Ich möchte meine Artikel im veralteten (veralteten) Literaturforum e-bane.net finden. Einige der Forenmodule sind deaktiviert, und ich kann keine Liste der Artikel ihres Autors abrufen. Auch wird die Seite nicht von den Suchmaschinen wie Google, Yndex etc. indiziert.
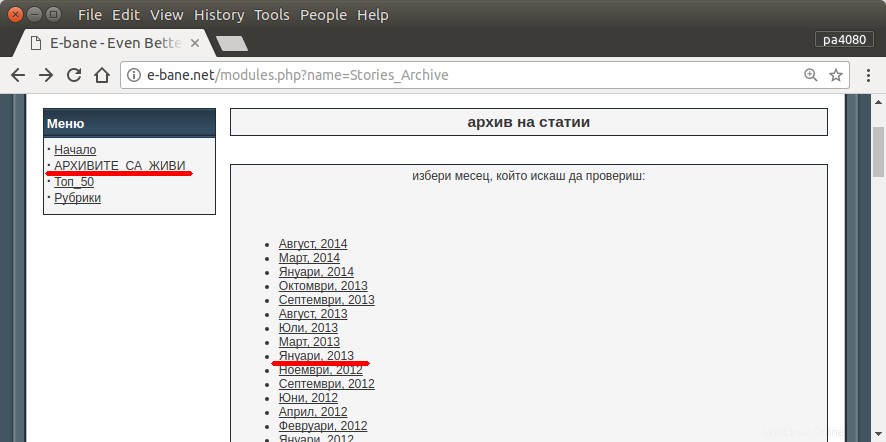
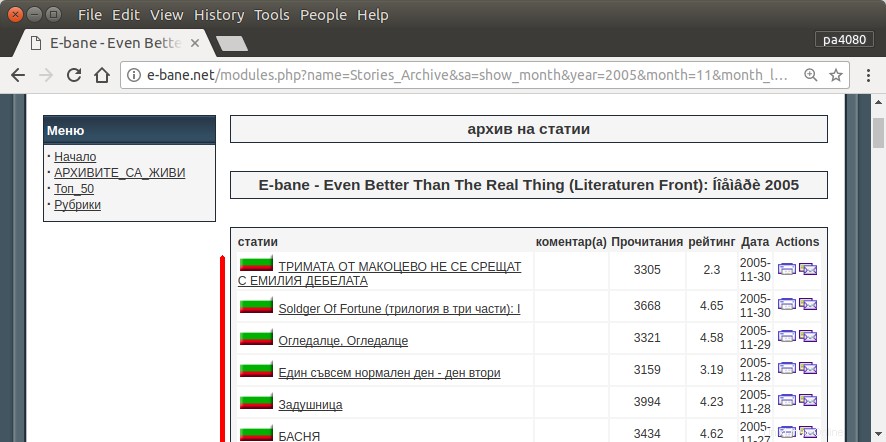
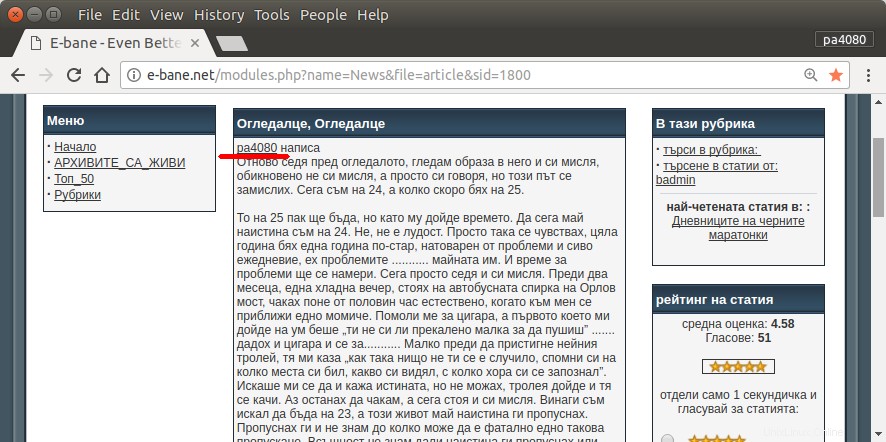
Die einzige Möglichkeit, alle meine Artikel zu finden, besteht darin, die Archivseite der Website zu öffnen (Abb. 1). Dann muss ich bestimmtes Jahr und Monat auswählen – z.B. Januar 2013 (Abb.1). Und dann muss ich bei jedem Artikel (Abb.2) kontrollieren, ob am Anfang mein Nickname steht – pa4080 (Abb. 3). Aber es gibt einige tausend Artikel.
Ich habe einige der folgenden Themen gelesen, aber keine der Lösungen entspricht meinen Anforderungen:
- Webspider für Ubuntu
- Wie man einen Webspider auf einem Linux-System schreibt
- Erhalten Sie eine Liste mit URLs von einer Website
Ich werde meine eigene Lösung posten. Aber für mich interessant:
Gibt es eine elegantere Möglichkeit, diese Aufgabe zu lösen?
Akzeptierte Antwort:
script.py :
#!/usr/bin/python3
from urllib.parse import urljoin
import json
import bs4
import click
import aiohttp
import asyncio
import async_timeout
BASE_URL = 'http://e-bane.net'
async def fetch(session, url):
try:
with async_timeout.timeout(20):
async with session.get(url) as response:
return await response.text()
except asyncio.TimeoutError as e:
print('[{}]{}'.format('timeout error', url))
with async_timeout.timeout(20):
async with session.get(url) as response:
return await response.text()
async def get_result(user):
target_url = 'http://e-bane.net/modules.php?name=Stories_Archive'
res = []
async with aiohttp.ClientSession() as session:
html = await fetch(session, target_url)
html_soup = bs4.BeautifulSoup(html, 'html.parser')
date_module_links = parse_date_module_links(html_soup)
for dm_link in date_module_links:
html = await fetch(session, dm_link)
html_soup = bs4.BeautifulSoup(html, 'html.parser')
thread_links = parse_thread_links(html_soup)
print('[{}]{}'.format(len(thread_links), dm_link))
for t_link in thread_links:
thread_html = await fetch(session, t_link)
t_html_soup = bs4.BeautifulSoup(thread_html, 'html.parser')
if is_article_match(t_html_soup, user):
print('[v]{}'.format(t_link))
# to get main article, uncomment below code
# res.append(get_main_article(t_html_soup))
# code below is used to get thread link
res.append(t_link)
else:
print('[x]{}'.format(t_link))
return res
def parse_date_module_links(page):
a_tags = page.select('ul li a')
hrefs = a_tags = [x.get('href') for x in a_tags]
return [urljoin(BASE_URL, x) for x in hrefs]
def parse_thread_links(page):
a_tags = page.select('table table tr td > a')
hrefs = a_tags = [x.get('href') for x in a_tags]
# filter href with 'file=article'
valid_hrefs = [x for x in hrefs if 'file=article' in x]
return [urljoin(BASE_URL, x) for x in valid_hrefs]
def is_article_match(page, user):
main_article = get_main_article(page)
return main_article.text.startswith(user)
def get_main_article(page):
td_tags = page.select('table table td.row1')
td_tag = td_tags[4]
return td_tag
@click.command()
@click.argument('user')
@click.option('--output-filename', default='out.json', help='Output filename.')
def main(user, output_filename):
loop = asyncio.get_event_loop()
res = loop.run_until_complete(get_result(user))
# if you want to return main article, convert html soup into text
# text_res = [x.text for x in res]
# else just put res on text_res
text_res = res
with open(output_filename, 'w') as f:
json.dump(text_res, f)
if __name__ == '__main__':
main()
requirement.txt :
aiohttp>=2.3.7
beautifulsoup4>=4.6.0
click>=6.7
Hier ist die Python3-Version des Skripts (getestet auf Python3.5 unter Ubuntu 17.10 ).
Verwendung:
- Um es zu verwenden, fügen Sie beide Codes in Dateien ein. Als Beispiel ist die Codedatei
script.pyund die Paketdatei istrequirement.txt. - Führen Sie
pip install -r requirement.txtaus . - Führen Sie das Skript als Beispiel aus
python3 script.py pa4080
Es verwendet mehrere Bibliotheken:
- Klick für Argumentparser
- schöne Suppe für HTML-Parser
- aiohttp für HTML-Downloader
Dinge, die Sie wissen sollten, um das Programm weiterzuentwickeln (außer der Dokumentation des erforderlichen Pakets):
- Python-Bibliothek:asyncio, json und urllib.parse
- CSS-Selektoren (mdn web docs), auch etwas html. Sehen Sie sich auch an, wie Sie den CSS-Selektor in Ihrem Browser verwenden, wie z. B. diesen Artikel
Wie es funktioniert:
- Zuerst erstelle ich einen einfachen HTML-Downloader. Es ist eine modifizierte Version des Beispiels auf aiohttp doc.
- Danach erstellen Sie einen einfachen Befehlszeilen-Parser, der den Benutzernamen und den Ausgabedateinamen akzeptiert.
- Erstellen Sie einen Parser für Thread-Links und Hauptartikel. Die Verwendung von pdb und einfacher URL-Manipulation sollte ausreichen.
- Kombinieren Sie die Funktion und fügen Sie den Hauptartikel in json ein, damit andere Programme ihn später verarbeiten können.
Eine Idee, damit sie weiterentwickelt werden kann
- Erstellen Sie einen weiteren Unterbefehl, der die Datumsmodulverknüpfung akzeptiert:Dies kann durch Trennen der Methode zum Parsen des Datumsmoduls in seine eigene Funktion und Kombinieren mit einem neuen Unterbefehl erfolgen.
- Caching des Date-Modul-Links:Erstellen Sie eine Cache-JSON-Datei, nachdem Sie den Thread-Link erhalten haben. Das Programm muss den Link also nicht erneut analysieren. oder einfach den gesamten Hauptartikel des Threads zwischenspeichern, auch wenn er nicht übereinstimmt
Dies ist nicht die eleganteste Antwort, aber ich denke, es ist besser als die Verwendung von Bash-Antworten.
- Es verwendet Python, was bedeutet, dass es plattformübergreifend verwendet werden kann.
- Einfache Installation, alle erforderlichen Pakete können mit pip installiert werden
- Es lässt sich weiterentwickeln, lesbarer das Programm, einfacher lässt es sich entwickeln.
- Es erledigt die gleiche Aufgabe wie das Bash-Skript nur für 13 Minuten .