
In diesem Tutorial zeigen wir Ihnen, wie Sie Apache Hadoop auf Debian 11 installieren. Für diejenigen unter Ihnen, die es nicht wussten, Apache Hadoop ist eine Java-basierte Open-Source-Softwareplattform das die Datenverarbeitung und -speicherung für Big-Data-Anwendungen verwaltet. Es wurde entwickelt, um von einzelnen Servern auf Tausende von Computern zu skalieren, die jeweils lokale Rechen- und Speicherfunktionen bieten.
Dieser Artikel geht davon aus, dass Sie zumindest über Grundkenntnisse in Linux verfügen, wissen, wie man die Shell verwendet, und vor allem, dass Sie Ihre Website auf Ihrem eigenen VPS hosten. Die Installation ist recht einfach und setzt Sie voraus im Root-Konto ausgeführt werden, wenn nicht, müssen Sie möglicherweise 'sudo hinzufügen ‘ zu den Befehlen, um Root-Rechte zu erhalten. Ich zeige Ihnen Schritt für Schritt die Installation des Apache Hadoop auf einem Debian 11 (Bullseye).
Voraussetzungen
- Ein Server, auf dem eines der folgenden Betriebssysteme ausgeführt wird:Debian 11 (Bullseye).
- Es wird empfohlen, dass Sie eine neue Betriebssysteminstallation verwenden, um potenziellen Problemen vorzubeugen.
- SSH-Zugriff auf den Server (oder öffnen Sie einfach das Terminal, wenn Sie sich auf einem Desktop befinden).
- Ein
non-root sudo useroder Zugriff auf denroot user. Wir empfehlen, alsnon-root sudo userzu agieren , da Sie Ihr System beschädigen können, wenn Sie als Root nicht aufpassen.
Installieren Sie Apache Hadoop auf Debian 11 Bullseye
Schritt 1. Bevor wir Software installieren, ist es wichtig sicherzustellen, dass Ihr System auf dem neuesten Stand ist, indem Sie das folgende apt ausführen Befehle im Terminal:
sudo apt-Updatesudo apt-Upgrade
Schritt 2. Java installieren.
Apache Hadoop ist eine Java-basierte Anwendung. Daher müssen Sie Java auf Ihrem System installieren:
sudo apt install default-jdk default-jre
Überprüfen Sie die Java-Installation:
Java-Version
Schritt 3. Hadoop-Benutzer erstellen.
Führen Sie den folgenden Befehl aus, um einen neuen Benutzer mit dem Namen Hadoop zu erstellen:
adduser hadoop
Wechseln Sie als Nächstes zum Hadoop-Benutzer, sobald der Benutzer erstellt wurde:
su - hadoop
Jetzt ist es an der Zeit, einen ssh-Schlüssel zu generieren, da Hadoop ssh-Zugriff benötigt, um seinen Knoten, Remote- oder lokalen Computer zu verwalten, also konfigurieren wir für unseren einzelnen Knoten des Setups von Hadoop es so, dass wir Zugriff auf den localhost haben:
ssh-keygen -t rsa
Geben Sie danach der Datei "authorized_keys" die Berechtigung:
cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keyschmod 0600 ~/.ssh/authorized_keys
Überprüfen Sie dann die passwortlose SSH-Verbindung mit dem folgenden Befehl:
ssh Ihre Server-IP-Adresse
Schritt 4. Installieren von Apache Hadoop auf Debian 11.
Wechseln Sie zuerst zum Hadoop-Benutzer und laden Sie die neueste Version von Hadoop von der offiziellen Seite mit dem folgenden wget herunter Befehl:
su - hadoopwget https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.1/hadoop-3.3.1-src.tar.gz
Extrahieren Sie als Nächstes die heruntergeladene Datei mit dem folgenden Befehl:
tar -xvzf hadoop-3.3.1.tar.gz
Ändern Sie nach dem Entpacken das aktuelle Verzeichnis in den Hadoop-Ordner:
su rootcd /home/hadoopmv hadoop-3.3.1 /usr/local/hadoop
Erstellen Sie als Nächstes mit dem folgenden Befehl ein Verzeichnis zum Speichern von Protokollen:
mkdir /usr/local/hadoop/logs
Ändern Sie den Besitz des Hadoop-Verzeichnisses in Hadoop:
chown -R hadoop:hadoop /usr/local/hadoopsu hadoop
Danach konfigurieren wir die Hadoop-Umgebungsvariablen:
nano ~/.bashrc
Fügen Sie die folgende Konfiguration hinzu:
export HADOOP_HOME =/ usr / local / hadoopexport HADOOP_INSTALL =$ HADOOP_HOMEexport HADOOP_MAPRED_HOME =$ HADOOP_HOMEexport HADOOP_COMMON_HOME =$ HADOOP_HOMEexport HADOOP_HDFS_HOME =$ HADOOP_HOMEexport YARN_HOME =$ HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR =$ HADOOP_HOME / lib / nativeexport PATH =$ PATH:$ HADOOP_HOME / sbin:$HADOOP_HOME/binexport HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Speichern und schließen Sie die Datei. Aktivieren Sie dann die Umgebungsvariablen:
source ~/.bashrc
Schritt 5. Konfigurieren Sie Apache Hadoop.
- Java-Umgebungsvariablen konfigurieren:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Fügen Sie die folgende Konfiguration hinzu:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
Als nächstes müssen wir die Javax-Aktivierungsdatei herunterladen:
cd /usr/local/hadoop/libsudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jarÜberprüfen Sie die Apache Hadoop-Version:
Hadoop-VersionAusgabe:
Hadoop 3.3.1
- Konfigurieren Sie die Datei core-site.xml:
nano $HADOOP_HOME/etc/hadoop/core-site.xml
Fügen Sie die folgende Datei hinzu:
fs.default.name hdfs://0.0.0.0:9000 Der Standard-Dateisystem-URI
- Datei hdfs-site.xml konfigurieren:
Erstellen Sie vor der Konfiguration ein Verzeichnis zum Speichern von Knotenmetadaten:
mkdir -p /home/hadoop/hdfs/{namenode,datanode}chown -R hadoop:hadoop /home/hadoop/hdfs Bearbeiten Sie als Nächstes die hdfs-site.xml Datei und definieren Sie den Speicherort des Verzeichnisses:
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Fügen Sie die folgende Zeile hinzu:
dfs.replication 1 dfs.name.dir file :///home/hadoop/hdfs/namenode dfs.data.dir file:///home/hadoop/hdfs/datanode
- Datei mapred-site.xml konfigurieren:
Jetzt bearbeiten wir die mapred-site.xml Datei:
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Fügen Sie die folgende Konfiguration hinzu:
mapreduce.framework.name yarn
- Garn-Site.xml-Datei konfigurieren:
Sie müssten die yarn-site.xml bearbeiten Datei und definieren Sie YARN-bezogene Einstellungen:
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Fügen Sie die folgende Konfiguration hinzu:
yarn.nodemanager.aux-services mapreduce_shuffle
- HDFS-NameNode formatieren.
Führen Sie den folgenden Befehl aus, um den Hadoop-Namenode zu formatieren:
HDFS-Namenode-Format
- Starten Sie den Hadoop-Cluster.
Jetzt starten wir NameNode und DataNode mit dem folgenden Befehl unten:
start-dfs.sh
Starten Sie als Nächstes die YARN-Ressourcen- und -Knotenmanager:
start-yarn.sh
Du kannst sie jetzt mit dem folgenden Befehl überprüfen:
jps
Ausgabe:
hadoop@idroot.us:~$ jps58000 NameNode54697 DataNode55365 ResourceManager55083 SecondaryNameNode58556 Jps55365 NodeManager
Schritt 6. Zugriff auf die Hadoop-Webschnittstelle.
Öffnen Sie nach erfolgreicher Installation Ihren Webbrowser und greifen Sie über die URL http://your-server-ip-address:9870 auf Apache Hadoop zu . Sie werden zur Hadoop-Weboberfläche weitergeleitet:
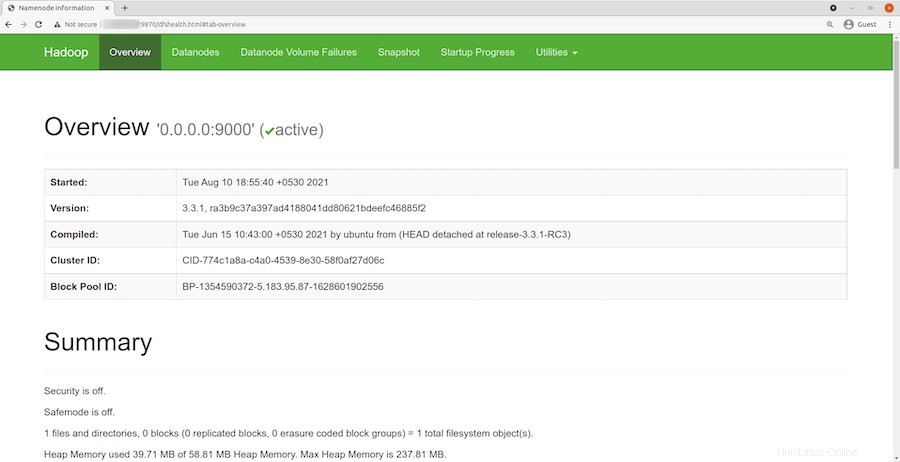
Navigieren Sie zu Ihrer Localhost-URL oder IP, um auf einzelne DataNodes zuzugreifen:http://your-server-ip-address:9864
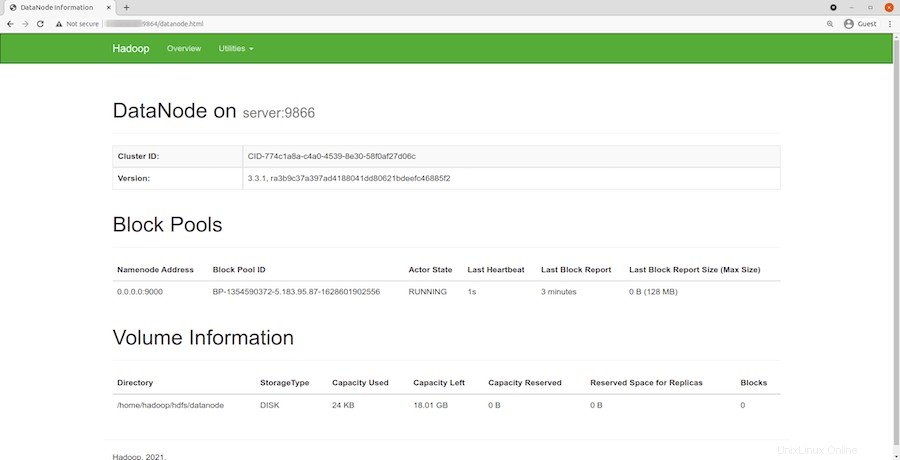
Um auf den YARN-Ressourcenmanager zuzugreifen, verwenden Sie die URL http://your-server-ip-adddress:8088 . Sie sollten den folgenden Bildschirm sehen:
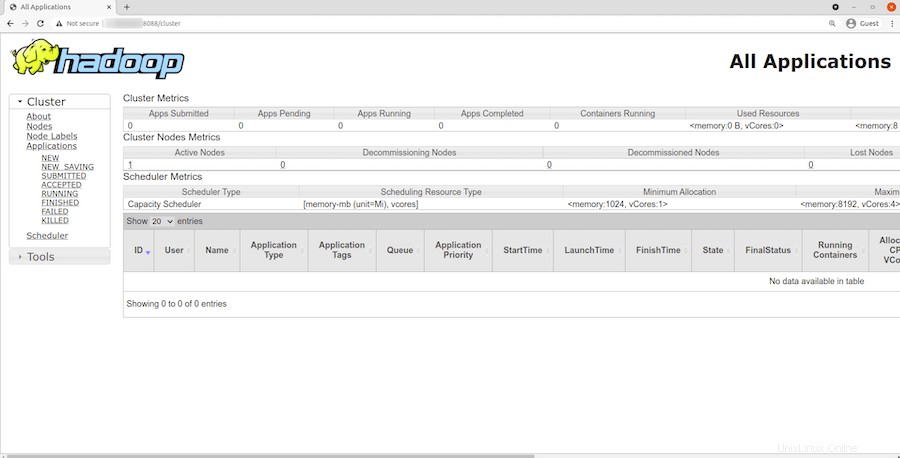
Herzlichen Glückwunsch! Sie haben Hadoop erfolgreich installiert. Vielen Dank, dass Sie dieses Tutorial zur Installation der neuesten Version von Apache Hadoop auf Debian 11 Bullseye verwendet haben. Für zusätzliche Hilfe oder nützliche Informationen empfehlen wir Ihnen, die offizielle Apache Webseite.