung, die zum Ausführen von Linux-Systemaufrufen verwendet wird. Hallo Welt ARMv8-Beispiel:Hallo.S
.text .global _start _start: /* write */ mov x0, 1 ldr x1, =msg ldr x2, =len mov x8, 64 svc 0 /* exit */ mov x0, 0 mov x8, 93 svc 0 msg: .ascii "hello syscall v8\n" len = . - msgGitHub-Upstream.
Testen Sie es mit QEMU auf Ubuntu 16.04:
sudo apt-get install qemu-user gcc-arm-linux-gnueabihf arm-linux-gnueabihf-as -o hello.o hello.S arm-linux-gnueabihf-ld -o hello hello.o qemu-arm helloHier ist ein konkretes Bare-Metal-Beispiel, das einen SVC-Handler registriert und einen SVC-Aufruf durchführt.
-
EL2:Hypervisoren, zum Beispiel Xen.
Eingegeben mit dem
hvcAnweisung (HyperVisor-Aufruf).Ein Hypervisor ist für ein Betriebssystem, was ein Betriebssystem für ein Userland ist.
Mit Xen können Sie beispielsweise mehrere Betriebssysteme wie Linux oder Windows gleichzeitig auf demselben System ausführen, und es isoliert die Betriebssysteme aus Gründen der Sicherheit und der einfachen Fehlersuche voneinander, genau wie Linux es für Userland-Programme tut.
Hypervisoren sind ein wichtiger Bestandteil der heutigen Cloud-Infrastruktur:Sie ermöglichen es, mehrere Server auf einer einzigen Hardware zu betreiben, wodurch die Hardwarenutzung immer nahe bei 100 % bleibt und viel Geld gespart wird.
AWS zum Beispiel verwendete Xen bis 2017, als der Wechsel zu KVM für Schlagzeilen sorgte.
-
EL3:noch eine andere Ebene. TODO-Beispiel.
Eingegeben mit dem
smcAnweisung (Aufruf im sicheren Modus)
Das Referenzmodell der ARMv8-Architektur DDI 0487C.a – Kapitel D1 – Das AArch64-Programmierermodell auf Systemebene – Abbildung D1-1 veranschaulicht dies sehr schön:
Die ARM-Situation hat sich mit dem Aufkommen von ARMv8.1 Virtualization Host Extensions (VHE) etwas geändert. Diese Erweiterung ermöglicht es dem Kernel, effizient in EL2 zu laufen:
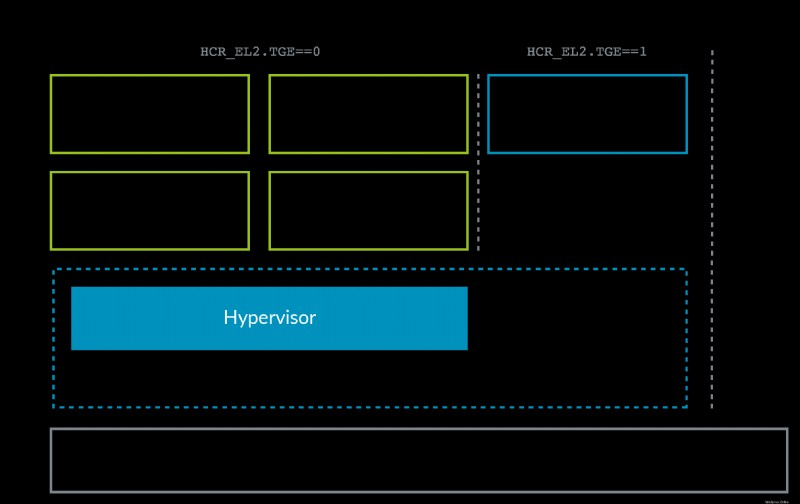
VHE wurde entwickelt, weil In-Linux-Kernel-Virtualisierungslösungen wie KVM gegenüber Xen an Boden gewonnen haben (siehe z. B. den oben erwähnten Wechsel von AWS zu KVM), weil die meisten Clients nur Linux-VMs benötigen und, wie Sie sich vorstellen können, alles in einem sind project ist KVM einfacher und potenziell effizienter als Xen. In diesen Fällen fungiert nun also der Host-Linux-Kernel als Hypervisor.
Beachten Sie, dass ARM, vielleicht im Nachhinein, eine bessere Namenskonvention für die Berechtigungsstufen als x86 hat, ohne dass negative Stufen erforderlich sind:0 ist die niedrigere und 3 die höchste. Höhere Ebenen werden häufiger erstellt als niedrigere.
Der aktuelle EL kann mit dem MRS abgefragt werden Anleitung:https://stackoverflow.com/questions/31787617/what-is-the-current-execution-mode-exception-level-etc
ARM erfordert nicht, dass alle Ausnahmeebenen vorhanden sind, um Implementierungen zu ermöglichen, die die Funktion zum Einsparen von Chipfläche nicht benötigen. ARMv8 "Ausnahmestufen" sagt:
Eine Implementierung enthält möglicherweise nicht alle Ausnahmeebenen. Alle Implementierungen müssen EL0 und EL1 enthalten. EL2 und EL3 sind optional.
QEMU zum Beispiel ist standardmäßig auf EL1 eingestellt, aber EL2 und EL3 können mit Befehlszeilenoptionen aktiviert werden:https://stackoverflow.com/questions/42824706/qemu-system-aarch64-entering-el1-when-emulating-a53-power-up
Codeausschnitte getestet auf Ubuntu 18.10.
Wenn es das erste ist, bedeutet das dann, dass ein normales Benutzerprogramm nicht mehr als 3 GB Speicher haben kann (wenn die Aufteilung 3 GB + 1 GB ist)?
Ja, das ist auf einem normalen Linux-System der Fall. Es gab eine Reihe von "4G/4G"-Patches, die an einer Stelle herumschwirrten, die die Benutzer- und Kernel-Adressräume vollständig unabhängig machten (auf Kosten der Leistung, weil es für den Kernel schwieriger wurde, auf den Benutzerspeicher zuzugreifen), aber ich glaube nicht Sie wurden immer stromaufwärts zusammengeführt und das Interesse schwand mit dem Aufstieg von x86-64
Wie kann der Kernel in diesem Fall High Memory verwenden, denn welcher virtuellen Speicheradresse werden die Seiten aus dem High Memory zugeordnet, da 1 GB Kernel-Speicherplatz logisch zugeordnet wird?
Die Art und Weise, wie Linux früher funktionierte (und immer noch auf Systemen funktioniert, in denen der Speicher im Vergleich zum Adressraum klein ist), bestand darin, dass der gesamte physische Speicher permanent dem Kernel-Teil des Adressraums zugeordnet wurde. Dadurch konnte der Kernel ohne Neuzuordnung auf den gesamten physischen Speicher zugreifen, aber er skaliert offensichtlich nicht auf 32-Bit-Maschinen mit viel physischem Speicher.
So wurde das Konzept des niedrigen und hohen Gedächtnisses geboren. "Niedriger" Speicher wird dauerhaft in den Adressraum des Kernels abgebildet. "hoher" Speicher ist es nicht.
Wenn der Prozessor einen Systemaufruf ausführt, läuft er im Kernelmodus, aber immer noch im Kontext des aktuellen Prozesses. Es kann also sowohl auf den Kernel-Adressraum als auch auf den Benutzer-Adressraum des aktuellen Prozesses direkt zugreifen (vorausgesetzt, Sie verwenden nicht die oben genannten 4G/4G-Patches). Das bedeutet, dass es kein Problem ist, einem Userland-Prozess "hohen" Speicher zuzuweisen.
Die Verwendung von "hohem" Speicher für Kernelzwecke ist eher ein Problem. Um auf hohen Speicher zuzugreifen, der nicht dem aktuellen Prozess zugeordnet ist, muss er vorübergehend in den Adressraum des Kernels abgebildet werden. Das bedeutet zusätzlichen Code und eine Leistungseinbuße.