Wenn wir bestimmte Befehle in Unix/Linux ausführen, um Text aus einer Zeichenfolge oder Datei zu lesen oder zu bearbeiten, versuchen wir meistens, die Ausgabe auf einen bestimmten Abschnitt von Interesse zu filtern. Hier ist die Verwendung von regulären Ausdrücken praktisch.
Lesen Sie auch: 10 nützliche Linux-Verkettungsoperatoren mit praktischen Beispielen
Was sind reguläre Ausdrücke?
Ein regulärer Ausdruck kann als Zeichenfolge definiert werden, die mehrere Zeichenfolgen darstellt. Eines der wichtigsten Dinge bei regulären Ausdrücken ist, dass sie es Ihnen ermöglichen, die Ausgabe eines Befehls oder einer Datei zu filtern, einen Abschnitt einer Text- oder Konfigurationsdatei zu bearbeiten und so weiter.
Merkmale des regulären Ausdrucks
Reguläre Ausdrücke bestehen aus:
- Gewöhnliche Zeichen wie Leerzeichen, Unterstrich (_), A-Z, a-z, 0-9.
- Metazeichen die zu gewöhnlichen Zeichen erweitert werden, umfassen:
(.)es passt auf jedes einzelne Zeichen außer einem Zeilenumbruch.(*)es stimmt mit null oder mehr Existenzen des unmittelbar vorangehenden Zeichens überein.[ Zeichen ]es passt zu einem der in Zeichen angegebenen Zeichen, man kann auch einen Bindestrich(-)verwenden um eine Reihe von Zeichen wie[a-f]zu bezeichnen ,[1-5][code> , und so weiter.^es entspricht dem Beginn einer Zeile in einer Datei.$entspricht dem Zeilenende in einer Datei.\es ist ein Fluchtzeichen.
Um Text zu filtern, muss man ein Textfilter-Tool wie awk verwenden . Sie können an awk denken als eigene Programmiersprache. Aber für den Umfang dieser Anleitung zur Verwendung von awk , werden wir es als einfaches Befehlszeilen-Filtertool behandeln.
Die allgemeine Syntax von awk ist:
# awk 'script' filename
Wobei 'script' ist eine Reihe von Befehlen, die von awk verstanden werden und werden auf Datei, Dateiname.
Es funktioniert, indem es eine bestimmte Zeile in der Datei liest, eine Kopie der Zeile erstellt und dann das Skript auf der Zeile ausführt. Dies wird in allen Zeilen der Datei wiederholt.
Das 'Skript' hat die Form '/pattern/ action' wobei Muster ist ein regulärer Ausdruck und die Aktion ist, was awk tun wird, wenn es das angegebene Muster in einer Zeile findet.
Verwendung des Awk-Filtertools unter Linux
In den folgenden Beispielen konzentrieren wir uns auf die Metazeichen, die wir oben unter den Features von awk besprochen haben.
Ein einfaches Beispiel für die Verwendung von awk:
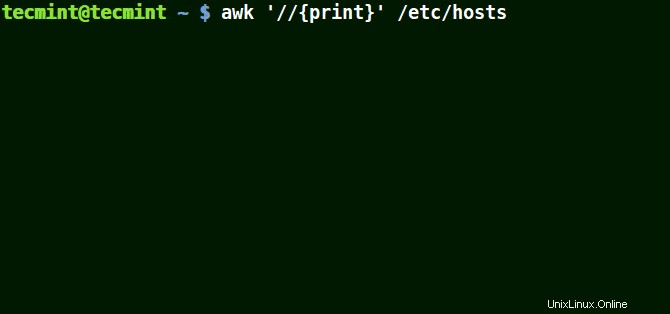
Das folgende Beispiel gibt alle Zeilen in der Datei /etc/hosts aus da kein Muster angegeben ist.
# awk '//{print}'/etc/hosts

Awk mit Muster verwenden:
Ich das Beispiel unten, ein Muster localhost angegeben wurde, also passt awk die Zeile mit localhost an in /etc/hosts Datei.
# awk '/localhost/{print}' /etc/hosts

Awk mit (.) Platzhalter in einem Muster verwenden
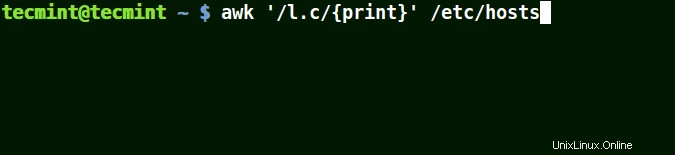
Der (.) findet Strings, die loc enthalten , localhost , Lokalnetz im Beispiel unten.
Das heißt * l irgendein_einzelnes_Zeichen c * .
# awk '/l.c/{print}' /etc/hosts
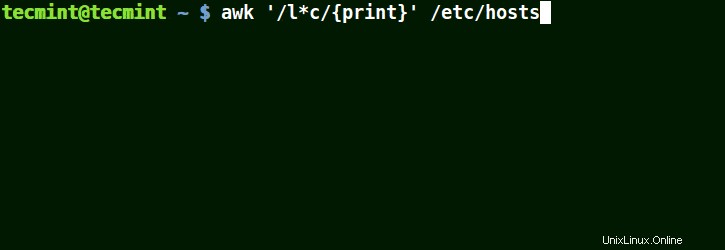
Awk mit (*)-Zeichen in einem Muster verwenden
Es wird mit Strings übereinstimmen, die localhost enthalten , Lokalnetz , Linien , fähig , wie im folgenden Beispiel:
# awk '/l*c/{print}' /etc/localhost
Sie werden auch feststellen, dass (*) versucht, Ihnen die längste mögliche Übereinstimmung zu liefern, die es erkennen kann.
Schauen wir uns einen Fall an, der dies demonstriert, nehmen Sie den regulären Ausdruck t*t was bedeutet, dass Strings übereinstimmen, die mit dem Buchstaben t beginnen und enden mit t in der Zeile darunter:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint.
Sie erhalten die folgenden Möglichkeiten, wenn Sie das Muster /t*t/ verwenden :
this is t this is tecmint this is tecmint, where you get t this is tecmint, where you get the best good t this is tecmint, where you get the best good tutorials, how t this is tecmint, where you get the best good tutorials, how tos, guides, t this is tecmint, where you get the best good tutorials, how tos, guides, tecmint
Und (*) in /t*t/ Platzhalterzeichen erlaubt awk, die letzte Option zu wählen:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint
Awk mit set [ Zeichen ] verwenden
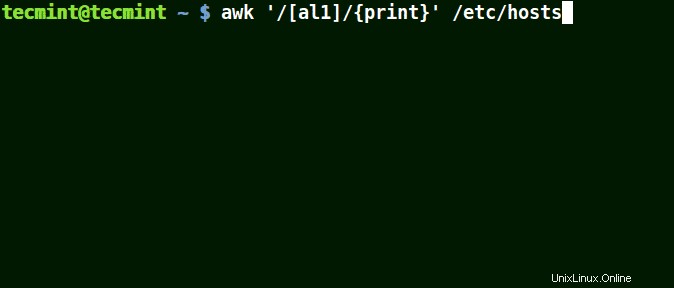
Nehmen Sie zum Beispiel die Menge [al1] , hier findet awk alle Strings, die das Zeichen a enthalten oder l oder 1 in einer Zeile in der Datei /etc/hosts .
# awk '/[al1]/{print}' /etc/hosts
Das nächste Beispiel vergleicht Zeichenfolgen, die entweder mit K beginnen oder k gefolgt von T :
# awk '/[Kk]T/{print}' /etc/hosts

Zeichen in einem Bereich angeben
Zeichen verstehen mit awk:
[0-9][code> bedeutet eine einzelne Zahl[a-z]bedeutet Übereinstimmung mit einem einzelnen Kleinbuchstaben[A-Z]bedeutet Übereinstimmung mit einem einzelnen Großbuchstaben[a-zA-Z]bedeutet Übereinstimmung mit einem einzelnen Buchstaben[a-zA-Z 0-9]bedeutet Übereinstimmung mit einem einzelnen Buchstaben oder einer Ziffer
Sehen wir uns ein Beispiel unten an:
# awk '/[0-9]/{print}' /etc/hosts
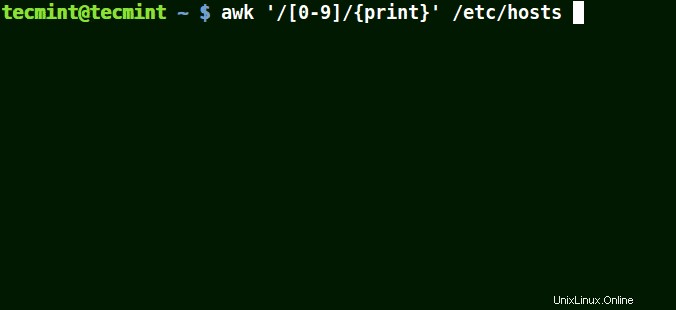
Die gesamte Zeile aus der Datei /etc/hosts mindestens eine einzelne Zahl [0-9] enthalten im obigen Beispiel.
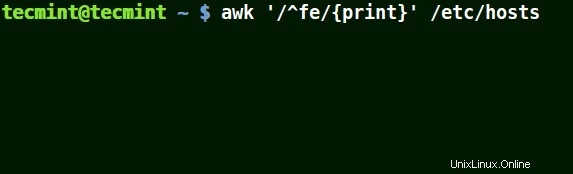
Awk mit (^) Metazeichen verwenden
Es stimmt mit allen Zeilen überein, die mit dem Muster beginnen, das wie im folgenden Beispiel bereitgestellt wird:
# awk '/^fe/{print}' /etc/hosts
# awk '/^ff/{print}' /etc/hosts
Awk mit ($) Metazeichen verwenden
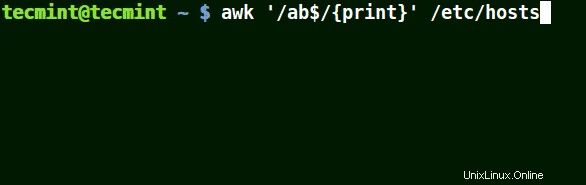
Es stimmt mit allen Zeilen überein, die mit dem bereitgestellten Muster enden:
# awk '/ab$/{print}' /etc/hosts
# awk '/ost$/{print}' /etc/hosts
# awk '/rs$/{print}' /etc/hosts
Verwenden Sie Awk mit (\) Escape-Zeichen
Es erlaubt Ihnen, das folgende Zeichen wörtlich zu nehmen, dh es so zu betrachten, wie es ist.
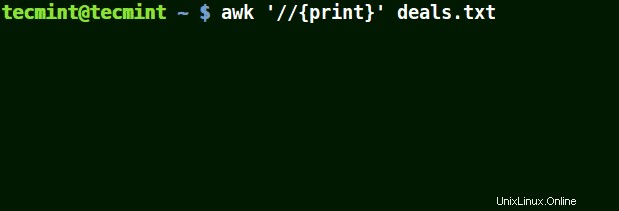
Im Beispiel unten druckt der erste Befehl alle Zeilen in der Datei aus, der zweite Befehl druckt nichts aus, weil ich eine Zeile mit $25,00 abgleichen möchte , aber es wird kein Escape-Zeichen verwendet.
Der dritte Befehl ist korrekt, da ein Escape-Zeichen verwendet wurde, um $ zu lesen wie es ist.
# awk '//{print}' deals.txt
# awk '/$25.00/{print}' deals.txt
# awk '/\$25.00/{print}' deals.txt
Zusammenfassung
Das ist noch nicht alles mit dem awk Befehlszeilenfilter-Tool, die obigen Beispiele zeigen die grundlegenden Operationen von awk. In den nächsten Teilen werden wir uns mit der Verwendung komplexer Funktionen von awk befassen. Vielen Dank für das Durchlesen und für Ergänzungen oder Klarstellungen, posten Sie einen Kommentar im Kommentarbereich.