Wenn Sie meinen ersten Artikel über die Verwendung von Keepalived zur Verwaltung einfacher Failover in Clustern gelesen haben, werden Sie sich an VRRP erinnern verwendet das Konzept einer Priorität, wenn bestimmt wird, welcher Server der aktive Master sein wird. Der Server mit der höchsten Priorität „gewinnt“ und agiert als Master, behält die VIPs und bedient Anfragen. Keepalived bietet mehrere nützliche Methoden zum Anpassen der Priorität basierend auf dem Status Ihres Systems. In diesem Artikel werden Sie mehrere dieser Mechanismen zusammen mit Keepalived untersuchen die Fähigkeit von , Skripts auszuführen, wenn sich der Status eines Servers ändert.
Ich werde für diese Beispiele nur die Konfiguration auf server1 zeigen. An diesem Punkt sind Sie wahrscheinlich mit der auf server2 erforderlichen Konfiguration vertraut, wenn Sie die gesamte Serie gelesen haben. Wenn nicht, nehmen Sie sich einen Moment Zeit, um den ersten und zweiten Artikel dieser Serie zu lesen, bevor Sie fortfahren.
- Verwendung von Keepalived für die Verwaltung von einfachem Failover in Clustern
- Einrichten eines Linux-Clusters mit Keepalived:Basiskonfiguration
Netzwerksymbole in den Diagrammen verfügbar über VRT Network Equipment Extension, CC BY-SA 3.0.
Keepalived leistet hervorragende Arbeit beim Auslösen eines Failover, wenn keine Ankündigungen empfangen werden, z. B. wenn der aktive Master vollständig stirbt oder aus einem anderen Grund nicht erreichbar ist. Sie werden jedoch häufig feststellen, dass feinkörnigere Auslösemechanismen erforderlich sind. Beispielsweise kann Ihre Anwendung eigene Integritätsprüfungen ausführen, um die Fähigkeit der App zu ermitteln, Clientanforderungen zu bedienen. Sie möchten nicht, dass ein fehlerhafter App-Server der aktive Master bleibt, nur weil er am Leben ist und VRRP sendet Werbung.
Hinweis:Ich habe festgestellt, dass die Version von Keepalived die über die Standardpaket-Repositories verfügbar waren, enthielten Fehler, die einige der folgenden Beispiele daran hinderten, richtig zu funktionieren. Wenn Sie auf Probleme stoßen, können Sie Keepalived installieren aus der Quelle, wie im vorherigen Artikel beschrieben.
Tracking-Prozesse
Einer der häufigsten Keepalived setups beinhaltet das Verfolgen eines Prozesses auf dem Server, um den Zustand des Hosts zu bestimmen. Beispielsweise könnten Sie ein Paar hochverfügbarer Webserver einrichten und ein Failover auslösen, wenn Apache auf einem von ihnen nicht mehr ausgeführt wird.
Keepalived macht dies einfach durch seinen track_process Konfigurationsanweisungen. Im folgenden Beispiel habe ich Keepalived eingerichtet um den httpd anzusehen Prozess mit einer Gewichtung von 10. Solange httpd läuft, ist die angekündigte Priorität 254 (244 + 10 =254). Wenn httpd nicht mehr ausgeführt wird, dann sinkt die Priorität auf 244 und löst ein Failover aus (vorausgesetzt, dass auf Server2 eine ähnliche Konfiguration vorhanden ist).
server1# cat keepalived.conf
vrrp_track_process track_apache {
process httpd
weight 10
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_process {
track_apache
}
} Wenn diese Konfiguration vorhanden ist (und Apache auf beiden Servern installiert ist und ausgeführt wird), können Sie ein Failover-Szenario testen, indem Sie Apache stoppen und beobachten, wie sich die VIP von Server1 zu Server2 bewegt:
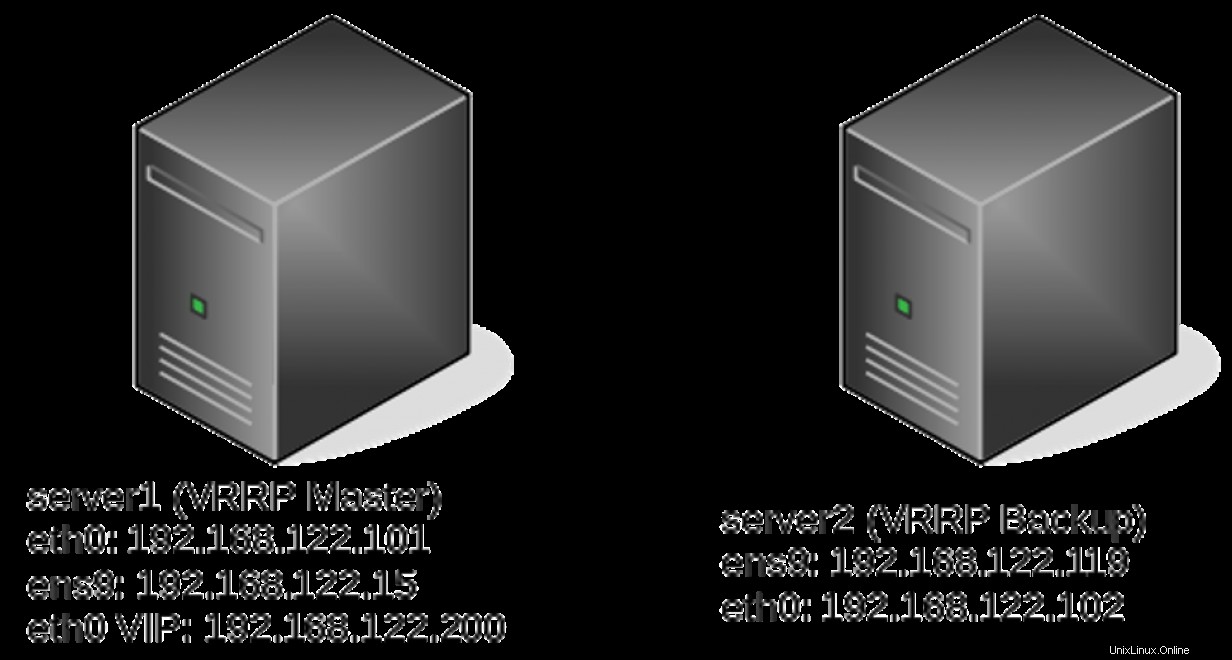
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
server1# systemctl stop httpd
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
server2# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.102/24 192.168.122.200/24 fe80::5054:ff:fe04:2c5d/64 Tracking-Dateien
Keepalived hat auch die Fähigkeit, Prioritätsentscheidungen basierend auf dem Inhalt einer Datei zu treffen, was nützlich sein kann, wenn Sie eine Anwendung ausführen, die Werte in diese Datei schreiben kann. Sie haben beispielsweise einen Hintergrundprozess in Ihrer App, der regelmäßig eine Zustandsprüfung durchführt und basierend auf dem Gesamtzustand der Anwendung einen Wert in eine Datei schreibt.
Die Keepalived Manpage erklärt, dass die Dateiverfolgung auf der konfigurierten Gewichtung für die Datei basiert:
“Wert wird als Zahl im Text aus der Datei gelesen. Wenn die für track_file konfigurierte Gewichtung 0 ist, wird ein Wert ungleich Null in der Datei als Fehlerstatus behandelt und ein Wert von Null wird als OK-Status behandelt, andernfalls wird der Wert mit der in konfigurierten Gewichtung multipliziert track_file-Anweisung. Wenn das Ergebnis kleiner als -253 ist, wechselt jede VRRP-Instanz oder Synchronisierungsgruppe, die das Skript überwacht, in den Fehlerzustand (die Gewichtung kann 254 sein, damit ein negativer Wert aus der Datei gelesen werden kann).“
Ich werde die Dinge einfach halten und in diesem Beispiel eine Gewichtung von 1 für die Track-Datei verwenden. Diese Konfiguration übernimmt den numerischen Wert in der Datei unter /var/run/my_app/vrrp_track_file und mit 1 multiplizieren.
server1# cat keepalived.conf
vrrp_track_file track_app_file {
file /var/run/my_app/vrrp_track_file
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_file {
track_app_file weight 1
}
}
Sie können nun die Datei mit einem Startwert erstellen und Keepalived neu starten . Die Priorität ist in tcpdump ersichtlich Ausgabe, wie im zweiten Artikel dieser Serie besprochen.
server1# mkdir /var/run/my_app
server1# echo 5 > /var/run/my_app/vrrp_track_file
server1# systemctl restart keepalived
server1# tcpdump proto 112
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:19:32.191562 IP server1 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 249, authtype simple, intvl 1s, length 20 Sie können sehen, dass die angekündigte Priorität 249 ist, was dem Wert in der Datei (5) multipliziert mit der Gewichtung (1) entspricht und zur Basispriorität (244) hinzugefügt wird. Ebenso erhöht das Anpassen der Priorität auf 6 die Priorität:
server1# echo 6 > /var/run/my_app/vrrp_track_file
server1# tcpdump proto 112
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:20:43.214940 IP server1 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 250, authtype simple, intvl 1s, length 20 Track-Schnittstelle
Bei Servern mit mehreren Schnittstellen kann es sinnvoll sein, die Priorität des Keepalived anzupassen Instanz basierend auf dem Status einer Schnittstelle. Beispielsweise möchte ein Load Balancer mit einer Front-End-VIP und einer Back-End-Verbindung zu einem internen Netzwerk möglicherweise ein Keepalived auslösen Failover, wenn die Verbindung zum Back-End-Netzwerk unterbrochen wird. Dies kann mit der track_interface-Konfiguration erreicht werden:
server1# cat keepalived.conf
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_interface {
ens9 weight 5
}
} Die obige Konfiguration weist dem Status der Schnittstelle ens9 eine Gewichtung von 5 zu. Dadurch nimmt server1 eine Priorität von 249 (244 + 5 =249) an, solange ens9 aktiv ist. Wenn ens9 ausfällt, sinkt die Priorität auf 244 (und löst ein Failover aus, vorausgesetzt, dass server2 auf die gleiche Weise konfiguriert ist). Sie können dies auf einem Server mit mehreren Schnittstellen testen, indem Sie eine Schnittstelle herunterfahren und beobachten, wie sich der VIP zwischen den Hosts bewegt:
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
ens9 UP 192.168.122.15/24 fe80::7444:5ec4:8015:722f/64
server1# ip link set ens9 down
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
ens9 DOWN
server2# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
ens9 UP 192.168.122.119/24 fe80::fc9f:8999:b93e:d491/64
eth0 UP 192.168.122.102/24 192.168.122.200/24 fe80::5054:ff:fe04:2c5d/64 Track-Skript
Sie haben gesehen, dass Keepalived bietet viele nützliche integrierte Prüfmethoden zur Bestimmung des Zustands und der anschließenden VRRP Priorität eines Hosts. Manchmal erfordern komplexere Umgebungen jedoch die Verwendung benutzerdefinierter Tools, wie z. B. Zustandsprüfungsskripts, um ihre Anforderungen zu erfüllen. Zum Glück Keepalived hat auch die Fähigkeit, ein beliebiges Skript auszuführen, um den Zustand eines Hosts zu bestimmen. Sie können die Gewichtung des Skripts anpassen, aber ich werde die Dinge für dieses Beispiel einfach halten:Ein Skript, das 0 zurückgibt, zeigt einen Erfolg an, während ein Skript, das etwas anderes zurückgibt, anzeigt, dass Keepalived Instanz sollte in den Fehlerzustand wechseln.
Das Skript ist ein einfacher Ping zu jedermanns Lieblings-8.8.8.8 Google DNS-Server, wie unten zu sehen. In Ihrer Umgebung werden Sie wahrscheinlich ein komplexeres Skript verwenden, um alle erforderlichen Zustandsprüfungen durchzuführen.
server1# cat /usr/local/bin/keepalived_check.sh
#!/bin/bash
/usr/bin/ping -c 1 -W 1 8.8.8.8 > /dev/null 2>&1
Sie werden feststellen, dass ich für ping ein Timeout von 1 Sekunde verwendet habe (-W 1). Beim Schreiben von Keepalived überprüfen Sie Skripte, es ist eine gute Idee, sie leicht und schnell zu halten. Sie möchten nicht, dass ein defekter Server lange Zeit der Master bleibt, weil Ihr Skript langsam ist.
Die Keepalived Die Konfiguration für ein Prüfskript ist unten dargestellt:
server1# cat keepalived.conf
vrrp_script keepalived_check {
script "/usr/local/bin/keepalived_check.sh"
interval 1
timeout 5
rise 3
fall 3
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_script {
keepalived_check
}
}
Dies sieht der Konfiguration, mit der Sie gearbeitet haben, sehr ähnlich, aber das vrrp_script block hat ein paar eindeutige Direktiven:
interval:Wie oft das Skript ausgeführt werden soll (1 Sekunde).timeout:Wie lange auf die Rückkehr des Skripts gewartet werden soll (5 Sekunden).rise:Wie oft muss das Skript erfolgreich zurückkehren, damit der Host als „fehlerfrei“ betrachtet wird. In diesem Beispiel muss das Skript dreimal erfolgreich zurückkehren. Dies hilft, einen „flatternden“ Zustand zu verhindern, bei dem ein einzelner Fehler (oder Erfolg) dasKeepalivedverursacht Zustand, um schnell hin und her zu blättern.fall:Wie oft muss das Skript erfolglos (oder mit Zeitüberschreitung) zurückkehren, damit der Host als „fehlerhaft“ betrachtet wird. Dies funktioniert als Umkehrung der rise-Direktive.
Sie können diese Konfiguration testen, indem Sie das Fehlschlagen des Skripts erzwingen. Im folgenden Beispiel habe ich ein iptables hinzugefügt Regel, die die Kommunikation mit 8.8.8.8 verhindert . Dies führte dazu, dass der Healthcheck fehlschlug und der VIP nach einigen Sekunden verschwand. Ich kann dann die Regel entfernen und beobachten, wie der VIP wieder erscheint.
server1# iptables -I OUTPUT -d 8.8.8.8 -j DROP
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
server1# iptables -D OUTPUT -d 8.8.8.8 -j DROP
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
Ein kurzer Tipp zu Skripten in Keepalived :Sie können unter einem anderen Benutzer als root ausgeführt werden. Obwohl ich das in diesen Beispielen nicht demonstriert habe, werfen Sie einen Blick auf die Manpage und stellen Sie sicher, dass Sie den am wenigsten privilegierten Benutzer verwenden, um negative Auswirkungen auf die Sicherheit durch Ihr Prüfskript zu vermeiden.
Skripte benachrichtigen
Ich habe Möglichkeiten besprochen, Keepalived auszulösen Reaktionen basierend auf äußeren Bedingungen. Allerdings möchten Sie wahrscheinlich auch Aktionen auslösen, wenn Keepalived Übergänge von einem Zustand in einen anderen. Beispielsweise möchten Sie möglicherweise einen Dienst beenden, wenn Keepalived in den Sicherungszustand übergeht, oder Sie möchten vielleicht eine E-Mail an einen Administrator senden. Keepalived ermöglicht Ihnen, dies mit Benachrichtigungsskripten zu tun.
Keepalived stellt mehrere Benachrichtigungsanweisungen bereit, um Skripte nur in bestimmten Zuständen aufzurufen (notify_master , notify_backup , etc), aber ich werde mich auf das bloße notify konzentrieren Direktive, da sie am flexibelsten ist. Wenn ein Skript in der notify Direktive aufgerufen wird, erhält sie vier zusätzliche Argumente (nach allen Argumenten, die an das Skript selbst übergeben werden).
Der Reihe nach aufgelistet sind dies:
- Gruppe oder Instanz:Angabe, ob die Benachrichtigung durch ein
VRRPausgelöst wird Gruppe (wird in dieser Serie nicht besprochen) oder ein bestimmtesVRRPBeispiel. - Name der Gruppe oder Instanz
- Geben Sie an, dass die Gruppe oder Instanz wechselt in
- Die Priorität
Ein Blick auf ein Beispiel macht dies deutlicher. Das Skript und Keepalived Konfiguration sieht so aus:
server1# cat /usr/local/bin/keepalived_notify.sh
#!/bin/bash
echo "$1 $2 has transitioned to the $3 state with a priority of $4" > /var/run/keepalived_status
server1# cat keepalived.conf
vrrp_script keepalived_check {
script "/usr/local/bin/keepalived_check.sh"
interval 1
timeout 5
rise 3
fall 3
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_script {
keepalived_check
}
notify "/usr/local/bin/keepalived_notify.sh"
}
Die obige Konfiguration ruft /usr/local/bin/keepalived_notify.sh auf Skript jedes Mal, wenn ein Keepalived Zustandsübergang eintritt. Da dasselbe Prüfskript vorhanden ist, können Sie den Anfangszustand einfach überprüfen und dann einen Übergang auslösen:
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the MASTER state with a priority of 244
server1# iptables -A OUTPUT -d 8.8.8.8 -j DROP
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the FAULT state with a priority of 244
server1# iptables -D OUTPUT -d 8.8.8.8 -j DROP
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the MASTER state with a priority of 244
Sie können sehen, dass die Befehlszeilenargumente denen entsprechen, die ich am Anfang dieses Abschnitts beschrieben habe. Offensichtlich ist dies ein einfaches Beispiel, aber Benachrichtigungsskripte können viele komplexe Aktionen ausführen, wie z. B. das Anpassen von Routing-Regeln oder das Auslösen anderer Skripte. Sie sind eine nützliche Methode, um externe Aktionen basierend auf Keepalived durchzuführen Statusänderungen.
Abschluss
Dieser Artikel schloss ein grundlegendes Keepalived ab Serie mit einigen fortgeschrittenen Konzepten. Sie haben gelernt, wie man Keepalived auslöst Prioritäts- und Zustandsänderungen basierend auf externen Ereignissen, wie z. B. Prozessstatus, Schnittstellenänderungen und sogar die Ergebnisse externer Skripte. Sie haben auch gelernt, wie Sie Benachrichtigungsskripts als Reaktion auf Keepalived auslösen Zustand ändert. Sie können zwei oder mehr dieser Ansätze kombinieren, um ein hochverfügbares Paar von Linux-Servern aufzubauen, die auf mehrere externe Stimuli reagieren und sicherstellen, dass der Datenverkehr immer eine fehlerfreie IP-Adresse erreicht, die Client-Anfragen bedienen kann.
[ Möchten Sie mehr über Systemadministration erfahren? Nehmen Sie an einem kostenlosen Online-Kurs teil:Technischer Überblick zu Red Hat Enterprise Linux. ]