Es ist eigentlich ziemlich einfach, zumindest wenn Sie die Implementierungsdetails nicht benötigen.
Zunächst einmal sind unter Linux alle Dateisysteme (ext2, ext3, btrfs, reiserfs, tmpfs, zfs, ...) im Kernel implementiert. Einige können Arbeit über FUSE in Userland-Code auslagern, andere kommen nur in Form eines Kernel-Moduls (natives ZFS ist aufgrund von Lizenzbeschränkungen ein bemerkenswertes Beispiel für letzteres), aber so oder so bleibt eine Kernel-Komponente. Dies ist eine wichtige Grundlage.
Wenn ein Programm aus einer Datei lesen möchte, setzt es verschiedene Systembibliotheksaufrufe ab, die letztendlich in Form eines open() im Kernel landen , read() , close() Sequenz (evtl. mit seek() sicherheitshalber eingeworfen). Der Kernel nimmt den bereitgestellten Pfad und Dateinamen und übersetzt diese über das Dateisystem und die Geräte-E/A-Schicht in physische Leseanforderungen (und in vielen Fällen auch Schreibanforderungen – denken Sie zum Beispiel an Zeitaktualisierungen) an einen zugrunde liegenden Speicher.
Allerdings muss es diese Anforderungen nicht speziell in physisch, persistent übersetzen Speicher . Der Vertrag des Kernels besteht darin, dass das Absetzen dieses bestimmten Satzes von Systemaufrufen den Inhalt der fraglichen Datei bereitstellt . Wo genau in unserem physischen Bereich die "Datei" existiert, ist zweitrangig.
Auf /proc wird normalerweise als procfs gemountet . Das ist ein spezieller Dateisystemtyp, aber da es sich um ein Dateisystem handelt, unterscheidet es sich nicht wirklich von z. ein ext3 Dateisystem irgendwo gemountet. Die Anfrage wird also an den Treibercode des procfs-Dateisystems weitergeleitet, der all diese Dateien und Verzeichnisse kennt und bestimmte Informationen aus den Kernel-Datenstrukturen zurückgibt .
Die "Speicherschicht" sind in diesem Fall die Kernel-Datenstrukturen und procfs bietet eine übersichtliche, bequeme Schnittstelle für den Zugriff auf diese. Denken Sie daran, dass das Mounten von procfs unter /proc erfolgt ist einfach Konvention; Sie könnten es genauso gut woanders montieren. Tatsächlich wird das manchmal gemacht, zum Beispiel in Chroot-Gefängnissen, wenn der dort laufende Prozess aus irgendeinem Grund Zugriff auf /proc benötigt.
Es funktioniert genauso, wenn Sie einen Wert in eine Datei schreiben; auf der Kernel-Ebene bedeutet das eine Reihe von open() , seek() , write() , close() Aufrufe, die wiederum an den Dateisystemtreiber weitergeleitet werden; wieder, in diesem speziellen Fall, der procfs-Code.
Der besondere Grund, warum file angezeigt wird Rückgabe von empty ist, dass viele der Dateien, die von procfs bereitgestellt werden, mit einer Größe von 0 Bytes bereitgestellt werden Die Größe von 0 Byte ist wahrscheinlich eine Optimierung auf der Kernelseite (viele der Dateien in /proc sind dynamisch und können leicht in der Länge variieren, möglicherweise sogar von einem Lesevorgang zum nächsten, und die Berechnung der Länge jeder Datei in jedem gelesenen Verzeichnis würde möglicherweise sehr teuer). Gehen Sie nach den Kommentaren zu dieser Antwort, die Sie auf Ihrem eigenen System überprüfen können, indem Sie strace oder ein ähnliches Tool ausführen, file gibt zuerst einen stat() aus aufrufen, um spezielle Dateien zu erkennen, und nutzt dann die Gelegenheit, um abzubrechen und die Datei als leer zu melden, wenn die Dateigröße als 0 gemeldet wird.
Dieses Verhalten ist tatsächlich dokumentiert und kann durch Angabe von -s überschrieben werden oder --special-files auf der file Aufruf, obwohl, wie in der Handbuchseite angegeben, Nebenwirkungen auftreten können. Das folgende Zitat stammt aus der BSD-Datei 5.11-Manpage vom 17. Oktober 2011.
Normalerweise versucht file nur, den Typ von Argumentdateien zu lesen und zu bestimmen, von denen stat(2) berichtet, dass es sich um gewöhnliche Dateien handelt. Dies vermeidet Probleme, da das Lesen spezieller Dateien besondere Folgen haben kann. Angabe des -s Die Option bewirkt, dass file auch Argumentdateien liest, die spezielle Block- oder Zeichendateien sind. Dies ist nützlich, um die Dateisystemtypen der Daten in Raw-Festplattenpartitionen zu bestimmen, die spezielle Blockdateien sind. Diese Option bewirkt auch, dass file die von stat(2) gemeldete Dateigröße ignoriert da es auf einigen Systemen eine Nullgröße für Raw-Festplattenpartitionen meldet.
In diesem Verzeichnis können Sie steuern, wie der Kernel Geräte betrachtet, Kerneleinstellungen anpassen, Geräte zum Kernel hinzufügen und wieder entfernen. In diesem Verzeichnis können Sie direkt die Speichernutzung und E/A-Statistiken einsehen.
Sie können sehen, welche Festplatten gemountet sind und welche Dateisysteme verwendet werden. Kurz gesagt, jeder einzelne Aspekt Ihres Linux-Systems kann von diesem Verzeichnis aus untersucht werden, wenn Sie wissen, wonach Sie suchen müssen.
Die /proc Verzeichnis ist kein normales Verzeichnis. Wenn Sie von einer Boot-CD booten und sich dieses Verzeichnis auf Ihrer Festplatte ansehen würden, würden Sie sehen, dass es leer ist. Wenn Sie es unter Ihrem normalen laufenden System betrachten, kann es ziemlich groß sein. Es scheint jedoch keinen Festplattenspeicher zu verwenden. Dies liegt daran, dass es sich um ein virtuelles Dateisystem handelt.
Seit /proc Dateisystem ist ein virtuelles Dateisystem und befindet sich im Speicher, ein neuer /proc Dateisystem wird jedes Mal erstellt, wenn Ihr Linux-Rechner neu gestartet wird.
Mit anderen Worten, es ist nur ein Mittel, um über eine Schnittstelle vom Datei- und Verzeichnistyp einfach in die Eingeweide des Linux-Systems hineinzuspähen und zu stochern. Wenn Sie sich eine Datei im /proc Verzeichnis sehen Sie direkt auf einen Speicherbereich im Linux-Kernel und sehen, was er sehen kann.
Die Schichten im Dateisystem
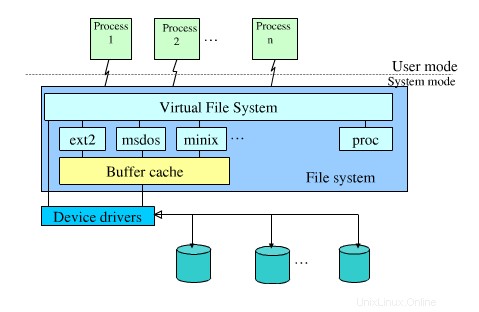
Beispiele:
- In
/proc, gibt es für jeden laufenden Prozess ein Verzeichnis, das nach seiner Prozess-ID benannt ist. Diese Verzeichnisse enthalten Dateien mit nützlichen Informationen zu den Prozessen, z. B.:exe:Dies ist ein symbolischer Link zu der Datei auf der Festplatte, von der aus der Prozess gestartet wurde.cwd:Dies ist ein symbolischer Link zum Arbeitsverzeichnis des Prozesses.wchan:die, wenn sie gelesen wird, den Wartekanal zurückgibt, auf dem sich der Prozess befindet.maps:die, wenn sie gelesen wird, die Speicherzuordnungen des Prozesses zurückgibt.
/proc/uptimegibt die Betriebszeit als zwei Dezimalwerte in Sekunden zurück, getrennt durch ein Leerzeichen:- Die Zeit seit dem Start des Kernels.
- die Zeit, die der Kernel im Leerlauf war.
/proc/interrupts:Für Informationen zu Interrupts./proc/modules:Für eine Liste der Module.
Weitere Informationen finden Sie unter man proc oder kernel.org.
Sie haben Recht, es sind keine echten Dateien.
Einfach ausgedrückt ist es eine Möglichkeit, mit den normalen Methoden zum Lesen und Schreiben von Dateien mit dem Kernel zu kommunizieren, anstatt den Kernel direkt aufzurufen. Es entspricht der Unix-Philosophie „Alles ist eine Datei“.
Die Dateien in /proc existieren physisch nirgendwo, aber der Kernel reagiert auf die Dateien, die Sie darin lesen und schreiben, und anstatt in den Speicher zu schreiben, meldet er Informationen oder tut etwas.
Ebenso die Dateien in /dev sind eigentlich keine Dateien im herkömmlichen Sinne (obwohl auf manchen Systemen die Dateien in /dev möglicherweise tatsächlich auf der Festplatte existieren, haben sie nicht viel anderes als das Gerät, auf das sie sich beziehen) - sie ermöglichen es Ihnen, mit einem Gerät zu sprechen, das die normale Unix-Datei-I/O-API verwendet - oder irgendetwas, das es verwendet, wie Shells