Ja, Linux verwendet Paging, sodass alle Adressen immer virtuell sind. (Um auf den Speicher an einer bekannten physischen Adresse zuzugreifen, hält Linux den gesamten physischen Speicher 1:1 einem Bereich des virtuellen Kernel-Adressraums zugeordnet, sodass es einfach in dieses "Array" indizieren kann, indem die physische Adresse als Offset verwendet wird. Modulo-Komplikationen für 32 -bit-Kernel auf Systemen mit mehr physischem RAM als Kernel-Adressraum.)
Dieser aus Seiten bestehende lineare Adressraum ist in vier Segmente aufgeteilt
Nein, Linux verwendet ein flaches Speichermodell. Die Basis und Grenze für alle 4 dieser Segmentdeskriptoren sind 0 und -1 (unbegrenzt). d.h. sie überlappen sich alle vollständig und decken den gesamten virtuellen linearen 32-Bit-Adressraum ab.
Der rote Teil besteht also aus zwei Segmenten __KERNEL_CS und __KERNEL_DS
Nein, hier haben Sie einen Fehler gemacht. x86-Segmentregister sind nicht wird zur Segmentierung verwendet; Sie sind veraltetes x86-Gepäck, das nur für den CPU-Modus und die Auswahl der Berechtigungsebene auf x86-64 verwendet wird . Anstatt dafür neue Mechanismen hinzuzufügen und Segmente für den Long-Modus vollständig zu entfernen, hat AMD die Segmentierung im Long-Modus einfach kastriert (die Basis ist auf 0 festgelegt, wie sie sowieso alle im 32-Bit-Modus verwenden) und verwendet weiterhin Segmente nur für Maschinenkonfigurationszwecke, die dies nicht sind besonders interessant, es sei denn, Sie schreiben tatsächlich Code, der in den 32-Bit-Modus oder was auch immer wechselt.
(Außer Sie können eine Basis ungleich Null für FS und/oder GS festlegen, und Linux tut dies für Thread-lokale Speicherung. Aber das hat nichts damit zu tun, wie copy_from_user() implementiert ist, oder so etwas. Es muss nur diesen Zeigerwert prüfen, nicht in Bezug auf irgendein Segment oder die CPL/RPL eines Segmentdeskriptors.)
Im 32-Bit-Legacy-Modus ist es möglich, einen Kernel zu schreiben, der ein segmentiertes Speichermodell verwendet, aber keines der Mainstream-Betriebssysteme hat dies tatsächlich getan. Einige Leute wünschten sich, das wäre eine Sache geworden, z. Sehen Sie sich diese Antwort an, in der x86-64 beklagt wird, was ein Betriebssystem im Multics-Stil unmöglich macht. Aber das ist nicht wie Linux funktioniert.
Linux ist ein https://wiki.osdev.org/Higher_Half_Kernel, wo Kernel-Zeiger einen Wertebereich haben (der rote Teil) und User-Space-Adressen sich im grünen Teil befinden. Der Kernel kann Benutzerbereichsadressen einfach dereferenzieren, wenn die richtigen Seitentabellen des Benutzerbereichs zugeordnet sind, er muss sie nicht übersetzen oder irgendetwas mit Segmenten tun; das bedeutet es, ein flaches Speichermodell zu haben . (Der Kernel kann "Benutzer"-Seitentabelleneinträge verwenden, aber nicht und umgekehrt). Speziell für x86-64 siehe https://www.kernel.org/doc/Documentation/x86/x86_64/mm.txt für die tatsächliche Speicherzuordnung.
Der einzige Grund, warum diese 4 GDT-Einträge alle getrennt sein müssen, ist aus Gründen der Berechtigungsebene und dass die Deskriptoren für Daten- und Codesegmente unterschiedliche Formate haben. (Ein GDT-Eintrag enthält mehr als nur Basis/Grenze; das sind die Teile, die unterschiedlich sein müssen. Siehe https://wiki.osdev.org/Global_Descriptor_Table)
Und insbesondere https://wiki.osdev.org/Segmentation#Notes_Regarding_C, das beschreibt, wie und warum die GDT normalerweise von einem "normalen" Betriebssystem verwendet wird, um ein flaches Speichermodell mit einem Paar Code- und Datendeskriptoren für jede Berechtigungsstufe zu erstellen .
Für einen 32-Bit-Linux-Kernel nur gs erhält eine Basis ungleich Null für Thread-lokale Speicherung (also Adressierungsmodi wie [gs: 0x10] greift auf eine lineare Adresse zu, die von dem Thread abhängt, der sie ausführt). Oder in einem 64-Bit-Kernel (und 64-Bit-Benutzerbereich) verwendet Linux fs . (Weil x86-64 GS mit dem swapgs zu etwas Besonderem gemacht hat Anweisung zur Verwendung mit syscall damit der Kernel den Kernel-Stack findet.)
Aber wie auch immer, die Nicht-Null-Basis für FS oder GS stammt nicht aus einem GDT-Eintrag, sie werden mit dem wrgsbase gesetzt Anweisung. (Oder auf CPUs, die das nicht unterstützen, mit einem Schreiben auf eine MSR).
aber was sind das für flags, nämlich 0xc09b , 0xa09b usw ? Ich neige dazu zu glauben, dass sie die Segmentselektoren sind
Nein, Segmentselektoren sind Indizes in der GDT. Der Kernel definiert die GDT als C-Array und verwendet eine Designated-Initialisierer-Syntax wie [GDT_ENTRY_KERNEL32_CS] = initializer_for_that_selector .
(Eigentlich sind die niedrigen 2 Bits eines Selektors, d. h. der Segmentregisterwert, die aktuelle Berechtigungsstufe. Also GDT_ENTRY_DEFAULT_USER_CS sollte `__USER_CS>> 2.)
mov ds, eax löst die Hardware aus, um die GDT zu indizieren, nicht linear nach übereinstimmenden Daten im Speicher zu suchen!
GDT-Datenformat:
Sie sehen sich den x86-64-Linux-Quellcode an, sodass sich der Kernel im Long-Modus befindet, nicht im geschützten Modus. Das erkennen wir daran, dass es separate Einträge für USER_CS gibt und USER32_CS . Der 32-Bit-Codesegmentdeskriptor hat seinen L bisschen gelöscht. Die aktuelle CS-Segmentbeschreibung versetzt eine x86-64-CPU in den 32-Bit-Kompatibilitätsmodus im Vergleich zum 64-Bit-Long-Modus. Um in den 32-Bit-Benutzerbereich einzutreten, ein iret oder sysret setzt CS:RIP auf einen 32-Bit-Segmentselektor im Benutzermodus.
Ich denke Sie können die CPU auch im 16-Bit-Kompatibilitätsmodus haben (wie der Kompatibilitätsmodus, nicht der Realmodus, aber die Standardoperandengröße und Adressgröße sind 16). Linux tut dies jedoch nicht.
Wie auch immer, wie in https://wiki.osdev.org/Global_Descriptor_Table and Segmentation,
erklärtJeder Segmentdeskriptor enthält die folgenden Informationen:
- Die Basisadresse des Segments
- Die Standardoperationsgröße im Segment (16-Bit/32-Bit)
- Die Berechtigungsstufe des Deskriptors (Ring 0 -> Ring 3)
- Die Granularität (Segmentlimit in Byte/4-KB-Einheiten)
- Die Segmentgrenze (Der maximale gesetzliche Versatz innerhalb des Segments)
- Das Vorhandensein des Segments (Ist es vorhanden oder nicht)
- Der Deskriptortyp (0 =System; 1 =Code/Daten)
- Der Segmenttyp (Code/Daten/Lesen/Schreiben/Zugegriffen/Konform/Nicht konform/Erweitern nach oben/Erweitern nach unten)
Dies sind die zusätzlichen Bits. Ich bin nicht besonders daran interessiert, welche Bits welche sind, weil ich (glaube, ich) verstehe das allgemeine Bild davon, wofür verschiedene GDT-Einträge sind und was sie tun, ohne auf die Details einzugehen, wie das tatsächlich codiert ist.
Aber wenn Sie die x86-Handbücher oder das osdev-Wiki und die Definitionen für diese Init-Makros überprüfen, sollten Sie feststellen, dass sie zu einem GDT-Eintrag mit dem L führen Bit gesetzt für 64-Bit-Codesegmente, gelöscht für 32-Bit-Codesegmente. Und offensichtlich unterscheiden sich der Typ (Code vs. Daten) und die Berechtigungsstufe.
Haftungsausschluss
Ich poste diese Antwort, um dieses Thema von Missverständnissen zu befreien (wie von @PeterCordes hervorgehoben).
Paging
Die Speicherverwaltung in Linux (x86-geschützter Modus) verwendet Paging, um die physischen Adressen auf eine virtualisierte flache abzubilden linearer Adressraum, ab 0x00000000 bis 0xFFFFFFFF (auf 32-Bit), bekannt als das flache Speichermodell . Linux verwaltet zusammen mit der MMU (Memory Management Unit) der CPU jede virtuelle und logische Adresse, die 1:1 der entsprechenden physischen Adresse zugeordnet ist. Der physische Speicher ist normalerweise in 4-KiB-Seiten aufgeteilt, um eine einfachere Verwaltung des Speichers zu ermöglichen.
Die virtuellen Kernel-Adressen kann zusammenhängender Kernel logisch sein Adressen, die direkt auf zusammenhängende physische Seiten abgebildet werden; andere virtuelle Kerneladressen sind vollständig virtuelle Adressen, die in nicht zusammenhängenden physischen Seiten abgebildet sind, die für große Pufferzuweisungen (die den zusammenhängenden Bereich auf Systemen mit kleinem Speicher überschreiten) und/oder PAE-Speicher (nur 32 Bit) verwendet werden. MMIO-Ports (Memory-Mapped I/O) werden ebenfalls mithilfe von virtuellen Kerneladressen zugeordnet.
Jede dereferenzierte Adresse muss eine virtuelle Adresse sein. Entweder handelt es sich um eine logische oder eine vollständig virtuelle Adresse, physische RAM- und MMIO-Ports werden vor der Verwendung im virtuellen Adressraum abgebildet.
Der Kernel erhält einen Teil des virtuellen Speichers mit kmalloc() , auf die von einer virtuellen Adresse verwiesen wird, aber was noch wichtiger ist, das ist auch eine logische Kerneladresse, was bedeutet, dass sie eine direkte Zuordnung zu contiguous hat physische Seiten (daher geeignet für DMA). Andererseits die vmalloc() Routine gibt einen Teil von vollständig zurück Virtueller Speicher, auf den durch eine virtuelle Adresse verwiesen wird, der jedoch nur im virtuellen Adressraum zusammenhängend ist und auf nicht zusammenhängende physische Seiten abgebildet wird.
Logische Kerneladressen verwenden eine feste Zuordnung zwischen physischem und virtuellem Adressraum. Dies bedeutet, dass virtuell zusammenhängende Regionen von Natur aus auch physisch zusammenhängend sind. Dies ist bei vollständig virtuellen Adressen nicht der Fall, die auf nicht zusammenhängende physische Seiten verweisen.
Die virtuellen Nutzeradressen - im Gegensatz zu logischen Adressen des Kernels - verwenden Sie keine feste Zuordnung zwischen virtuellen und physischen Adressen, Userland-Prozesse machen vollen Gebrauch von der MMU:
- Nur verwendete Teile des physischen Speichers werden zugeordnet;
- Speicher ist nicht zusammenhängend;
- Speicher kann ausgetauscht werden;
- Speicher kann verschoben werden;
Genauer gesagt werden physische Speicherseiten von 4 KB virtuellen Adressen in der OS-Seitentabelle zugeordnet, wobei jede Zuordnung als PTE (Page Table Entry) bekannt ist. Die MMU der CPU hält dann einen Cache von jedem kürzlich verwendeten PTEs aus der OS-Seitentabelle. Dieser Caching-Bereich ist als TLB (Translation Lookaside Buffer) bekannt. Die cr3 register wird verwendet, um die Seitentabelle des Betriebssystems zu lokalisieren.
Wann immer eine virtuelle Adresse in eine physikalische übersetzt werden muss, wird der TLB durchsucht. Wenn eine Übereinstimmung gefunden wird (TLB Treffer ), wird die physische Adresse zurückgegeben und darauf zugegriffen. Wenn es jedoch keine Übereinstimmung gibt (TLB miss ), schlägt der TLB-Miss-Handler in der Seitentabelle nach, ob eine Zuordnung vorhanden ist (page walk ). Wenn einer existiert, wird er in den TLB zurückgeschrieben und der fehlerhafte Befehl wird neu gestartet, diese nachfolgende Übersetzung findet dann einen TLB-Treffer und der Speicherzugriff wird fortgesetzt. Dies wird als Minor bezeichnet Seitenfehler.
Manchmal muss das Betriebssystem möglicherweise die Größe des physischen Arbeitsspeichers erhöhen, indem Seiten auf die Festplatte verschoben werden. Wenn eine virtuelle Adresse zu einer auf der Festplatte abgebildeten Seite aufgelöst wird, muss die Seite vor dem Zugriff in den physischen RAM geladen werden. Dies wird als Major bezeichnet Seitenfehler. Der Seitenfehler-Handler des Betriebssystems muss dann eine freie Seite im Speicher finden.
Der Übersetzungsprozess kann fehlschlagen, wenn für die virtuelle Adresse keine Zuordnung verfügbar ist, was bedeutet, dass die virtuelle Adresse ungültig ist. Dies wird als ungültig bezeichnet Seitenfehlerausnahme und ein segfault wird vom Seitenfehler-Handler des Betriebssystems an den Prozess ausgegeben.
Speichersegmentierung
Real-Modus
Der Real-Modus verwendet immer noch einen segmentierten 20-Bit-Speicheradressraum mit 1 MB adressierbarem Speicher (0x00000 - 0xFFFFF ) und unbegrenzten direkten Softwarezugriff auf alle adressierbaren Speicher, Busadressen, PMIO-Ports (Port-Mapped I/O) und Peripheriehardware. Der Real-Modus bietet keinen Speicherschutz , keine Berechtigungsstufen und keine virtualisierten Adressen. Typischerweise enthält ein Segmentregister den Segmentselektorwert, und der Speicheroperand ist ein Offsetwert relativ zur Segmentbasis.
Um die Segmentierung zu umgehen (C-Compiler unterstützen normalerweise nur das flache Speichermodell), verwendeten C-Compiler den inoffiziellen far Zeigertyp zur Darstellung einer physikalischen Adresse mit einem segment:offset logische Adressschreibweise. Zum Beispiel die logische Adresse 0x5555:0x0005 , nach der Berechnung von 0x5555 * 16 + 0x0005 ergibt die physikalische 20-Bit-Adresse 0x55555 , verwendbar in einem Far-Zeiger, wie unten gezeigt:
char far *ptr; /* declare a far pointer */
ptr = (char far *)0x55555; /* initialize a far pointer */
Stand heute starten die meisten modernen x86-CPUs aus Gründen der Abwärtskompatibilität immer noch im Real-Modus und wechseln danach in den geschützten Modus.
Geschützter Modus
Im geschützten Modus mit dem flachen Speichermodell , wird die Segmentierung nicht verwendet . Die vier Segmente, nämlich __KERNEL_CS , __KERNEL_DS , __USER_CS , __USER_DS Alle haben ihre Basisadressen auf 0 gesetzt. Diese Segmente sind nur Altlasten des früheren x86-Modells, bei dem segmentierte Speicherverwaltung verwendet wurde. Da im geschützten Modus alle Basisadressen der Segmente auf 0 gesetzt sind, sind logische Adressen äquivalent zu linearen Adressen.
Der geschützte Modus mit dem flachen Speichermodell bedeutet keine Segmentierung. Die einzige Ausnahme, bei der die Basisadresse eines Segments auf einen anderen Wert als 0 gesetzt ist, ist der Thread-lokale Speicher. Der FS (und GS auf 64-Bit) werden hierfür Segmentregister verwendet.
Segmentregister wie SS jedoch (Stapelsegmentregister), DS (Datensegmentregister) oder CS (Codesegmentregister) sind noch vorhanden und werden zum Speichern von 16-Bit-Segment-Selektoren verwendet , die Indizes für Segment-Deskriptoren enthalten in der LDT und GDT (Local &Global Descriptor Table).
Jede Anweisung, die den Speicher implizit berührt verwendet ein Segmentregister. Je nach Kontext wird ein bestimmtes Segmentregister verwendet. Zum Beispiel JMP Anweisung verwendet CS während PUSH verwendet SS . Selektoren können mit Anweisungen wie MOV in Register geladen werden , wobei die einzige Ausnahme der CS ist Register, das nur durch Befehle modifiziert wird, die den Ablauf der Ausführung beeinflussen , wie CALL oder JMP .
Die CS register ist besonders nützlich, da es die CPL (Current Privilege Level) in seinem Segmentselektor verfolgt und somit die Privilegstufe für das aktuelle Segment bewahrt. Dieser 2-Bit-CPL-Wert ist immer entspricht der aktuellen Berechtigungsstufe der CPU.
Speicherschutz
Paging
Die CPU-Berechtigungsebene, auch als Modusbit oder Schutzring bekannt , von 0 bis 3, schränkt einige Anweisungen ein, die den Schutzmechanismus untergraben oder Chaos verursachen können, wenn sie im Benutzermodus erlaubt sind, sodass sie dem Kernel vorbehalten sind. Ein Versuch, sie außerhalb von Ring 0 auszuführen, führt zu einem allgemeinen Schutz Fehlerausnahme, dasselbe Szenario, wenn ein ungültiger Segmentzugriffsfehler auftritt (Privileg, Typ, Limit, Lese-/Schreibrechte). Ebenso ist jeder Zugriff auf Speicher und MMIO-Geräte basierend auf der Berechtigungsebene eingeschränkt, und jeder Versuch, auf eine geschützte Seite ohne die erforderliche Berechtigungsebene zuzugreifen, führt zu einer Seitenfehlerausnahme.
Das Modus-Bit wird bei jeder Unterbrechungsanforderung automatisch vom Benutzermodus in den Supervisor-Modus umgeschaltet (IRQ), entweder Software (z. B. syscall ) oder Hardware, auftritt.
Auf einem 32-Bit-System können nur 4 GiB Speicher effektiv adressiert werden, und der Speicher wird in einer 3-GiB/1-GiB-Form aufgeteilt. Linux (mit aktiviertem Paging) verwendet ein Schutzschema, das als Higher Half Kernel bekannt ist wobei der flache Adressraum in zwei Bereiche virtueller Adressen unterteilt ist:
-
Adressen im Bereich
0xC0000000 - 0xFFFFFFFFsind virtuelle Kerneladressen (roter Bereich). Der 896-MiB-Bereich0xC0000000 - 0xF7FFFFFFordnet die logischen Adressen des Kernels 1:1 direkt den physikalischen Adressen des Kernels in den zusammenhängenden Low-Memory zu Seiten (mit dem__pa()und__va()Makros). Die verbleibenden 128 MiB reichen von0xF8000000 - 0xFFFFFFFFwird dann verwendet, um virtuelle Adressen für große Pufferzuweisungen, MMIO-Ports (Memory-Mapped I/O) und/oder PAE-Speicher in den nicht zusammenhängenden High-Memory abzubilden Seiten (mitioremap()undiounmap()). -
Adressen im Bereich
0x00000000 - 0xBFFFFFFFsind virtuelle Benutzeradressen (grüner Bereich), wo Userland Code, Daten und Bibliotheken liegen. Die Zuordnung kann in nicht zusammenhängenden Low-Memory- und High-Memory-Seiten erfolgen.
High-Memory ist nur auf 32-Bit-Systemen vorhanden. Der gesamte Speicher wird mit kmalloc() zugewiesen hat eine logische virtuelle Adresse (mit direkter physikalischer Zuordnung); Speicher allokiert durch vmalloc() hat ein vollständig virtuelle Adresse (aber keine direkte physikalische Zuordnung). 64-Bit-Systeme haben eine enorme Adressierungskapazität und benötigen daher keinen hohen Arbeitsspeicher, da jede Seite des physischen RAM effektiv adressiert werden kann.
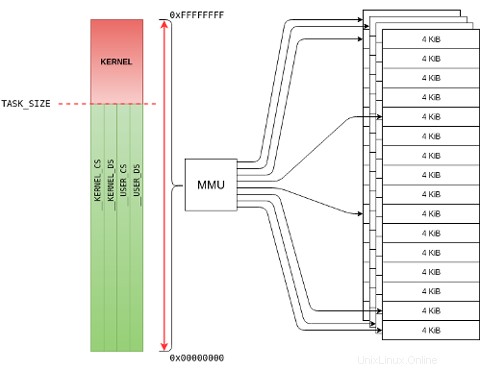
Die Grenze Die Adresse zwischen der höheren Hälfte des Supervisors und der unteren Hälfte des Userlands ist als TASK_SIZE_MAX bekannt im Linux-Kernel. Der Kernel überprüft, ob jede virtuelle Adresse, auf die von einem Userland-Prozess zugegriffen wird, unterhalb dieser Grenze liegt, wie im folgenden Code zu sehen ist:
static int fault_in_kernel_space(unsigned long address)
{
/*
* On 64-bit systems, the vsyscall page is at an address above
* TASK_SIZE_MAX, but is not considered part of the kernel
* address space.
*/
if (IS_ENABLED(CONFIG_X86_64) && is_vsyscall_vaddr(address))
return false;
return address >= TASK_SIZE_MAX;
}
Wenn ein Userland-Prozess versucht, auf eine Speicheradresse höher als TASK_SIZE_MAX zuzugreifen , der do_kern_addr_fault() Routine ruft __bad_area_nosemaphore() auf Routine, die schließlich die fehlerhafte Aufgabe mit einem SIGSEGV signalisiert (mit get_current() um den task_struct zu erhalten ):
/*
* To avoid leaking information about the kernel page table
* layout, pretend that user-mode accesses to kernel addresses
* are always protection faults.
*/
if (address >= TASK_SIZE_MAX)
error_code |= X86_PF_PROT;
force_sig_fault(SIGSEGV, si_code, (void __user *)address, tsk); /* Kill the process */
Seiten haben auch ein Privileg-Bit, das als U bekannt ist ser/Supervisor-Flag, das zusätzlich zum R für SMAP (Supervisor Mode Access Prevention) verwendet wird Lese-/Schreib-Flag, das SMEP (Supervisor Mode Execution Prevention) verwendet.
Segmentierung
Ältere Architekturen, die Segmentierung verwenden, führen normalerweise eine Überprüfung des Segmentzugriffs unter Verwendung des GDT-Berechtigungsbits für jedes angeforderte Segment durch. Das Privilegbit des angeforderten Segments, bekannt als DPL (Descriptor Privilege Level), wird mit dem CPL des aktuellen Segments verglichen, wodurch sichergestellt wird, dass CPL <= DPL . Wenn wahr, wird der Speicherzugriff auf das angeforderte Segment erlaubt.