TL;DR
UTF-8 MIT BOM kann auch Probleme verursachen.
PROBLEM
Ich hatte gerade das gleiche Problem und habe viele mögliche Lösungen ausprobiert, aber keine davon hat funktioniert, bis ich die Ursache des Problems herausgefunden habe, was ein bisschen lustig war. Ich weiß, dass diese Frage bereits beantwortet wurde, aber ich schreibe meine Lösung auf, vielleicht löst sie das Problem von jemand anderem, der das gleiche Problem hat.
Ich habe zum Beispiel "Bezeichner-Vektor konnte nicht aufgelöst werden" bei der Definition von struct Vector , obwohl es richtig war:
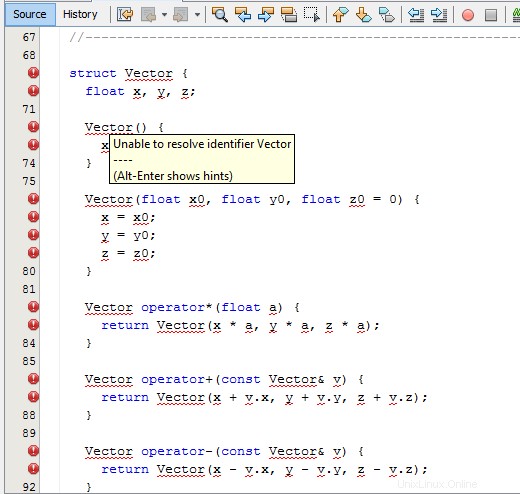
Ich habe viele ähnliche Fehler beim Deklarieren/Definieren von Funktionen usw. erhalten. Außerdem funktionierte meine Codeunterstützung aufgrund der Menge an Fehlern nicht.
LÖSUNG
-
Ich habe die
.cppgeöffnet Datei in Notepad++ , und sah, dass die Datei in regulärem UTF-8 codiert war , was bedeutet, dass die Datei mit dem Zeichen Byte Order Mark (BOM) beginnt :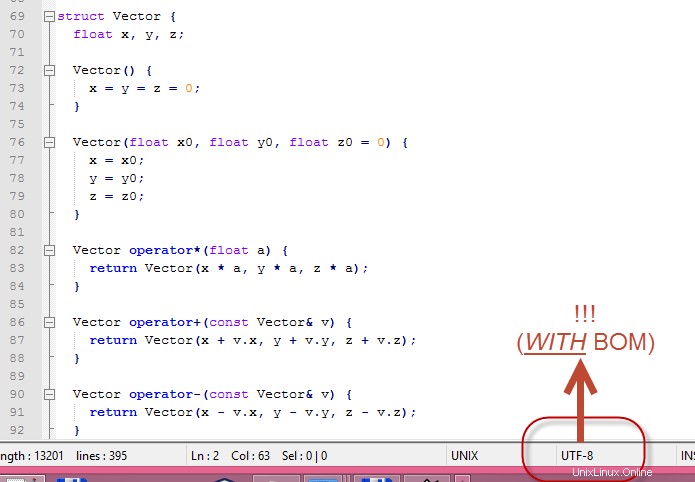
-
Also habe ich auf Encoding geklickt → In UTF-8 ohne BOM konvertieren :
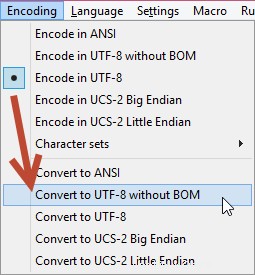
Hinweis: Wechseln Sie NICHT einfach zu "Encode in UTF-8 without BOM" , weil es einige Sonderzeichen durcheinander bringen kann (z. B. Zeichen mit Akzenten usw.). Also umwandeln es.
-
Speichern
-
Problem behoben:keine Fehler mehr in NetBeans gemeldet:

Ich hoffe, es spart auch jemand anderem etwas Zeit.
Hier ist ein Auszug aus meiner Antwort auf eine andere Frage.
Unaufgelöste Kennung
Wenn die Quelle der .cpp-Datei so aussieht

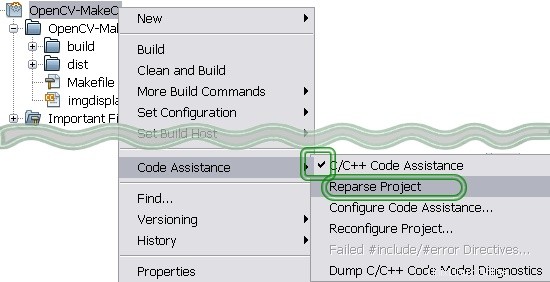
Klicken Sie mit der rechten Maustaste auf Ihr Projekt.
Kreuzen Sie C/C++ Code As... an
Führen Sie Reparse Project. aus
Wenn das nicht reicht.
Gehen Sie zu Project Properties
Füllen Sie Include aus Eingabefeld wie beschrieben.
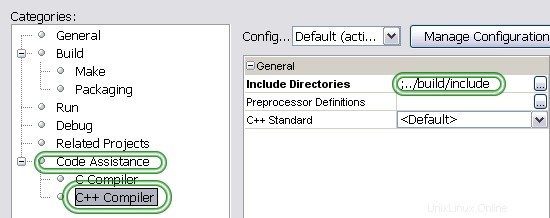
Stellen Sie den Include-Pfad korrekt ein.
Ich hoffe, das kann Ihnen helfen.
Ich hatte das gleiche Problem, aber ich erkannte, dass es erscheint, nachdem ich Eigenschaften -> c++ Compiler -> Compilation Line -> zusätzliche Optionen in -std=c++11 geändert habe. Wenn Sie die Einstellungen auf die Standardeinstellungen ändern, verschwindet der Fehler "ID kann nicht aufgelöst werden".