Was ist Apache Kafka?
Kafka ist ein Messaging-System, das umfangreiche Datenmengen in Echtzeit sammelt und verarbeitet, was es zu einer wichtigen Integrationskomponente für Anwendungen macht, die in einem Kubernetes-Cluster ausgeführt werden. Die Effizienz von Anwendungen, die in einem Cluster bereitgestellt werden, kann mit einer Event-Streaming-Plattform wie Apache Kafka weiter gesteigert werden .
Dieses ausführliche Tutorial zeigt Ihnen, wie Sie einen Kafka-Server in einem Kubernetes-Cluster konfigurieren.

Wie funktioniert Apache Kafka?
Apache Kafka basiert auf einem Publish-Subscribe-Modell:
- Produzenten Nachrichten erstellen und zu Themen veröffentlichen .
- Kafka kategorisiert die Nachrichten in Themen und speichert sie unveränderlich.
- Verbraucher abonnieren ein bestimmtes Thema und absorbieren die von den Produzenten bereitgestellten Nachrichten.
Produzenten und Konsumenten stellen in diesem Kontext Anwendungen dar, die ereignisgesteuerte Nachrichten produzieren, und Anwendungen, die diese Nachrichten konsumieren. Die Nachrichten werden auf Kafka-Brokern gespeichert, sortiert nach benutzerdefinierten Themen .
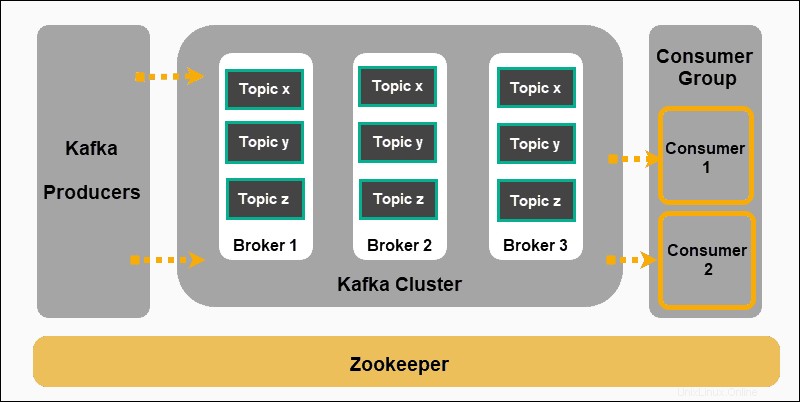
Zookeeper ist ein unverzichtbarer Bestandteil einer Kafka-Konfiguration. Es koordiniert Kafka-Produzenten, Broker, Verbraucher und Cluster-Mitgliedschaften.
Zookeeper einsetzen
Kafka kann ohne Zookeeper nicht funktionieren. Der Kafka-Dienst wird so lange neu gestartet, bis eine funktionierende Zookeeper-Bereitstellung erkannt wird.
Stellen Sie Zookeeper vorher bereit, indem Sie eine YAML-Datei zookeeper.yml erstellen . Diese Datei startet einen Dienst und eine Bereitstellung, die Zookeeper-Pods in einem Kubernetes-Cluster planen.
Verwenden Sie Ihren bevorzugten Texteditor, um die folgenden Felder zu zookeeper.yml hinzuzufügen :
apiVersion: v1
kind: Service
metadata:
name: zk-s
labels:
app: zk-1
spec:
ports:
- name: client
port: 2181
protocol: TCP
- name: follower
port: 2888
protocol: TCP
- name: leader
port: 3888
protocol: TCP
selector:
app: zk-1
---
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: zk-deployment-1
spec:
template:
metadata:
labels:
app: zk-1
spec:
containers:
- name: zk1
image: bitnami/zookeeper
ports:
- containerPort: 2181
env:
- name: ZOOKEEPER_ID
value: "1"
- name: ZOOKEEPER_SERVER_1
value: zk1
Führen Sie den folgenden Befehl auf Ihrem Kubernetes-Cluster aus, um die Definitionsdatei zu erstellen:
kubectl create -f zookeeper.ymlKafka-Dienst erstellen
Wir müssen jetzt eine Kafka-Service-Definitionsdatei erstellen. Diese Datei verwaltet Kafka Broker-Bereitstellungen durch Lastenausgleich für neue Kafka-Pods. Eine grundlegende kafka-service.yml Datei enthält die folgenden Elemente:
apiVersion: v1
kind: Service
metadata:
labels:
app: kafkaApp
name: kafka
spec:
ports:
-
port: 9092
targetPort: 9092
protocol: TCP
-
port: 2181
targetPort: 2181
selector:
app: kafkaApp
type: LoadBalancer
Nachdem Sie die Datei gespeichert haben, erstellen Sie den Dienst, indem Sie den folgenden Befehl eingeben:
kubectl create -f kafka-service.ymlKafka-Replikationscontroller definieren
Erstellen Sie eine zusätzliche .yml Datei, die als Replikationscontroller für Kafka dient. Eine Replikations-Controller-Datei, in unserem Beispiel kafka-repcon.yml, enthält die folgenden Felder:
---
apiVersion: v1
kind: ReplicationController
metadata:
labels:
app: kafkaApp
name: kafka-repcon
spec:
replicas: 1
selector:
app: kafkaApp
template:
metadata:
labels:
app: kafkaApp
spec:
containers:
-
command:
- zookeeper-server-start.sh
- /config/zookeeper.properties
image: "wurstmeister/kafka"
name: zk1
ports:
-
containerPort: 2181
Speichern Sie die Replikationscontroller-Definitionsdatei und erstellen Sie sie mit dem folgenden Befehl:
kubectl create -f kafka-repcon.ymlKafka-Server starten
Die Konfigurationseigenschaften für einen Kafka-Server werden in config/server.properties definiert Datei. Da wir den Zookeeper-Server bereits konfiguriert haben, starten Sie den Kafka-Server mit:
kafka-server-start.sh config/server.propertiesSo erstellen Sie ein Kafka-Thema
Kafka verfügt über ein Befehlszeilenprogramm namens kafka-topics.sh . Verwenden Sie dieses Dienstprogramm, um Themen auf dem Server zu erstellen. Öffnen Sie ein neues Terminalfenster und geben Sie Folgendes ein:
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic Topic-NameWir haben ein Thema mit dem Namen Themenname erstellt mit einer einzelnen Partition und einer Replikatinstanz.
So starten Sie einen Kafka-Produzenten
Die config/server.properties Datei enthält die Broker-Port-ID. Der Broker im Beispiel lauscht auf Port 9092. Es ist möglich, den lauschenden Port direkt über die Befehlszeile anzugeben:
kafka-console-producer.sh --topic kafka-on-kubernetes --broker-list localhost:9092 --topic Topic-Name Verwenden Sie nun das Terminal, um mehrere Nachrichtenzeilen hinzuzufügen.
So starten Sie einen Kafka-Verbraucher
Wie bei den Producer-Eigenschaften werden die Standard-Consumer-Einstellungen in config/consumer.properties angegeben Datei. Öffnen Sie ein neues Terminalfenster und geben Sie den Befehl zum Konsumieren von Nachrichten ein:
kafka-console-consumer.sh --topic Topic-Name --from-beginning --zookeeper localhost:2181
Der --from-beginning Der Befehl listet Nachrichten chronologisch auf. Sie können jetzt Nachrichten vom Terminal des Erzeugers eingeben und sehen, wie sie im Terminal des Verbrauchers erscheinen.
So skalieren Sie einen Kafka-Cluster
Verwenden Sie das Befehlsterminal und verwalten Sie den Kafka-Cluster direkt mit kubectl . Geben Sie den folgenden Befehl ein und skalieren Sie Ihren Kafka-Cluster schnell, indem Sie die Anzahl der Pods von eins (1) auf sechs (6) erhöhen:
kubectl scale rc kafka-rc --replicas=6