Wenn Sie ein Textverarbeitungsprogramm verwenden, sollte es kein Problem sein, Text so zu formatieren, dass die Zeilen in den verfügbaren Platz auf dem Zielgerät passen. Doch bei der Arbeit am Terminal ist das nicht so einfach.
Natürlich können Sie Zeilen mit Ihrem bevorzugten Texteditor jederzeit von Hand umbrechen, aber dies ist selten wünschenswert und kommt für eine automatisierte Verarbeitung sogar nicht in Frage.
Hoffentlich fold die POSIX Dienstprogramm und das GNU/BSD fmt Der Befehl kann Ihnen dabei helfen, einen Text umzufließen, sodass die Zeilen eine bestimmte Länge nicht überschreiten.
Was ist noch mal eine Linie in Unix?
Bevor wir auf die Details der fold eingehen und fmt Befehle, lassen Sie uns zuerst definieren, wovon wir sprechen. In einer Textdatei besteht eine Zeile aus einer beliebigen Anzahl von Zeichen, gefolgt von der speziellen Zeilenumbruch-Steuersequenz (manchmal EOL genannt, für Zeilenende )
Auf Unix-ähnlichen Systemen besteht die Zeilenende-Steuersequenz aus dem (einzigen) Zeichen Zeilenvorschub , manchmal abgekürzt LF oder geschrieben \n nach einer von der C-Sprache geerbten Konvention. Auf binärer Ebene wird das Zeilenvorschubzeichen als ein Byte dargestellt, das den 0a enthält Hexadezimalwert.
Das kannst du ganz einfach mit dem hexdump überprüfen Dienstprogramm, das wir in diesem Artikel häufig verwenden werden. Das könnte also eine gute Gelegenheit sein, sich mit diesem Tool vertraut zu machen. Sie können beispielsweise die folgenden hexadezimalen Dumps untersuchen, um herauszufinden, wie viele Zeilenumbrüche von jedem Echo-Befehl gesendet wurden. Wenn Sie glauben, die Lösung gefunden zu haben, wiederholen Sie diese Befehle einfach ohne | hexdump -C Teil, um zu sehen, ob Sie richtig geraten haben.
sh$ echo hello | hexdump -C
00000000 68 65 6c 6c 6f 0a |hello.|
00000006
sh$ echo -n hello | hexdump -C
00000000 68 65 6c 6c 6f |hello|
00000005
sh$ echo -e 'hello\n' | hexdump -C
00000000 68 65 6c 6c 6f 0a 0a |hello..|
00000007
Erwähnenswert ist an dieser Stelle, dass unterschiedliche Betriebssysteme unterschiedliche Regeln bezüglich der Zeilenumbrüche befolgen können. Wie wir oben gesehen haben, verwenden Unix-ähnliche Betriebssysteme den Zeilenvorschub Zeichen, aber Windows verwendet, wie die meisten Internetprotokolle, zwei Zeichen:den Wagenrücklauf+Zeilenvorschub Paar (CRLF oder 0d 0a , oder \r\n ). Unter dem „klassischen“ Mac OS (bis einschließlich MacOS 9.2 in den frühen 2000er Jahren) verwendeten Apple-Computer nur das CR als Zeilenumbruchzeichen. Andere ältere Computer verwendeten auch das LFCR-Paar oder sogar völlig andere Bytefolgen im Fall älterer ASCII-inkompatibler Systeme. Glücklicherweise sind letztere Relikte der Vergangenheit, und ich bezweifle, dass Sie heute noch einen EBCDIC-Computer sehen werden!
Apropos Geschichte, wenn Sie neugierig sind, geht die Verwendung der Steuerzeichen „Wagenrücklauf“ und „Zeilenvorschub“ auf den Baudot-Code zurück, der in der Teletyp-Ära verwendet wurde. Vielleicht haben Sie Fernschreiber in alten Filmen als Schnittstelle zu einem zimmergroßen Computer gesehen. Aber auch davor wurden Fernschreiber „standalone“ für die Punkt-zu-Punkt- oder Mehrpunktkommunikation verwendet. Zu dieser Zeit sah ein typisches Terminal aus wie eine schwere Schreibmaschine mit mechanischer Tastatur, Papier und einem beweglichen Schlitten, der den Druckkopf hielt. Um eine neue Zeile zu beginnen, muss der Wagen wieder ganz nach links gebracht werden, und das Papier muss sich nach oben bewegen, indem die Walze (manchmal auch als „Zylinder“ bezeichnet) gedreht wird. Diese beiden Bewegungen wurden von zwei unabhängigen elektromechanischen Systemen gesteuert, wobei die Steuerzeichen für Zeilenvorschub und Wagenrücklauf direkt mit diesen beiden Teilen des Geräts verbunden waren. Da das Bewegen des Wagens mehr Zeit in Anspruch nimmt als das Drehen der Walze, war es logisch, zuerst den Wagenrücklauf einzuleiten. Die Trennung der beiden Funktionen hatte auch ein paar interessante Nebeneffekte, wie das Ermöglichen des Überdruckens (indem nur das CR gesendet wird) oder die effiziente Übertragung von „Double Interline“ (ein CR + zwei LF).
Die Definition am Anfang dieses Abschnitts beschreibt hauptsächlich, was eine logische Linie ist. Meistens muss diese „beliebig lange“ logische Leitung jedoch auf einem physischen gesendet werden Gerät wie ein Bildschirm oder ein Drucker, wo der verfügbare Platz begrenzt ist. Das Anzeigen kurzer logischer Leitungen auf einem Gerät mit größeren physikalischen Leitungen ist kein Problem. Rechts neben dem Text ist einfach ungenutzter Platz. Was aber, wenn Sie versuchen, eine Textzeile anzuzeigen, die größer ist als der verfügbare Platz auf dem Gerät? Eigentlich gibt es zwei Lösungen, jede mit ihren Nachteilen:
- Erstens kann das Gerät abschneiden die Zeilen in ihrer physischen Größe, wodurch ein Teil des Inhalts für den Benutzer verborgen wird. Einige Drucker machen das, besonders dumme Drucker (und ja, es gibt heute noch einfache Nadeldrucker, besonders in rauen oder schmutzigen Umgebungen!)
- Die zweite Möglichkeit, lange logische Zeilen darzustellen, besteht darin, sie auf mehrere physische Zeilen aufzuteilen. Dies wird Zeilenumbruch genannt weil sich Linien um den verfügbaren Platz zu wickeln scheinen, ein Effekt, der besonders sichtbar ist, wenn Sie die Größe der Anzeige ändern können, wie wenn Sie mit einem Terminal-Emulator arbeiten.
Diese automatischen Verhaltensweisen sind sehr nützlich, aber es gibt immer noch Zeiten, in denen Sie lange Zeilen an einer bestimmten Position unabhängig von der physischen Größe des Geräts unterbrechen möchten. Dies kann beispielsweise nützlich sein, weil Sie möchten, dass die Zeilenumbrüche sowohl auf dem Bildschirm als auch auf dem Drucker an derselben Position erfolgen. Oder weil Sie möchten, dass Ihr Text in einer Anwendung verwendet wird, die keinen Zeilenumbruch durchführt (z. B. wenn Sie Text programmgesteuert in eine SVG-Datei einbetten). Schließlich, ob Sie es glauben oder nicht, gibt es immer noch viele Kommunikationsprotokolle, die eine maximale Zeilenbreite in den Übertragungen vorschreiben, einschließlich populärer wie IRC und SMTP (wenn Sie jemals den Fehler 550 Maximum line length überschritten gesehen haben, wissen Sie, was ich bin sprechen über). Es gibt also viele Gelegenheiten, bei denen Sie lange Leinen in kleinere Stücke brechen müssen. Dies ist die Aufgabe des POSIX fold Befehl.
Der Fold-Befehl
Bei Verwendung ohne Option wird fold Der Befehl fügt zusätzliche Steuersequenzen für Zeilenumbrüche hinzu, um sicherzustellen, dass keine Zeile die Grenze von 80 Zeichen überschreitet. Nur um es klarzustellen, eine Zeile enthält höchstens 80 Zeichen plus die Zeilenumbruchsequenz.
Wenn Sie das Supportmaterial für diesen Artikel heruntergeladen haben, können Sie das selbst ausprobieren:
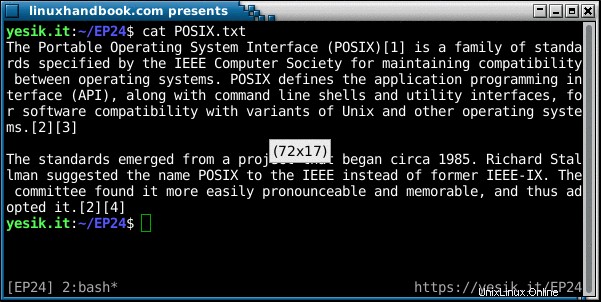
sh$ fold POSIX.txt | head -5
The Portable Operating System Interface (POSIX)[1] is a family of standards spec
ified by the IEEE Computer Society for maintaining compatibility between operati
ng systems. POSIX defines the application programming interface (API), along wit
h command line shells and utility interfaces, for software compatibility with va
riants of Unix and other operating systems.[2][3]
# Using AWK to prefix each line by its length:
sh$ fold POSIX.txt | awk '{ printf("%3d %s\n", length($0), $0) }'
80 The Portable Operating System Interface (POSIX)[1] is a family of standards spec
80 ified by the IEEE Computer Society for maintaining compatibility between operati
80 ng systems. POSIX defines the application programming interface (API), along wit
80 h command line shells and utility interfaces, for software compatibility with va
49 riants of Unix and other operating systems.[2][3]
0
80 The standards emerged from a project that began circa 1985. Richard Stallman sug
80 gested the name POSIX to the IEEE instead of former IEEE-IX. The committee found
71 it more easily pronounceable and memorable, and thus adopted it.[2][4]
Sie können die maximale Ausgabezeilenlänge ändern, indem Sie das -w verwenden Möglichkeit. Interessanter ist wohl die Verwendung des -s Option, um sicherzustellen, dass Zeilen an einer Wortgrenze umbrechen. Vergleichen wir das Ergebnis ohne und mit dem -s Option, wenn sie auf den zweiten Absatz unseres Beispieltextes angewendet wird:
# Without `-s` option: fold will break lines at the specified position
# Broken lines have exactly the required width
sh$ awk -vRS='' 'NR==2' POSIX.txt |
fold -w 30 | awk '{ printf("%3d %s\n", length($0), $0) }'
30 The standards emerged from a p
30 roject that began circa 1985.
30 Richard Stallman suggested the
30 name POSIX to the IEEE instea
30 d of former IEEE-IX. The commi
30 ttee found it more easily pron
30 ounceable and memorable, and t
21 hus adopted it.[2][4]
# With `-s` option: fold will break lines at the last space before the specified position
# Broken lines are shorter or equal to the required width
awk -vRS='' 'NR==2' POSIX.txt |
fold -s -w 30 | awk '{ printf("%3d %s\n", length($0), $0) }'
29 The standards emerged from a
25 project that began circa
23 1985. Richard Stallman
28 suggested the name POSIX to
27 the IEEE instead of former
29 IEEE-IX. The committee found
29 it more easily pronounceable
24 and memorable, and thus
17 adopted it.[2][4]
Wenn Ihr Text Wörter enthält, die länger als die maximale Zeilenlänge sind, kann der fold-Befehl natürlich das -s nicht berücksichtigen Flagge. In diesem Fall fold Dienstprogramm bricht übergroße Wörter an der maximalen Position um und stellt immer sicher, dass keine Zeile die maximal zulässige Breite überschreitet.
sh$ echo "It's Supercalifragilisticexpialidocious!" | fold -sw 10
It's
Supercalif
ragilistic
expialidoc
ious!Multibyte-Zeichen
Wie die meisten, wenn nicht alle Kerndienstprogramme, ist fold Befehl wurde zu einem Zeitpunkt entworfen, an dem ein Zeichen einem Byte entsprach. Dies ist jedoch im modernen Computing nicht mehr der Fall, insbesondere mit der weit verbreiteten Einführung von UTF-8. Etwas, das zu unglücklichen Problemen führt:
# Just in case, check first the relevant locale
# settings are properly defined
debian-9.4$ locale | grep LC_CTYPE
LC_CTYPE="en_US.utf8"
# Everything is OK, unfortunately...
debian-9.4$ echo élève | fold -w2
é
l�
�v
e
Das Wort „élève“ (das französische Wort für „Student“) enthält zwei akzentuierte Buchstaben:é (Lateinischer Kleinbuchstabe E mit Akut) und è (Lateinischer Kleinbuchstabe E mit Grab). Unter Verwendung des UTF-8-Zeichensatzes werden diese Buchstaben mit jeweils zwei Bytes codiert (bzw. c3 a9 und c3 a8 ), statt nur einem Byte, wie es bei lateinischen Buchstaben ohne Akzent der Fall ist. Sie können dies überprüfen, indem Sie die rohen Bytes mit hexdump untersuchen Nützlichkeit. Sie sollten in der Lage sein, die dem é entsprechenden Bytefolgen zu lokalisieren und è Figuren. Übrigens können Sie in diesem Dump unseres alten Freundes auch das Zeilenvorschubzeichen sehen, dessen Hexadezimalcode bereits erwähnt wurde:
debian-9.4$ echo élève | hexdump -C
00000000 c3 a9 6c c3 a8 76 65 0a |..l..ve.|
00000008Sehen wir uns nun die Ausgabe an, die der Befehl fold erzeugt:
debian-9.4$ echo élève | fold -w2
é
l�
�v
e
debian-9.4$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
Offensichtlich das Ergebnis von fold Der Befehl ist aufgrund der zusätzlichen Zeilenumbrüche etwas länger als die ursprüngliche Zeichenfolge:jeweils 11 Bytes lang und 8 Bytes lang, einschließlich der Zeilenumbrüche. Apropos, in der Ausgabe von fold Befehl haben Sie vielleicht den Zeilenvorschub gesehen (0a ) Zeichen, das alle zwei Bytes erscheint. Und genau das ist das Problem:Der fold-Befehl brach Zeilen bei Byte Positionen, nicht bei Zeichen Positionen. Auch wenn dieser Bruch mitten in einem Multi-Byte-Zeichen auftritt! Es muss nicht erwähnt werden, dass die resultierende Ausgabe kein gültiger UTF-8-Bytestrom mehr ist, daher die Verwendung des Unicode-Ersatzzeichens (� ) von meinem Terminal als Platzhalter für die ungültigen Bytefolgen.
Wie beim cut Befehl, den ich vor ein paar Wochen geschrieben habe, ist dies eine Einschränkung in der GNU-Implementierung des fold Nützlichkeit und dies steht eindeutig im Widerspruch zu den POSIX-Spezifikationen, die ausdrücklich besagen, dass „Eine Linie darf nicht in der Mitte eines Zeichens unterbrochen werden.“
Es scheint also das GNU fold zu sein Die Implementierung verarbeitet nur Ein-Byte-Zeichencodierungen mit fester Länge (US-ASCII, Latin1 usw.) ordnungsgemäß. Wenn ein geeigneter Zeichensatz vorhanden ist, können Sie als Problemumgehung Ihren Text vor der Verarbeitung in eine Ein-Byte-Zeichencodierung umcodieren und ihn anschließend wieder in UTF-8 umcodieren. Dies ist jedoch, gelinde gesagt, umständlich:
debian-9.4$ echo élève |
iconv -t latin1 | fold -w 2 |
iconv -f latin1 | hexdump -C
00000000 c3 a9 6c 0a c3 a8 76 0a 65 0a |..l...v.e.|
0000000a
debian-9.4$ echo élève |
iconv -t latin1 | fold -w 2 |
iconv -f latin1
él
èv
e
Da das alles ziemlich enttäuschend war, beschloss ich, das Verhalten anderer Implementierungen zu überprüfen. Wie so oft ist die OpenBSD-Implementierung des fold Das Dienstprogramm ist in dieser Hinsicht viel besser, da es POSIX-kompatibel ist und den LC_CTYPE berücksichtigt Gebietsschema-Einstellung, um Multi-Byte-Zeichen korrekt zu verarbeiten:
openbsd-6.3$ locale | grep LC_CTYPE
LC_CTYPE=en_US.UTF-8
openbsd-6.3$ echo élève | fold -w 2 C
él
èv
e
openbsd-6.3$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 6c 0a c3 a8 76 0a 65 0a |..l...v.e.|
0000000aWie Sie sehen können, schneidet die OpenBSD-Implementierung Zeilen bei Zeichen korrekt ab Positionen, unabhängig von der Anzahl der Bytes, die zu ihrer Codierung benötigt werden. In der überwältigenden Mehrheit der Anwendungsfälle ist dies das, was Sie wollen. Wenn Sie jedoch das Legacy-Verhalten (d. h. im GNU-Stil) benötigen, bei dem ein Byte als ein Zeichen betrachtet wird, können Sie die aktuelle Locale vorübergehend auf die sogenannte POSIX-Locale ändern (gekennzeichnet durch die Konstante „POSIX“ oder aus historischen Gründen „C “):
openbsd-6.3$ echo élève | LC_ALL=C fold -w 2
é
l�
�v
e
openbsd-6.3$ echo élève | LC_ALL=C fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
Schließlich spezifiziert POSIX das -b Flag, das das fold anweist Dienstprogramm zum Messen der Zeilenlänge in Bytes , garantiert aber dennoch Multibyte-Zeichen (nach aktuellem LC_CTYPE Gebietsschemaeinstellungen) werden nicht kaputt sein.
Als Übung empfehle ich Ihnen dringend, sich die Zeit zu nehmen, die erforderlich ist, um die Unterschiede auf Byte-Ebene zwischen dem Ergebnis zu finden, das durch Ändern des aktuellen Gebietsschemas in „C“ (oben) erhalten wird, und dem Ergebnis, das durch Verwenden des -b Flagge statt (unten). Es kann subtil sein. Aber es ist ein Unterschied:
openbsd-6.3$ echo élève | fold -b -w 2 | hexdump -C
00000000 c3 a9 0a 6c 0a c3 a8 0a 76 65 0a |...l....ve.|
0000000bHast du den Unterschied gefunden?
Nun, indem Sie das Gebietsschema auf „C“ ändern, wird das fold Dienstprogramm kümmerte sich nicht um die Multi-Byte-Folgen – da die Tools per Definition davon ausgehen müssen, dass ein Zeichen ein Byte ist, wenn das Gebietsschema „C“ ist . Ein Zeilenumbruch kann also überall hinzugefügt werden, sogar mitten in einer Folge von Bytes, die würde wurden in einer anderen Zeichencodierung als Multibyte-Zeichen betrachtet. Genau das passierte, als das Tool den c3 0a a8 erzeugte Bytefolge:Die zwei Bytes c3 a8 werden als ein Zeichen verstanden wenn LC_CTYPE definiert die Zeichenkodierung als UTF-8. Aber dieselbe Folge von Bytes wird als zwei Zeichen gesehen im Gebietsschema „C“:
# Bytes are bytes. They don't change so
# the byte count is the same whatever is the locale
openbsd-6.3$ printf "%d bytes\n" $(echo -n é | LC_ALL=en_US.UTF-8 wc -c)
2 bytes
openbsd-6.3$ printf "%d bytes\n" $(echo -n é | LC_ALL=C wc -c)
2 bytes
# The interpretation of the bytes may change depending on the encoding
# so the corresponding character count will change
openbsd-6.3$ printf "%d chars\n" $(echo -n é | LC_ALL=en_US.UTF-8 wc -m)
1 chars
openbsd-6.3$ printf "%d chars\n" $(echo -n é | LC_ALL=C wc -m)
2 chars
Andererseits mit dem -b Option sollte das Tool immer noch Multi-Byte-fähig sein. Diese Option ändert sich nur in der Art und Weise, wie Positionen gezählt werden , diesmal in Bytes und nicht wie standardmäßig in Zeichen. In diesem Fall bleibt die resultierende Ausgabe ein gültiger Zeichenstrom (entsprechend dem aktuellen LC_CTYPE Gebietsschemaeinstellungen):
openbsd-6.3$ echo élève | fold -b -w 2
é
l
è
ve
Sie haben es gesehen, jetzt kommt das Unicode-Ersatzzeichen nicht mehr vor (� ), und wir haben dabei kein bedeutungsvolles Zeichen verloren – auf Kosten davon, dass wir dieses Mal mit Zeilen enden, die eine variable Anzahl von Zeichen und enthalten eine variable Anzahl von Bytes. Schließlich stellt das Tool sicher, dass nicht mehr Bytes pro Zeile vorhanden sind, als mit dem -w angefordert werden Möglichkeit. Etwas, das wir mit dem wc überprüfen können Werkzeug:
openbsd-6.3$ echo élève | fold -b -w 2 | while read line; do
> printf "%3d bytes %3d chars %s\n" \
> $(echo -n $line | wc -c) \
> $(echo -n $line | wc -m) \
> $line
> done
2 bytes 1 chars é
1 bytes 1 chars l
2 bytes 1 chars è
2 bytes 2 chars ve
Nehmen Sie sich noch einmal die Zeit, die Sie brauchen, um das obige Beispiel zu studieren. Es verwendet den printf und wc Befehle, die ich zuvor nicht im Detail erklärt habe. Wenn die Dinge also nicht klar genug sind, zögern Sie nicht, den Kommentarbereich zu nutzen, um nach Erklärungen zu fragen!
Aus Neugier habe ich das -b überprüft Flag auf meiner Debian-Box mit dem GNU fold Implementierung:
debian-9.4$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
debian-9.4$ echo élève | fold -b -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
Verbringen Sie nicht Ihre Zeit damit, einen Unterschied zwischen dem -b zu finden und nicht--b Versionen dieses Beispiels:Wir haben gesehen, dass die GNU-Fold-Implementierung nicht Multibyte-fähig ist, sodass beide Ergebnisse identisch sind. Wenn Sie davon nicht überzeugt sind, könnten Sie vielleicht das diff -s verwenden Befehl, um ihn von Ihrem Computer bestätigen zu lassen. Wenn Sie dies tun, verwenden Sie bitte den Kommentarbereich, um den von Ihnen verwendeten Befehl mit den anderen Lesern zu teilen!
Bedeutet das jedenfalls das -b Option nutzlos in der GNU-Implementierung von fold Nützlichkeit? Nun, indem Sie die GNU Coreutils-Dokumentation für fold sorgfältiger lesen Befehl habe ich den -b gefunden Option befasst sich nur mit Sonderzeichen wie die Tabulatortaste oder die Rücktaste, die im normalen Modus jeweils für die Positionen 1 bis 8 (eins bis acht) oder -1 (minus eins) zählen, im Byte-Modus jedoch immer für eine Position zählen. Verwirrend? Vielleicht könnten wir uns etwas Zeit nehmen, um das genauer zu erklären.
Tab- und Backspace-Behandlung
Die meisten Textdateien, mit denen Sie es zu tun haben, enthalten nur druckbare Zeichen und Zeilenende-Sequenzen. Gelegentlich kann es jedoch vorkommen, dass Steuerzeichen in Ihre Daten gelangen. Das Tabulatorzeichen (\t ) Ist einer von ihnen. Viel seltener ist die Rücktaste (\b ) kann auch vorkommen. Ich erwähne es hier trotzdem, weil es, wie der Name schon sagt, ein Steuerzeichen ist, das den Cursor um eine Position rückwärts bewegt (nach links), während die meisten anderen Charaktere es vorwärts machen (nach rechts).
sh$ echo -e 'tab:[\t] backspace:[\b]'
tab:[ ] backspace:]
Dies ist möglicherweise in Ihrem Browser nicht sichtbar, daher empfehle ich Ihnen dringend, dies auf Ihrem Endgerät zu testen. Aber die Tabulatorzeichen (\t ) belegt mehrere Positionen auf der Ausgabe. Und die Rücktaste? Die Ausgabe scheint etwas Seltsames zu enthalten, nicht wahr? Lassen Sie die Dinge also ein wenig verlangsamen, indem Sie die Textzeichenfolge in mehrere Teile aufteilen und etwas sleep einfügen dazwischen:
# For that to work, type all the commands on the same line
# or using backslashes like here if you split them into
# several (physical) lines:
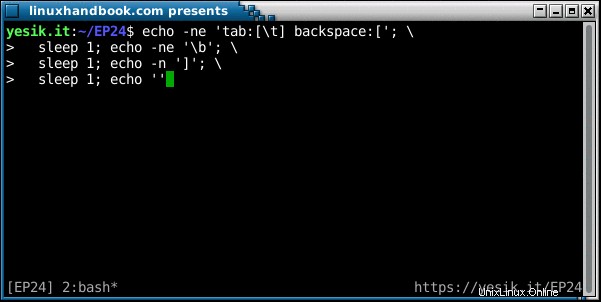
sh$ echo -ne 'tab:[\t] backspace:['; \
sleep 1; echo -ne '\b'; \
sleep 1; echo -n ']'; \
sleep 1; echo ''OK? Hast du es diesmal gesehen? Lassen Sie uns die Abfolge der Ereignisse zerlegen:
- Die erste Zeichenkette wird bis zur zweiten öffnenden eckigen Klammer „normal“ dargestellt. Wegen dem
-nFlag, dasechoBefehl nicht sende ein Newline-Zeichen, damit der Cursor in der gleichen Zeile bleibt. - Erst schlafen.
- Backspace wird ausgegeben, was dazu führt, dass sich der Cursor um eine Position zurückbewegt. Immer noch kein Zeilenumbruch, also bleibt der Cursor auf der gleichen Zeile.
- Zweiter Schlaf.
- Die schließende eckige Klammer wird angezeigt, überschreibt die Eröffnung.
- Dritter Schlaf.
- In Ermangelung des
-nOption, das letzteechoBefehl sendet schließlich das Newline-Zeichen und der Cursor bewegt sich auf die nächste Zeile, wo Ihr Shell-Prompt angezeigt wird.
Natürlich lässt sich ein ähnlich cooler Effekt mit einem Wagenrücklauf erzielen, wenn Sie sich daran erinnern:
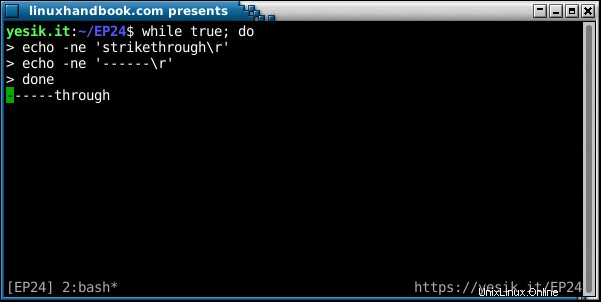
sh$ echo -n 'hello'; sleep 1; echo -e '\rgood bye'
good bye
Ich bin mir ziemlich sicher, dass Sie bereits ein Befehlszeilenprogramm wie curl gesehen haben , wget oder ffmpeg Anzeige eines Fortschrittsbalkens. Sie wirken mit einer Kombination aus \b und/oder \r .
Da diese Diskussion für sich alleine interessant sein kann, ging es hier darum zu verstehen, dass der Umgang mit diesen Zeichen eine Herausforderung für das fold sein kann Nützlichkeit. Hoffentlich definiert der POSIX-Standard die Regeln:
Alle diese Sonderbehandlungen werden deaktiviert, wenn Sie -b verwenden Möglichkeit. Dann zählen vor allem die Steuerzeichen (korrekterweise) für ein Byte und damit den Positionszähler um eins und nur um eins erhöhen – genau wie alle anderen Zeichen auch.
Zum besseren Verständnis lasse ich Sie die beiden folgenden zwei Beispiele selbst untersuchen (evtl. mit dem hexdump Nützlichkeit). Sie sollten jetzt herausfinden können, warum „hello“ zu „hell“ wurde und wo genau das „i“ in der Ausgabe ist (so wie es da ist, auch wenn Sie es nicht sehen können!) Wie immer, wenn Sie Hilfe benötigen , oder einfach, wenn Sie Ihre Ergebnisse teilen möchten, der Kommentarbereich gehört Ihnen.
# Why "hello" has become "hell"? where is the "i"?
sh$ echo -e 'hello\rgood bi\bye' | fold -w4
hell
good
bye
# Why "hello" has become "hell"? where is the "i"?
# Why the second line seems to be made of only two chars instead of 4?
sh$ echo -e 'hello\rgood bi\bye' | fold -bw4
hell
go
od b
yeWeitere Einschränkungen
Die fold Der Befehl, den wir bisher untersucht haben, wurde entwickelt, um lange logische Zeilen in kleinere physische Zeilen aufzuteilen, insbesondere zu Formatierungszwecken.
Das heißt, es wird davon ausgegangen, dass jede Eingangsleitung in sich geschlossen ist und unabhängig von den anderen Leitungen unterbrochen werden kann. Dies ist jedoch nicht immer der Fall. Betrachten wir zum Beispiel diese sehr wichtige E-Mail, die ich erhalten habe:
sh$ cat MAIL.txt
Dear friends,
Have a nice day!
We are manufactuer for event chairs and tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs, include chiavari
chairs, cross back chairs, folding chairs, napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively priced.
If you need our products, welcome to contact me;we are happy to make you special
offer.
Best Regards
Doris
sh$ awk '{ length>maxlen && (maxlen=length) } END { print maxlen }' MAIL.txt
81
Offensichtlich waren die Linien bereits auf eine feste Breite gebrochen. Das awk Der Befehl sagte mir, dass die maximale Zeilenbreite hier … 81 Zeichen beträgt – ohne die neue Zeilenfolge. Ja, das war so seltsam, dass ich es noch einmal überprüft habe:Die längste Zeile hat tatsächlich 80 druckbare Zeichen plus ein zusätzliches Leerzeichen an der 81. Position und erst danach kommt das Zeilenvorschubzeichen. Wahrscheinlich könnten IT-Leute, die im Auftrag dieses Lehrstuhl-„Herstellers“ arbeiten, von der Lektüre dieses Artikels profitieren!
Angenommen, ich möchte die Formatierung dieser E-Mail ändern, werde ich Probleme mit dem fold haben wegen der vorhandenen Zeilenumbrüche. Ich lasse Sie die beiden folgenden Befehle selbst überprüfen, wenn Sie möchten, aber keiner von ihnen wird wie erwartet funktionieren:
sh$ fold -sw 100 MAIL.txt
sh$ fold -sw 60 MAIL.txtDer erste wird einfach nichts tun, da alle Zeilen bereits kürzer als 100 Zeichen sind. Beim zweiten Befehl werden Zeilen an der 60. Position umgebrochen, aber bereits vorhandene Zeilenumbrüche beibehalten, sodass das Ergebnis gezackt wird. Dies wird besonders im dritten Absatz deutlich:
sh$ awk -v RS='' 'NR==3' MAIL.txt |
fold -sw 60 |
awk '{ length>maxlen && (maxlen=length); print length, $0 }'
53 We supply all kinds of wooden, resin and metal event
25 chairs, include chiavari
60 chairs, cross back chairs, folding chairs, napoleon chairs,
20 phoenix chairs, etc.Die erste Zeile des dritten Absatzes wurde an Position 53 umgebrochen, was unserer maximalen Breite von 60 Zeichen pro Zeile entspricht. Die zweite Zeile wurde jedoch an Position 25 unterbrochen, weil dieses Zeilenumbruchzeichen bereits war in der Eingabedatei vorhanden. Mit anderen Worten, um die Größe der Absätze richtig zu ändern, müssen wir zuerst die Zeilen wieder verbinden, bevor wir sie an der neuen Zielposition umbrechen.
Sie können sed verwenden oder awk um die Linien wieder zu verbinden. Und tatsächlich, wie ich es im Einführungsvideo erwähnt habe, wäre das eine gute Herausforderung für Sie. Zögern Sie also nicht, Ihre Lösung im Kommentarbereich zu posten.
Was mich betrifft, werde ich einen einfacheren Weg gehen, indem ich mir den fmt anschaue Befehl. Obwohl es sich nicht um einen POSIX-Standardbefehl handelt, ist er sowohl in der GNU- als auch in der BSD-Welt verfügbar. Es besteht also eine gute Chance, dass es auf Ihrem System verwendet werden kann. Leider wird der Mangel an Standardisierung einige negative Auswirkungen haben, wie wir später sehen werden. Aber jetzt konzentrieren wir uns auf die guten Seiten.
Der fmt-Befehl
Der fmt Der Befehl ist weiter entwickelt als der fold Befehl und hat mehr Formatierungsoptionen. Der interessanteste Teil ist, dass es Absätze in der Eingabedatei anhand der leeren Zeilen identifizieren kann. Das bedeutet, dass alle Zeilen bis zur nächsten leeren Zeile (oder dem Ende der Datei) zuerst zusammengefügt werden, um das zu bilden, was ich zuvor eine „logische Zeile“ des Textes genannt habe. Erst danach wird der fmt Befehl wird den Text an der gewünschten Position umbrechen.
Mal sehen, was sich ändert, wenn es auf den zweiten Absatz meiner Beispielmail angewendet wird:
sh$ awk -v RS='' 'NR==3' MAIL.txt |
fmt -w 60 |
awk '{ length>maxlen && (maxlen=length); print length, $0 }'
60 We supply all kinds of wooden, resin and metal event chairs,
59 include chiavari chairs, cross back chairs, folding chairs,
37 napoleon chairs, phoenix chairs, etc.
Anekdotisch der fmt Befehl akzeptiert, um ein weiteres Wort in die erste Zeile zu packen. Aber noch interessanter ist, dass die zweite Zeile jetzt gefüllt ist, was bedeutet, dass das in der Eingabedatei bereits vorhandene Zeilenumbruchzeichen nach dem Wort „chiavari“ (was ist das?) verworfen wurde. Natürlich sind die Dinge nicht perfekt und die fmt Absatzerkennungsalgorithmus löst manchmal Fehlalarme aus, wie in den Grüßen am Ende der Mail (Zeile 14 der Ausgabe):
sh$ fmt -w 60 MAIL.txt | cat -n
1 Dear friends,
2
3 Have a nice day! We are manufactuer for event chairs and
4 tables, more than 10 years experience.
5
6 We supply all kinds of wooden, resin and metal event chairs,
7 include chiavari chairs, cross back chairs, folding chairs,
8 napoleon chairs, phoenix chairs, etc.
9
10 Our chairs and tables are of high quality and competitively
11 priced. If you need our products, welcome to contact me;we
12 are happy to make you special offer.
13
14 Best Regards Doris
Ich sagte vorhin den fmt Der Befehl war ein weiter entwickeltes Werkzeug zur Textformatierung als der Befehl fold Nützlichkeit. Es ist wirklich. Es mag auf den ersten Blick nicht offensichtlich sein, aber wenn Sie sich die Zeilen 10-11 genau ansehen, werden Sie vielleicht feststellen, dass zwei verwendet wurden Leerzeichen nach dem Punkt – wodurch eine am häufigsten diskutierte Konvention durchgesetzt wird, zwei Leerzeichen am Ende eines Satzes zu verwenden. Ich werde nicht auf diese Debatte eingehen, um zu wissen, ob Sie zwei Leerzeichen zwischen Sätzen verwenden sollten oder nicht, aber Sie haben hier keine wirkliche Wahl:meines Wissens keine der üblichen Implementierungen des fmt bieten ein Flag an, um das doppelte Leerzeichen nach einem Satz zu deaktivieren. Es sei denn, eine solche Option existiert irgendwo und ich habe sie übersehen? Wenn dies der Fall ist, freue ich mich, wenn Sie mich über den Kommentarbereich darauf hinweisen:Als französischer Schriftsteller habe ich nie das „doppelte Leerzeichen“ nach einem Satz verwendet…
Weitere fmt-Optionen
Der fmt Das Dienstprogramm wurde mit etwas mehr Formatierungsfunktionen als der Befehl fold entwickelt. Da es jedoch nicht POSIX-definiert ist, gibt es große Inkompatibilitäten zwischen den GNU- und BSD-Optionen.
Beispiel:-c Die Option wird in der BSD-Welt verwendet, um den Text zu zentrieren, während in fmt von GNU Coreutils es aktiviert den oberen Randmodus, „behält den Einzug der ersten beiden Zeilen innerhalb eines Absatzes bei und richtet den linken Rand jeder nachfolgenden Zeile an dem der zweiten Zeile aus. „
Ich lasse Sie selbst mit dem GNU fmt -c experimentieren falls Sie es wollen. Ich persönlich finde die BSD-Funktion zur Textzentrierung aufgrund einiger Kuriositäten interessanter zu studieren:in der Tat, in OpenBSD, fmt -c will center the text according to the target width— but without reflowing it! So the following command will not work as you might have expected:
openbsd-6.3$ fmt -c -w 60 MAIL.txt
Dear friends,
Have a nice day!
We are manufactuer for event chairs and tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs, include chiavari
chairs, cross back chairs, folding chairs, napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively priced.
If you need our products, welcome to contact me;we are happy to make you special
offer.
Best Regards
Doris
If you really want to reflow the text for a maximum width of 60 characters and center the result, you will have to use two instances of the fmt command:
openbsd-6.3$ fmt -w 60 MAIL.txt | fmt -c -w60
Dear friends,
Have a nice day! We are manufactuer for event chairs and
tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs,
include chiavari chairs, cross back chairs, folding chairs,
napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively
priced. If you need our products, welcome to contact me;we
are happy to make you special offer.
Best Regards Doris
I will not make here an exhaustive list of the differences between the GNU and BSD fmt implementations … essentially because all the options are different! Except of course the -w Möglichkeit. Speaking of that, I forgot to mention -N where N is an integer is a shortcut for -wN . Moreover you can use that shortcut both with the fold and fmt commands:so, if you were perseverent enough to read his article until this point, as a reward you may now amaze your friends by saving one (!) entire keystroke the next time you will use one of those utilities:
debian-9.4$ fmt -50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified
by the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
openbsd-6.3$ fmt -50 POSIX.txt | head -5
The Portable Operating System Interface (POSIX)[1]
is a family of standards specified by the IEEE
Computer Society for maintaining compatibility
between operating systems. POSIX defines the
application programming interface (API), along
debian-9.4$ fold -sw50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified by
the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
openbsd-6.3$ fold -sw50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified by
the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
As the final word, you may also notice in that last example the GNU and BSD versions of the fmt utility are using a different formatting algorithm, producing a different result. On the other hand, the simpler fold algorithm produces consistent results between the implementations. All that to say if portability is a premium, you need to stick with the fold command, eventually completed by some other POSIX utilities. But if you need more fancy features and can afford to break compatibility, take a look at the manual for the fmt command specific to your own system. And let us know if you discovered some fun or creative usage for those vendor-specific options!