Die forensische Analyse eines Linux-Festplatten-Images ist oft Teil der Reaktion auf Vorfälle, um festzustellen, ob ein Verstoß aufgetreten ist. Linux-Forensik ist eine andere und faszinierende Welt im Vergleich zu Microsoft Windows-Forensik. In diesem Artikel werde ich ein Disk-Image von einem potenziell kompromittierten Linux-System analysieren, um das Wer, Was, Wann, Wo, Warum und Wie des Vorfalls zu bestimmen und Ereignis- und Dateisystem-Zeitpläne zu erstellen. Schließlich werde ich interessante Artefakte aus dem Disk-Image extrahieren.
In diesem Tutorial werden wir einige neue Tools und einige alte Tools auf kreative, neue Weise verwenden, um eine forensische Analyse eines Disk-Images durchzuführen.
Das Szenario
Weitere Linux-Ressourcen
- Spickzettel für Linux-Befehle
- Spickzettel für fortgeschrittene Linux-Befehle
- Kostenloser Online-Kurs:RHEL Technical Overview
- Spickzettel für Linux-Netzwerke
- SELinux-Spickzettel
- Spickzettel für allgemeine Linux-Befehle
- Was sind Linux-Container?
- Unsere neuesten Linux-Artikel
Premiere Fabrication Engineering (PFE) vermutet, dass es einen Vorfall oder eine Kompromittierung mit dem Hauptserver des Unternehmens namens pfe1 gegeben hat. Sie glauben, dass der Server möglicherweise in einen Vorfall verwickelt war und irgendwann zwischen dem ersten März und dem letzten März kompromittiert wurde. Sie haben meine Dienste als forensischen Prüfer beauftragt, um zu untersuchen, ob der Server kompromittiert und in einen Vorfall verwickelt war. Die Untersuchung wird ermitteln, wer, was, wann, wo, warum und wie hinter der möglichen Kompromittierung steckt. Darüber hinaus hat PFE meine Empfehlungen für weitere Sicherheitsmaßnahmen für ihre Server angefordert.
Das Disk-Image
Um die forensische Analyse des Servers durchzuführen, bitte ich PFE, mir ein forensisches Disk-Image von pfe1 auf einem USB-Laufwerk zuzusenden. Sie stimmen zu und sagen:"Der USB ist in der Post." Das USB-Laufwerk kommt an, und ich beginne, seinen Inhalt zu untersuchen. Zur Durchführung der forensischen Analyse verwende ich eine virtuelle Maschine (VM), auf der die SANS SIFT-Distribution ausgeführt wird. Die SIFT-Workstation ist eine Gruppe kostenloser Open-Source-Incident-Response- und forensischer Tools, die für die Durchführung detaillierter digitaler forensischer Untersuchungen in einer Vielzahl von Umgebungen entwickelt wurden. SIFT hat eine große Auswahl an forensischen Tools, und wenn ich kein Tool habe, kann ich ohne große Schwierigkeiten eines installieren, da es sich um eine Ubuntu-basierte Distribution handelt.
Bei der Untersuchung stelle ich fest, dass der USB kein Disk-Image enthält, sondern Kopien der VMware ESX-Hostdateien, bei denen es sich um VMDK-Dateien aus der Hybrid-Cloud von PFE handelt. Das war nicht das, was ich erwartet hatte. Ich habe mehrere Möglichkeiten:
- Ich kann PFE kontaktieren und deutlicher sagen, was ich von ihnen erwarte. Zu Beginn einer Verlobung wie dieser ist dies möglicherweise nicht die beste Vorgehensweise.
- Ich kann die VMDK-Dateien in ein Virtualisierungstool wie VMPlayer laden und es als Live-VM mit seinen nativen Linux-Programmen ausführen, um forensische Analysen durchzuführen. Es gibt mindestens drei Gründe, dies nicht zu tun. Erstens werden Zeitstempel für Dateien und Dateiinhalte geändert, wenn die VMDK-Dateien als Live-System ausgeführt werden. Da der Server als kompromittiert gilt, müssen zweitens alle Dateien und Programme des VMDK-Dateisystems als kompromittiert betrachtet werden. Drittens kann die Verwendung der nativen Programme auf einem kompromittierten System zur Durchführung einer forensischen Analyse unvorhergesehene Folgen haben.
- Um die VMDK-Dateien zu analysieren, könnte ich das libvmdk-utils-Paket verwenden, das Tools enthält, um auf Daten zuzugreifen, die in VMDK-Dateien gespeichert sind.
- Ein besserer Ansatz besteht jedoch darin, das VMDK-Dateiformat in das RAW-Format zu konvertieren. Dadurch wird es einfacher, die verschiedenen Tools in der SIFT-Distribution auf den Dateien im Disk-Image auszuführen.
Um vom VMDK- in das RAW-Format zu konvertieren, verwende ich das Dienstprogramm qemu-img, mit dem Bilder offline erstellt, konvertiert und geändert werden können. Die folgende Abbildung zeigt den Befehl zum Konvertieren des VMDK-Formats in ein RAW-Format.

Als Nächstes muss ich die Partitionstabelle aus dem Disk-Image auflisten und mithilfe des mmls-Dienstprogramms Informationen darüber abrufen, wo jede Partition beginnt (Sektoren). Dieses Dienstprogramm zeigt das Layout der Partitionen in einem Volume-System an, einschließlich Partitionstabellen und Plattenbezeichnungen. Dann verwende ich den Startsektor und frage die mit dem Dateisystem verknüpften Details mit dem Dienstprogramm fsstat ab, das die mit einem Dateisystem verknüpften Details anzeigt. Die Abbildungen unten zeigen die mmls und fsstat Befehle in Betrieb.
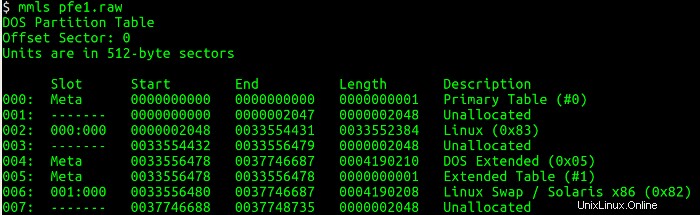
Ich lerne mehrere interessante Dinge aus dem mmls Ausgabe:Eine primäre Linux-Partition beginnt bei Sektor 2048 und ist ungefähr 8 Gigabyte groß. Eine DOS-Partition, wahrscheinlich die Boot-Partition, ist ungefähr 8 Megabyte groß. Schließlich gibt es eine Auslagerungspartition von ungefähr 8 Gigabyte.
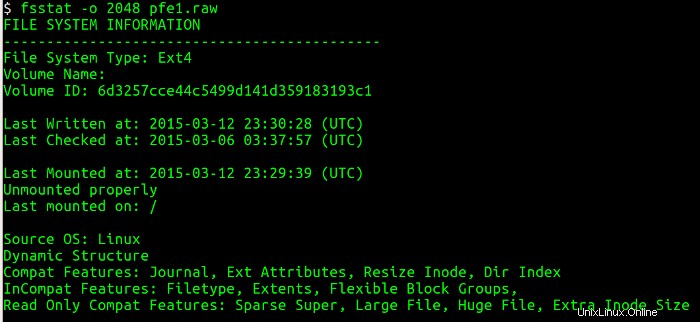
Ausführen von fsstat sagt mir viele nützliche Dinge über die Partition:den Typ des Dateisystems, das letzte Mal, als Daten in das Dateisystem geschrieben wurden, ob das Dateisystem sauber ausgehängt wurde und wo das Dateisystem eingehängt wurde.
Ich bin bereit, die Partition zu mounten und die Analyse zu starten. Dazu muss ich die Partitionstabellen auf dem angegebenen Raw-Image lesen und Gerätezuordnungen über erkannte Partitionssegmente erstellen. Ich könnte das mit den Informationen von mmls von Hand machen und fsstat – oder ich könnte kpartx verwenden, um das für mich zu erledigen.

Ich verwende Optionen, um eine schreibgeschützte Zuordnung zu erstellen (-r ), Partitionszuordnung hinzufügen (-a ) und geben eine ausführliche Ausgabe (-v ). Der loop0p1 ist der Name einer Gerätedatei unter /dev/mapper Ich kann verwenden, um auf die Partition zuzugreifen. Um es zu mounten, führe ich aus:
$ mount -o ro -o loop=/dev/mapper/loop0p1 pf1.raw /mnt
Beachten Sie, dass ich die Partition schreibgeschützt einhänge (-o ro ), um eine versehentliche Kontamination zu verhindern.
Nachdem ich die Festplatte gemountet habe, beginne ich meine forensische Analyse und Untersuchung, indem ich eine Zeitachse erstelle. Einige forensische Prüfer glauben nicht an die Erstellung einer Zeitleiste. Stattdessen kriechen sie, sobald sie eine Partition gemountet haben, durch das Dateisystem und suchen nach Artefakten, die für die Untersuchung relevant sein könnten. Ich bezeichne diese forensischen Prüfer als „Schleichlinge“. Auch wenn dies eine Möglichkeit zur forensischen Untersuchung ist, ist sie alles andere als wiederholbar, fehleranfällig und kann wertvolle Beweise übersehen.
Ich glaube, dass das Erstellen einer Zeitleiste ein entscheidender Schritt ist, da sie nützliche Informationen über Dateien enthält, die in einem für Menschen lesbaren Format geändert, abgerufen, geändert und erstellt wurden, bekannt als MAC-Zeitnachweise (modifiziert, abgerufen, geändert). Diese Aktivität hilft dabei, den genauen Zeitpunkt und die Reihenfolge zu ermitteln, in der ein Ereignis stattfand.
Hinweise zu Linux-Dateisystemen
Linux-Dateisysteme wie ext2 und ext3 haben keine Zeitstempel für die Erstellung/Geburtszeit einer Datei. Der Erstellungszeitstempel wurde in ext4 eingeführt. Das BuchForensic Discovery (1. Auflage) von Dan Farmer und Wietse Venema umreißt die verschiedenen Zeitstempel.
- Letzte Änderungszeit: Bei Verzeichnissen ist dies das letzte Mal, dass ein Eintrag hinzugefügt, umbenannt oder entfernt wurde. Bei anderen Dateitypen ist es das letzte Mal, dass in die Datei geschrieben wurde.
- Zeitpunkt des letzten Zugriffs (Lesens): Bei Verzeichnissen ist dies die letzte Suche. Bei anderen Dateitypen ist es das letzte Mal, dass die Datei gelesen wurde.
- Letzte Statusänderung: Beispiele für Statusänderungen sind Eigentümerwechsel, Änderung der Zugriffsberechtigung, Änderung der Hardlink-Anzahl oder eine explizite Änderung einer der MAC-Zeiten.
- Löschzeitpunkt: ext2 und ext3 zeichnen den Zeitpunkt auf, zu dem eine Datei in
dtimegelöscht wurde timestamp, aber nicht alle Tools unterstützen dies. - Erstellungszeit: ext4fs zeichnet die Zeit auf, zu der die Datei in
crtimeerstellt wurde timestamp, aber nicht alle Tools unterstützen dies.
Die unterschiedlichen Zeitstempel werden in den in den Inodes enthaltenen Metadaten gespeichert. Inodes ähneln der MFT-Eintragsnummer in der Windows-Welt. Eine Möglichkeit, die Dateimetadaten auf einem Linux-System zu lesen, besteht darin, zuerst die Inode-Nummer mit dem Befehl ls -i file abzurufen Verwenden Sie dann istat gegen das Partitionsgerät und geben Sie die Inode-Nummer an. Dies zeigt Ihnen die verschiedenen Metadatenattribute, einschließlich Zeitstempel, Dateigröße, Eigentümergruppe und Benutzer-ID, Berechtigungen und die Blöcke, die die eigentlichen Daten enthalten.
Erstellung der Super-Timeline
Mein nächster Schritt ist die Erstellung einer Super-Timeline mit log2timeline/plaso. Plaso ist eine Python-basierte Neufassung des Perl-basierten log2timeline-Tools, das ursprünglich von Kristinn Gudjonsson erstellt und von anderen verbessert wurde. Es ist einfach, mit log2timeline eine super Zeitleiste zu erstellen, aber die Interpretation ist schwierig. Die neueste Version der Plaso-Engine kann ext4 sowie verschiedene Arten von Artefakten wie Syslog-Nachrichten, Audit, utmp und andere parsen.
Um die Super-Timeline zu erstellen, starte ich log2timeline für den bereitgestellten Festplattenordner und verwende die Linux-Parser. Dieser Vorgang dauert einige Zeit; Wenn es fertig ist, habe ich eine Zeitleiste mit den verschiedenen Artefakten im Plaso-Datenbankformat, dann kann ich psort.py verwenden die Plaso-Datenbank in beliebig viele verschiedene Ausgabeformate zu konvertieren. Um die Ausgabeformate anzuzeigen, die psort.py unterstützt, geben Sie psort -o list ein . Ich habe psort.py verwendet um eine Super-Timeline im Excel-Format zu erstellen. Die folgende Abbildung zeigt die Schritte zur Durchführung dieses Vorgangs.

(Hinweis:Überflüssige Linien aus Bildern entfernt)

Ich importiere die Super-Timeline in ein Tabellenkalkulationsprogramm, um das Anzeigen, Sortieren und Suchen zu vereinfachen. Während Sie eine Super-Timeline in einem Tabellenkalkulationsprogramm anzeigen können, ist es einfacher, damit in einer echten Datenbank wie MySQL oder Elasticsearch zu arbeiten. Ich erstelle eine zweite Super-Timeline und sende sie von psort.py direkt an eine Elasticsearch-Instanz . Sobald die Super-Timeline von Elasticsearch indiziert wurde, kann ich die Daten mit Kibana visualisieren und analysieren.

Untersuchung mit Elasticsearch/Kibana
Wie Master Sergeant Farrell sagte:„Durch Bereitschaft und Disziplin sind wir Meister unseres Schicksals.“ Bei der Analyse lohnt es sich, geduldig und akribisch zu sein und keine Kriechpflanze zu sein. Eine Sache, die einer Super-Timeline-Analyse hilft, ist, eine Vorstellung davon zu haben, wann der Vorfall passiert sein könnte. In diesem Fall (Wortspiel beabsichtigt) sagt der Kunde, dass der Vorfall möglicherweise im März passiert ist. Ich halte immer noch die Möglichkeit für möglich, dass der Kunde in Bezug auf den Zeitrahmen falsch liegt. Bewaffnet mit diesen Informationen beginne ich, den Zeitrahmen der Super-Timeline zu reduzieren und einzugrenzen. Ich suche nach interessanten Artefakten, die eine "zeitliche Nähe" zum mutmaßlichen Datum des Vorfalls haben. Das Ziel ist es, anhand verschiedener Artefakte nachzubilden, was passiert ist.
Um den Umfang der Super-Timeline einzugrenzen, verwende ich die von mir eingerichtete Elasticsearch/Kibana-Instance. Mit Kibana kann ich eine beliebige Anzahl komplizierter Dashboards einrichten, um relevante forensische Ereignisse anzuzeigen und zu korrelieren, aber ich möchte dieses Maß an Komplexität vermeiden. Stattdessen wähle ich interessante Indizes zur Anzeige aus und erstelle ein Balkendiagramm der Aktivität nach Datum:
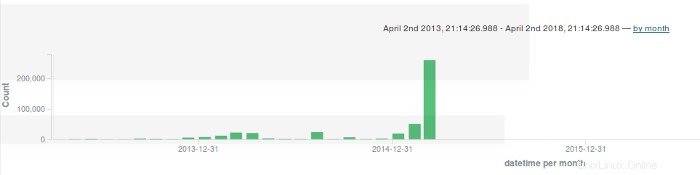
Der nächste Schritt besteht darin, den großen Balken am Ende des Diagramms zu erweitern:

Am 5. März gibt es eine große Bar. Ich erweitere diese Leiste, um die Aktivität an diesem bestimmten Datum anzuzeigen:
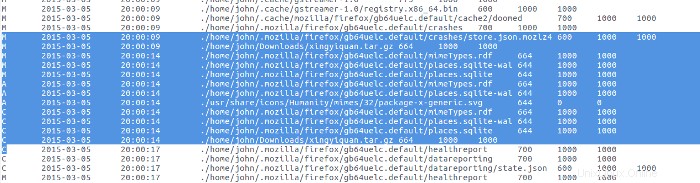
Wenn ich mir die Protokolldateiaktivität aus der Super-Timeline ansehe, sehe ich, dass diese Aktivität von einer Softwareinstallation/-aktualisierung herrührt. In diesem Tätigkeitsbereich ist sehr wenig zu finden.
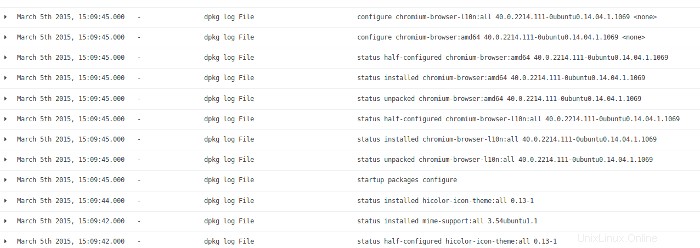
Ich gehe zurück zu Kibana, um die letzten Aktivitäten auf dem System anzuzeigen, und finde dies in den Protokollen:
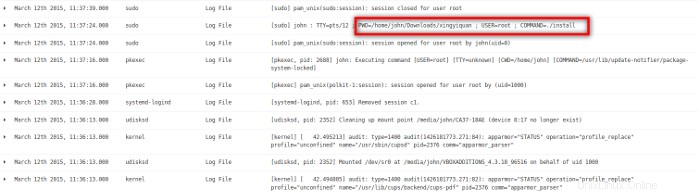
Eine der letzten Aktivitäten auf dem System war, dass Benutzer John ein Programm aus einem Verzeichnis namens xingyiquan installierte. Xing Yi Quan ist eine chinesische Kampfkunst, die Kung Fu und Tai Chi Quan ähnelt. Es scheint seltsam, dass Benutzer John ein Kampfsportprogramm von seinem eigenen Benutzerkonto auf einem Firmenserver installiert. Ich verwende die Suchfunktion von Kibana, um andere Instanzen von xingyiquan in den Protokolldateien zu finden. Ich habe am 5. März, 9. März und 12. März drei Aktivitätsperioden rund um die Schnur Xingyiquan gefunden.

Als nächstes schaue ich mir die Protokolleinträge für diese Tage an. Ich beginne mit 05-Mar und finde Hinweise auf eine Internetsuche mit dem Firefox-Browser und der Google-Suchmaschine nach einem Rootkit namens xingyiquan. Die Google-Suche fand die Existenz eines solchen Rootkits auf packetstormsecurity.com. Dann ging der Browser zu packetstormsecurity.com und lud eine Datei namens xingyiquan.tar.gz herunter von dieser Seite in das Download-Verzeichnis von Benutzer John.
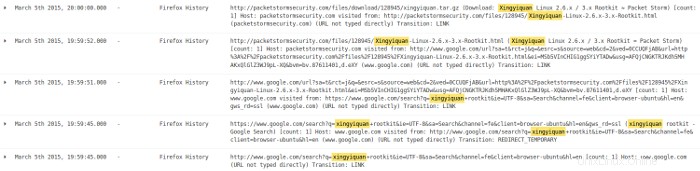
Obwohl es den Anschein hat, dass Benutzer John zu google.com gegangen ist, um nach dem Rootkit zu suchen, und dann zu packetstormsecurity.com, um das Rootkit herunterzuladen, geben diese Protokolleinträge nicht den Benutzer an, der hinter der Suche und dem Download steht. Ich muss das genauer untersuchen.
Der Firefox-Browser speichert seine Verlaufsinformationen in einer SQLite-Datenbank unter .mozilla Verzeichnis im Home-Verzeichnis eines Benutzers (z. B. Benutzer john) in einer Datei namens places.sqlite . Um die Informationen in der Datenbank anzuzeigen, verwende ich ein Programm namens sqlitebrowser. Es ist eine GUI-Anwendung, die es einem Benutzer ermöglicht, einen Drilldown in eine SQLite-Datenbank durchzuführen und die dort gespeicherten Datensätze anzuzeigen. Ich habe sqlitebrowser gestartet und places.sqlite importiert aus der .mozilla Verzeichnis unter dem Home-Verzeichnis von Benutzer john. Die Ergebnisse werden unten angezeigt.

Die Zahl in der Spalte ganz rechts ist der Zeitstempel für die Aktivität auf der linken Seite. Als Kongruenztest habe ich den Zeitstempel 1425614413880000 konvertiert zur menschlichen Zeit und erhielt den 5. März 2015, 20:00:13.880 Uhr. Dies stimmt genau mit der Zeit vom 5. März 2015, 20:00:00.000 von Kibana überein. Wir können mit ziemlicher Sicherheit sagen, dass Benutzer John nach einem Rootkit namens xingyiquan gesucht und eine Datei namens xingyiquan.tar.gz von packetstormsecurity.com heruntergeladen hat in das Download-Verzeichnis von Benutzer john.
Untersuchung mit MySQL
An diesem Punkt beschließe ich, die Super-Timeline in eine MySQL-Datenbank zu importieren, um eine größere Flexibilität bei der Suche und Bearbeitung von Daten zu erhalten, als es Elasticsearch/Kibana allein zulässt.
Erstellung des Xingyiquan-Rootkits
Ich lade die Super-Timeline, die ich aus der Plaso-Datenbank erstellt habe, in eine MySQL-Datenbank. Aus der Arbeit mit Elasticsearch/Kibana weiß ich, dass Benutzer john das Rootkit xingyiquan.tar.gz heruntergeladen hat von packetstormsecurity.com in das Download-Verzeichnis. Hier ist ein Beweis für die Download-Aktivität aus der MySQL-Timeline-Datenbank:
Kurz nachdem das Rootkit heruntergeladen wurde, wird die Quelle aus der tar.gz Archiv wurde entpackt.
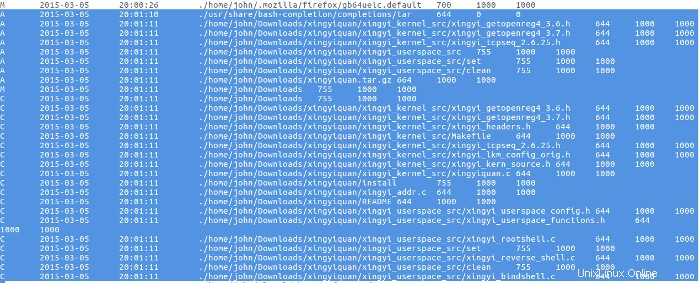
Mit dem Rootkit wurde bis zum 9. März nichts unternommen, als der Bösewicht die README-Datei für das Rootkit mit dem More-Programm las, dann das Rootkit kompilierte und installierte.
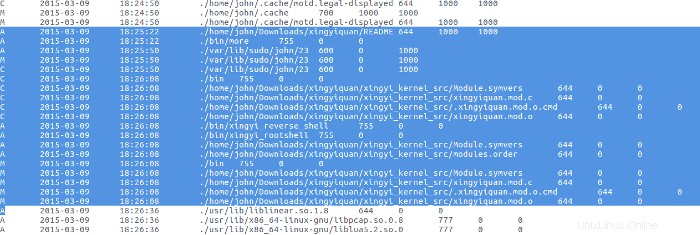
Befehlsverläufe
Ich lade die Historien aller Benutzer auf pfe1, die bash haben Befehlsverläufe in eine Tabelle in der MySQL-Datenbank. Sobald die Verläufe geladen sind, kann ich sie ganz einfach mit einer Abfrage wie der folgenden anzeigen:
select * from histories order by recno; Um einen Verlauf für einen bestimmten Benutzer zu erhalten, verwende ich eine Abfrage wie:
select historyCommand from histories where historyFilename like '%<username>%' order by recno;
Ich finde einige interessante Befehle aus Benutzer Johns bash Geschichte. Benutzer john hat nämlich das johnn-Konto erstellt, gelöscht, neu erstellt, /bin/true kopiert nach /bin/false , den whoopsie- und lightdm-Konten Passwörter gegeben, /bin/bash kopiert nach /bin/false , die Passwort- und Gruppendateien bearbeitet, das Home-Verzeichnis des Benutzers johnn von johnn verschoben zu .johnn , (was es zu einem versteckten Verzeichnis macht), hat die Passwortdatei mit sed geändert nachdem Sie nachgeschlagen haben, wie man
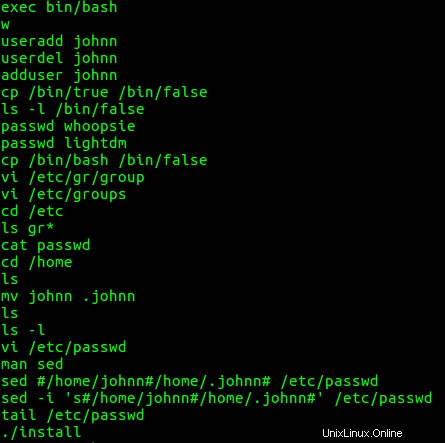
Als nächstes schaue ich mir die bash an Befehlsverlauf für Benutzer johnn. Es zeigte keine ungewöhnliche Aktivität.
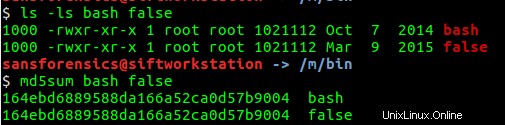
Beachten Sie, dass Benutzer john /bin/bash kopiert hat nach /bin/false , teste ich, ob dies zutrifft, indem ich die Größe dieser Dateien überprüfe und einen MD5-Hash der Dateien erhalte. Wie unten gezeigt, sind die Dateigrößen und die MD5-Hashes gleich. Somit sind die Dateien gleich.
Erfolgreiche und fehlgeschlagene Anmeldungen untersuchen
Um einen Teil der "Wann"-Frage zu beantworten, lade ich die Protokolldateien mit Daten zu Anmeldungen, Abmeldungen, Systemstarts und -abschaltungen in eine Tabelle in der MySQL-Datenbank. Verwenden Sie eine einfache Abfrage wie:
select * from logins order by start Ich finde die folgende Aktivität:

In dieser Abbildung sehe ich, dass sich Benutzer john von der IP-Adresse 192.168.56.1 bei pfe1 angemeldet hat . Fünf Minuten später meldete sich Benutzer johnn mit derselben IP-Adresse bei pfe1 an. Zwei Anmeldungen von Benutzer lightdm folgten vier Minuten später und eine weitere eine Minute später, dann meldete sich Benutzer johnn weniger als eine Minute später an. Dann wurde pfe1 neu gestartet.
Wenn ich mir erfolglose Anmeldungen ansehe, finde ich diese Aktivität:

Erneut hat der Benutzer lightdm versucht, sich über die IP-Adresse 192.168.56.1 bei pfe1 anzumelden . Angesichts der gefälschten Konten, die sich bei pfe1 anmelden, wird eine meiner Empfehlungen an PFE darin bestehen, das System mit der IP-Adresse 192.168.56.1 zu überprüfen für Beweise der Kompromittierung.
Logdateien untersuchen
Diese Analyse erfolgreicher und fehlgeschlagener Anmeldungen liefert wertvolle Informationen darüber, wann Ereignisse aufgetreten sind. Ich richte meine Aufmerksamkeit auf die Untersuchung der Protokolldateien auf pfe1, insbesondere der Authentifizierungs- und Autorisierungsaktivität in /var/log/auth* . Ich lade alle Protokolldateien auf pfe1 in eine MySQL-Datenbanktabelle und verwende eine Abfrage wie:
select logentry from logs where logfilename like '%auth%' order by recno;
und speichere das in einer Datei. Ich öffne diese Datei mit meinem bevorzugten Editor und suche nach 192.168.56.1 . Es folgt ein Abschnitt der Aktivität:
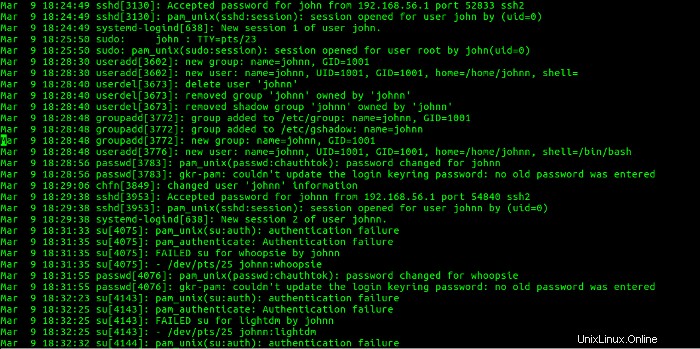
Dieser Abschnitt zeigt, dass sich Benutzer john von der IP-Adresse 192.168.56.1 angemeldet hat und erstellte das johnn-Konto, entfernte das johnn-Konto und erstellte es erneut. Dann meldete sich Benutzer johnn bei pfe1 von der IP-Adresse 192.168.56.1 an . Als nächstes versuchte Benutzer johnn, mit einem su zum Benutzer whoopsie zu werden Befehl, der fehlgeschlagen ist. Dann wurde das Passwort für den Benutzer whoopsie geändert. Benutzer johnn versuchte als nächstes, Benutzer lightdm mit einem su zu werden Befehl, der ebenfalls fehlschlug. Dies korreliert mit der in den Abbildungen 21 und 22 gezeigten Aktivität.
Schlussfolgerungen aus meiner Untersuchung
- Benutzer john hat ein Rootkit namens xingyiquan auf dem Server pfe1 gesucht, heruntergeladen, kompiliert und installiert. Das Xingyiquan-Rootkit verbirgt Prozesse, Dateien, Verzeichnisse, Prozesse und Netzwerkverbindungen; fügt Hintertüren hinzu; und mehr.
- Benutzer john hat ein weiteres Konto auf pfe1 mit dem Namen johnn erstellt, gelöscht und neu erstellt. Benutzer john hat das Home-Verzeichnis von Benutzer johnn zu einer versteckten Datei gemacht, um die Existenz dieses Benutzerkontos zu verschleiern.
- Benutzer john hat die Datei
/bin/truekopiert über/bin/falseund dann/bin/bashüber/bin/falseum die Anmeldung von Systemkonten zu erleichtern, die normalerweise nicht für interaktive Anmeldungen verwendet werden. - Benutzer john hat Passwörter für die Systemkonten whoopsie und lightdm erstellt. Diese Konten haben normalerweise keine Passwörter.
- Das Benutzerkonto johnn wurde erfolgreich angemeldet und Benutzer johnn hat erfolglos versucht, Benutzer whoopsie und lightdm zu werden.
- Server pfe1 wurde ernsthaft kompromittiert.
Meine Empfehlungen an PFE
- Erstellen Sie den Server pfe1 aus der ursprünglichen Distribution neu und wenden Sie alle relevanten Patches auf das System an, bevor Sie es wieder in Betrieb nehmen.
- Richten Sie einen zentralisierten Syslog-Server ein und lassen Sie alle Systeme in der PFE-Hybrid-Cloud auf dem zentralisierten Syslog-Server und protokollieren zu lokalen Protokollen, um Protokolldaten zu konsolidieren und Manipulationen an Systemprotokollen zu verhindern. Verwenden Sie ein SIEM-Produkt (Security Information and Event Monitoring), um die Überprüfung und Korrelation von Sicherheitsereignissen zu erleichtern.
- Implementieren Sie
bashBefehlszeitstempel auf allen Unternehmensservern. - Aktivieren Sie die Audit-Protokollierung des Root-Kontos auf allen PFE-Servern und leiten Sie die Audit-Protokolle an den zentralen Syslog-Server weiter, wo sie mit anderen Protokollinformationen korreliert werden können.
- Untersuchen Sie das System mit der IP-Adresse
192.168.56.1für Verstöße und Kompromittierungen, da es als Dreh- und Angelpunkt bei der Kompromittierung von pfe1 verwendet wurde.
Wenn Sie Forensik zur Analyse Ihres Linux-Dateisystems auf Kompromittierungen verwendet haben, teilen Sie uns bitte Ihre Tipps und Empfehlungen in den Kommentaren mit.
Gary Smith wird dieses Jahr beim LinuxFest Northwest sprechen. Sehen Sie sich die Programmhighlights an oder melden Sie sich für die Teilnahme an.