Sobald Sie die Linux-Betriebssystemdomäne betreten, scheint die Liste der Rechenmöglichkeiten über die Linux-Befehlszeilenumgebung endlos zu sein. Es liegt einfach daran, dass Sie umso mehr lernen möchten, je mehr Sie Linux verwenden, und dieses Verlangen führt Sie durch unzählige Lernmöglichkeiten.
In diesem Lernprogramm werden wir uns mit dem Zählen und Drucken doppelter Zeilen in einer Textdatei unter einer Linux-Betriebssystemumgebung befassen. Dieses Tutorial-Modul ist Teil der Linux-Dateiverwaltung.
Die Linux-Befehlszeilen- oder Terminalumgebung ist für die Verarbeitung von Eingabetextdateien nicht neu. Es beherrscht solche Operationen so gut, dass es bei der Verarbeitung von Textdateien noch auf eine würdige Herausforderung stoßen muss.
Dieses Tutorial wird etwas Licht in das Identifizieren/Handhaben von doppelten Zeilen in zufälligen Textdateien unter Linux bringen.
Problembeschreibung
Um dieses Tutorial einfacher und interessanter zu gestalten, erstellen wir eine Beispieltextdatei, die als Zufallsdatei fungiert, die wir auf das Vorhandensein doppelter Zeilen überprüfen möchten.
$ sudo nano sample_file.txt
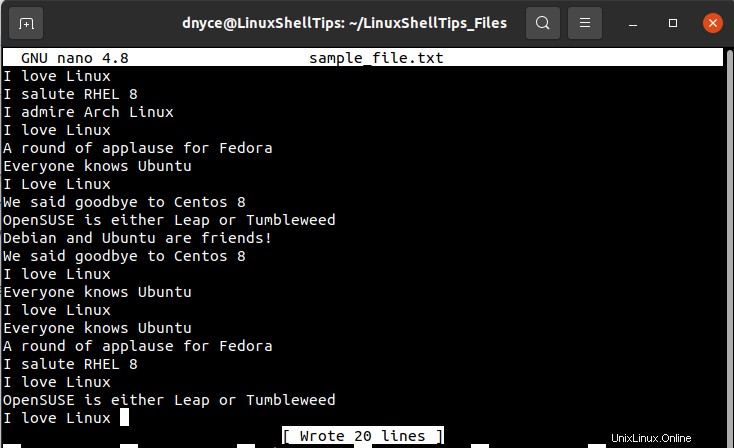
Wenn wir einfach die Bildschirmaufnahme der obigen Textdatei durchsehen, sollten wir in der Lage sein, das Vorhandensein einiger doppelter Zeilen zu bemerken, aber wir können nicht sicher sein, wie genau sie vorkommen.
Um sicherzugehen, wie viele doppelte Zeilen auftreten, finden wir unsere Lösungen in den folgenden Linux-Befehlszeilen-/Terminal-basierten Ansätzen:
Suchen Sie doppelte Zeilen in der Datei mit den Befehlen sort und uniq
Die Bequemlichkeit der Verwendung von uniq Befehl ist, dass es mit -c kommt Befehlsoption. Diese Befehlsoption ist jedoch nur gültig, wenn die Textdatei, auf die Sie abzielen/die Sie scannen, doppelte benachbarte Zeilen aufweist.
Um diese Unannehmlichkeiten bei der Verwendung von uniq zu vermeiden Um doppelte Zeilen zu drucken, müssen wir uns den sort-Befehlsansatz ausleihen, bei dem wiederholte/duplizierte Zeilen innerhalb einer Zieltextdatei gruppiert werden.
Kurz gesagt, wir werden die Zieltextdatei zuerst über die Sortierung übergeben Befehl und leiten Sie ihn anschließend an uniq weiter Befehl, der dann von -c begleitet wird Befehlsoption wie unten gezeigt:
$ sort sample_file.txt | uniq -c
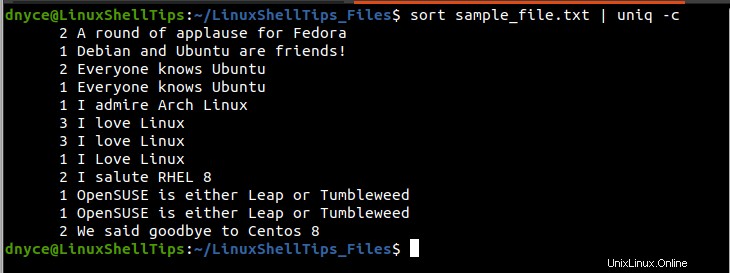
Die erste Spalte (links) der obigen Ausgabe gibt an, wie oft die gedruckten Zeilen in der rechten Spalte in der sample_file.txt erscheinen Textdatei. Zum Beispiel die Zeile „I love Linux“ wird innerhalb der Textdatei insgesamt 7 Mal dupliziert/wiederholt (3+3+1).
Duplizierte Zeilen in Datei mit dem Awk-Befehl drucken
Das awk Befehl, um dieses Problem zu lösen „duplizierte Zeilen in einer Textdatei drucken „Problem ist ein einfacher Einzeiler. Um zu verstehen, wie es funktioniert, müssen wir es zuerst wie unten gezeigt implementieren:
$ awk '{ a[$0]++ } END{ for(x in a) print a[x], x }' sample_file.txt
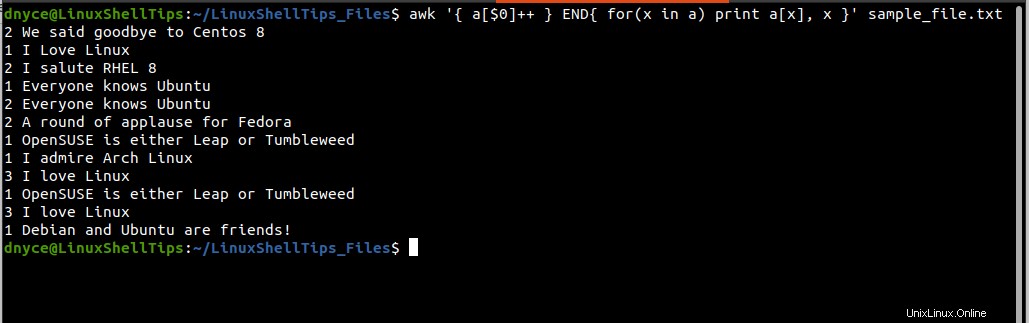
Die Ausführung des obigen Befehls gibt zwei Spalten aus, die erste Spalte zählt, wie oft eine wiederholte/duplizierte Zeile in der Textdatei erscheint, und die zweite Spalte zeigt auf die betreffende Zeile.
Die Ausgabe des obigen Befehls ist jedoch nicht so organisiert wie die unter sort und einzigartig Befehle.
Wir haben erfolgreich behandelt, wie man doppelte Zeilen in einer Textdatei unter einer Linux-Betriebssystemumgebung druckt.