Im ersten Teil der Artikelreihe zu Linux-Prozessen bauen wir das Verständnis für Linux-Prozesse auf, indem wir über die main()-Funktion und umgebungsbezogene C-Funktionen sprechen.
In diesem Artikel besprechen wir das Speicherlayout eines Prozesses und den Prozess, der C-Funktionen beendet.
Linux Processes Series:Teil 1, Teil 2 (dieser Artikel), Teil 3
Speicherlayout eines Prozesses
Das Speicherlayout eines Prozesses unter Linux kann sehr kompliziert sein, wenn wir versuchen, alles im Detail darzustellen und zu beschreiben. Deshalb werden wir hier nur die Dinge präsentieren, die von erheblicher Bedeutung sind.
Wenn wir versuchen, das Speicherlayout eines Prozesses zu visualisieren, haben wir so etwas:
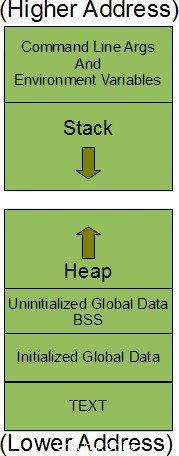
Lassen Sie uns jede Komponente des obigen Layouts einzeln erklären:
- Die Befehlszeilenargumente und die Umgebungsvariablen werden oben im Prozessspeicherlayout an den höheren Adressen gespeichert.
- Dann kommt das Stack-Segment. Dies ist der Speicherbereich, der vom Prozess verwendet wird, um die lokalen Funktionsvariablen und andere Informationen zu speichern, die bei jedem Aufruf einer Funktion gespeichert werden. Diese anderen Informationen umfassen die Rücksprungadresse, dh die Adresse, von der aus die Funktion aufgerufen wurde, einige Informationen über die Umgebung des Aufrufers wie seine Maschinenregister usw. werden auf dem Stapel gespeichert. Erwähnenswert ist hier auch, dass jedes Mal, wenn eine rekursive Funktion aufgerufen wird, ein neuer Stack-Frame generiert wird, so dass jeder Satz lokaler Variablen keinen anderen Satz stört.
- Heap-Segment ist dasjenige, das für die dynamische Speicherzuweisung verwendet wird. Dieses Segment ist nicht auf einen einzelnen Prozess beschränkt, sondern wird von allen im System laufenden Prozessen gemeinsam genutzt. Jeder Prozess könnte Speicher aus diesem Segment dynamisch zuweisen. Da dieses Segment von den Prozessen gemeinsam genutzt wird, sollte Speicher aus diesem Segment vorsichtig verwendet und freigegeben werden, sobald der Prozess diesen Speicher verwendet.
- Wie aus der obigen Abbildung hervorgeht, wächst der Stapel nach unten, während der Haufen nach oben wächst.
- Alle globalen Variablen, die nicht im Programm initialisiert werden, werden im BSS-Segment gespeichert. Bei der Ausführung werden alle nicht initialisierten globalen Variablen mit dem Wert Null initialisiert. Beachten Sie, dass BSS für „Block Started by Symbol“ steht.
- Alle initialisierten globalen Variablen werden im Datensegment gespeichert.
- Das Textsegment schließlich ist der Speicherbereich, der die Maschinenanweisungen enthält, die die CPU ausführt. Normalerweise wird dieses Segment von verschiedenen Instanzen desselben ausgeführten Programms gemeinsam genutzt. Da es keinen Sinn macht, die CPU-Anweisungen zu ändern, hat dieses Segment nur Leserechte.
Bitte beachten Sie, dass die obige Abbildung nur eine logische Darstellung des Speicherlayouts ist. Es gibt keine Garantie dafür, dass das Speicherlayout eines Prozesses auf einem bestimmten System so aussehen würde. Daneben gibt es auch mehrere andere Segmente für Symboltabellen, Debugging-Informationen usw..
Prozessbeendende Funktionen exit() und _exit()
Die folgenden Funktionen können dazu führen, dass ein Prozess beendet wird:
- exit(status) (dasselbe wie Rückgabestatus )
- _exit(status) oder _Exit(status)
Der Unterschied zwischen der exit()-Funktion und der _exit()-Funktion besteht darin, dass erstere eine gewisse Bereinigung unterstützt, bevor sie die Kontrolle an den Kernel zurückgibt, während die anderen beiden Funktionen sofort an den Kernel zurückkehren.
Die Funktion _exit wird von POSIX spezifiziert, während _Exit von ISO C spezifiziert wird. Abgesehen davon gibt es keinen weiteren wesentlichen Unterschied zwischen den beiden.
Wie bereits oben besprochen, ist die Bereinigung der Hauptunterschied zwischen exit() und _exit(). Bevor wir dies praktisch beweisen, wollen wir uns mit einer anderen Funktion „atexit()“ vertraut machen.
Es folgt der Prototyp :
int atexit(void (*function)(void));
Wie der Name schon sagt, ist dies ein Systemaufruf, der einen Funktionszeiger nimmt und diese bestimmte Funktion als Bereinigungsfunktion für dieses Programm registriert. Das bedeutet, dass die registrierte Funktion immer dann aufgerufen wird, wenn ein Prozess normal beendet wird und die Prozessbeendigung die Bereinigung unterstützt.
Wenn Sie die letzte Zeile des obigen Absatzes noch einmal durchgehen, werden Sie sehen, dass die Funktion „atexit“ ein Teil des Bereinigungsprozesses ist, der zwischen den Funktionen exit() und _exit() unterscheidet. Hier ist also ein Code, der die Funktionen atexit() und exit() verwendet..
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
extern char **environ;
void exitfunc(void)
{
printf("\n Clean-up function called\n");
}
int main(int argc, char *argv[])
{
int count = 0;
atexit(exitfunc);
printf("\n");
while(environ[count++] != NULL)
{
// Dos some stuff
}
exit(0);
} Im obigen Code wird die Funktion „exitfunc()“ mithilfe der Funktion atexit() als Bereinigungsfunktion im Kernel registriert.
Wenn der obige Code ausgeführt wird:
$ ./environ Clean-up function called
Wir sehen, dass die Bereinigungsfunktion aufgerufen wurde.
IF ändern wir den Aufruf von exit() im obigen Code zu _exit() :
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
extern char **environ;
void exitfunc(void)
{
printf("\n Clean-up function called\n");
}
int main(int argc, char *argv[])
{
int count = 0;
atexit(exitfunc);
printf("\n");
while(environ[count++] != NULL)
{
// Dos some stuff
}
_exit(0);
} Wenn wir dieses Programm ausführen, sehen wir :
$ ./environ $
Wir sehen also, dass diesmal die Bereinigungsfunktion ‚exitfunc()‘ nicht aufgerufen wurde, was den Unterschied zwischen den Funktionen exit() und _exit() zeigt.