Der Sicherungsmechanismus in Elasticsearch heißt Snapshot. Ein Snapshot ist ein Backup, das von einem Elasticsearch-Cluster erstellt wird, der sich im laufenden Zustand befindet. Der Cluster muss nicht heruntergefahren werden, wodurch Wartungsfenster der Anwendungen vermieden werden. Ein Snapshot eines einzelnen Index oder des gesamten Clusters kann erstellt und in einem Repository auf einem gemeinsam genutzten Dateisystem gespeichert werden.
Snapshots in Elasticsearch werden inkrementell erstellt. Das bedeutet, dass Elasticsearch beim Erstellen eines Snapshots eines Index das Kopieren von Daten vermeidet, die bereits als Teil eines früheren Snapshots desselben Index gespeichert sind. Daher kann es sinnvoll sein, regelmäßig Snapshots des Clusters zu erstellen.
So wie wir ein Backup des Clusters im laufenden Zustand erstellen können, können wir auch einen Snapshot in einem laufenden Cluster wiederherstellen. Wenn wir einen Index wiederherstellen, können wir sogar den Namen des wiederhergestellten Index sowie einige seiner Einstellungen ändern.
Um Backups zu erstellen, müssen wir ein Snapshot-Repository registrieren, bevor wir die Snapshot- und Wiederherstellungsvorgänge durchführen können. Um das gemeinsam genutzte Dateisystem-Repository für den Cluster zu registrieren, muss dasselbe gemeinsam genutzte Dateisystem auf allen Master- und Datenknoten am selben Speicherort gemountet werden. Dieser Speicherort muss in der Konfigurationsdatei auf allen Master- und Datenknoten registriert werden.
In diesem Artikel überprüfen wir das gemeinsam genutzte NFS-Repository und sehen uns die Schritte an, um einen Snapshot zu erstellen und ihn wiederherzustellen.
Voraussetzungen
- Freigegebenes NFS-Verzeichnis verfügbar und auf allen 3 Knoten von Elasticsearch am selben Ort gemountet
- Elasticsearch-Cluster mit 3 Knoten auf 3 Ubuntu-Servern.
Was wir tun werden
- Überprüfen Sie die Einrichtung des NFS-Servers.
- Verifizieren Sie die Konfiguration des Elasticsearch-Clusters
- Registrieren Sie ein Repository, um Backups zu erstellen.
- Erstellen Sie eine Sicherungskopie und stellen Sie sie wieder her.
Überprüfen Sie die Einrichtung des NFS-Servers/Clients.
In diesem Artikel sprechen wir nicht über das NFS-Setup, da es nicht in den Rahmen dieses Artikels fällt. Aber um ein Backup von Elasticsearch zu erstellen, benötigen wir die folgende Einrichtung.
es-node-1(10.11.10.61) : NFS Client
es-node-2(10.11.10.62) : NFS Client
es-node-3(10.11.10.63) : NFS Client
NFS Server(10.11.10.64) : NFS Server
Hier
NFS-Server hat sein “/home/ubuntu/shared/” freigegeben Verzeichnis mit Elasticsearch-Knoten.
Jedes Elasticsearch hat sein lokales Verzeichnis “/home/ubuntu/mounted” gemountet im freigegebenen NFS-Verzeichnis „/home/ubuntu/shared/“ . Wir müssen sicherstellen, dass alle Verzeichnisse demselben Benutzer gehören, mit dem wir Elasticsearch starten würden.
Sobald wir diese Einrichtung eingerichtet haben, können wir weitermachen.
Verifizieren Sie die Konfiguration des Elasticsearch-Clusters
Führen Sie die folgenden Konfigurationen durch, um Elasticsearch so einzurichten, dass es im Cluster-Modus funktioniert:
Wenn Sie hier einen Elasticsearch-Cluster eingerichtet haben, müssen Sie sich der folgenden Konfiguration bewusst sein.
Die einzige Konfiguration, die wir vornehmen müssen, um Elasticsearch Cluster Backup neben der vorhandenen Elasticsearch-Clusterkonfiguration zu verwenden, ist „path.repo:["/home/ubuntu/mounted"] ":
vim config/elasticsearch.yml
path.repo: ["/home/ubuntu/mounted"]
Lassen Sie dies auf jedem Knoten gleich.
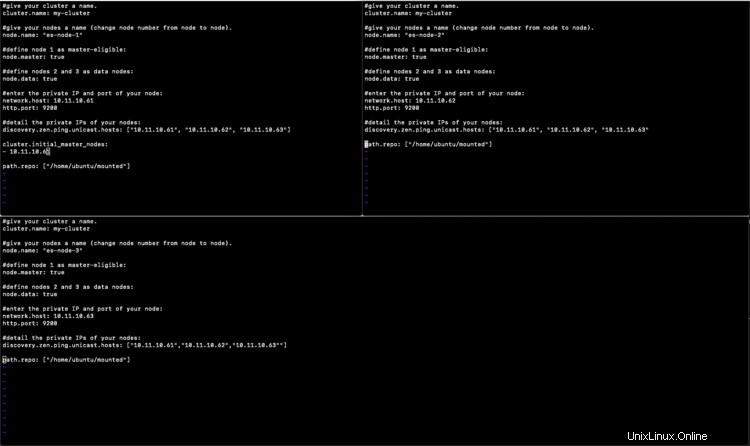
Konfiguration auf Knoten1
#give your cluster a name.
cluster.name: my-cluster
#give your nodes a name (change node number from node to node).
node.name: "es-node-1"
#define node 1 as master-eligible:
node.master: true
#define nodes 2 and 3 as data nodes:
node.data: true
#enter the private IP and port of your node:
network.host: 10.11.10.61
http.port: 9200
#detail the private IPs of your nodes:
discovery.zen.ping.unicast.hosts: ["10.11.10.61", "10.11.10.62", "10.11.10.63"]
cluster.initial_master_nodes:
- 10.11.10.61
path.repo: ["/home/ubuntu/mounted"]
Konfiguration auf Node2
#give your cluster a name.
cluster.name: my-cluster
#give your nodes a name (change node number from node to node).
node.name: "es-node-2"
#define node 2 as master-eligible:
node.master: false
#define nodes 2 and 3 as data nodes:
node.data: true
#enter the private IP and port of your node:
network.host: 10.11.10.62
http.port: 9200
#detail the private IPs of your nodes:
discovery.zen.ping.unicast.hosts: ["10.11.10.61", "10.11.10.62", "10.11.10.63"
path.repo: ["/home/ubuntu/mounted"]
Konfiguration auf Node3
#give your cluster a name.
cluster.name: my-cluster
#give your nodes a name (change node number from node to node).
node.name: "es-node-3"
#define node 3 as master-eligible:
node.master: false
#define nodes 2 and 3 as data nodes:
node.data: true
#enter the private IP and port of your node:
network.host: 10.11.10.63
http.port: 9200
#detail the private IPs of your nodes:
discovery.zen.ping.unicast.hosts: ["10.11.10.61","10.11.10.62","10.11.10.63""]
path.repo: ["/home/ubuntu/mounted"]
Sobald Sie diese Konfiguration vorgenommen haben, starten Sie alle Elasticsearch-Knoten und starten Sie zuerst den anfänglichen Master.
Registrieren Sie ein Repository, um Backups zu erstellen
Überprüfen Sie die vorhandenen Repositories mit dem folgenden Befehl.
curl -XGET 'http://IP_Of_Elasticsearch_Node_Or_Master:9200/_snapshot/_all?pretty=true'
Wenn wir eine leere Antwort erhalten, bedeutet dies, dass wir noch keine Repositories eingerichtet haben
Um ein Repository einzurichten, führen Sie den folgenden Befehl aus.
curl -XPUT 'http://IP_Of_Elasticsearch_Node_Or_Master:9200/_snapshot/my_backup' -d {
"type": "fs",
"settings": {
"location": "/home/ubuntu/mounted",
"compress": true
}
}' Hier ist „my_backup“ im obigen Befehl der Name des Repositorys.
Wir können die registrierten Repositories mit dem folgenden Befehl überprüfen
curl -XGET 'http://IP_Of_Elasticsearch_Node_Or_Master:9200/_snapshot/_all?pretty=true'
Sicherung und Wiederherstellung eines Elasticsearch-Clusters
Erstellen Sie eine Sicherung
Sobald wir ein Repo erstellt haben, können wir ein Backup erstellen.
Verwenden Sie den folgenden Befehl, um ein Backup mit dem Namen „snapshot_name“
zu erstellencurl -XPUT "https://IP_Of_Elasticsearch_Node_Or_Master:9200/_snapshot/my_backup/snapshot_name?wait_for_completion=true"
Ein Backup wiederherstellen
Der von uns erstellte Snapshot kann mit dem folgenden Befehl wiederhergestellt werden.
Verwenden Sie den folgenden Befehl, um die Sicherung mit dem Namen „snapshot_name“
wiederherzustellencurl -XPOST "http://IP_Of_Elasticsearch_Node_Or_Master:9200/_snapshot/my_backup/snapshot_name/_restore?wait_for_completion=true"
Schlussfolgerung
In diesem Artikel haben wir die Schritte gesehen, um ein Repository zu registrieren, ein Backup zu erstellen und es wiederherzustellen.