Einführung
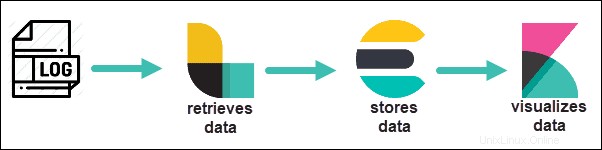
Elastischer Stapel , früher bekannt als ELK stapeln , ist eine beliebte Suite von Tools zum Erfassen, Anzeigen und Verwalten von Protokolldateien. Als Open-Source-Software können Sie sie kostenlos herunterladen und verwenden (obwohl kostenpflichtige und in der Cloud gehostete Versionen ebenfalls verfügbar sind).
Dieses Tutorial stellt die grundlegende Verwendung und Funktionalität von ELK Stack vor.

Voraussetzungen
- Ein System, auf dem Elasticsearch installiert ist
Was ist ELK Stack?
ELK steht für Elasticsearch, Logstash und Kibana. In früheren Versionen waren die Kernkomponenten des ELK-Stacks:
- Elasticsearch – Die Kernkomponente von ELK. Es funktioniert als durchsuchbare Datenbank für Protokolldateien.
- Logstash – Eine Pipeline zum Abrufen von Daten. Es kann so konfiguriert werden, dass Daten aus vielen verschiedenen Quellen abgerufen und dann an Elasticsearch gesendet werden.
- Kibana – Ein Visualisierungstool. Es verwendet eine Webbrowser-Schnittstelle, um Daten zu organisieren und anzuzeigen.
Zusätzliche Softwarepakete namens Beats sind eine neuere Ergänzung. Dies sind kleinere Datenerfassungsanwendungen, die auf einzelne Aufgaben spezialisiert sind. Es gibt viele verschiedene Beats-Anwendungen für unterschiedliche Zwecke. Beispiel:Filebeat wird verwendet, um Protokolldateien zu sammeln, während Packetbeat wird verwendet, um den Netzwerkverkehr zu analysieren.
Aufgrund des Akronyms ELK schnell nachwachsend, der Elastic Stack wurde die zufriedenstellendere und skalierbarere Option für den Namen. ELK und Elastic Stack werden jedoch synonym verwendet.
Warum ELK Stack verwenden?
Der ELK-Stack schafft eine flexible und zuverlässige Datenparsing-Umgebung. Organisationen, insbesondere solche mit Cloud-basierten Infrastrukturen, profitieren von der Implementierung des Elastic Stacks, um die folgenden Probleme zu lösen:
- Die Arbeit auf verschiedenen Servern und Anwendungen erzeugt große Mengen an Protokolldaten, die für Menschen nicht lesbar sind. Der ELK-Stapel dient als leistungsstarke zentralisierte Plattform zum Sammeln und Verwaltung unstrukturierter Informationen , um sie in nützliche Ressourcen im Entscheidungsprozess umzuwandeln.
- Der ELK-Stack mit grundlegenden Funktionen ist Open Source, was ihn kosteneffizient macht Lösung für Startups und etablierte Unternehmen gleichermaßen.
- Der Elastic Stack bietet eine robuste Plattform für die Leistungs- und Sicherheitsüberwachung und gewährleistet maximale Betriebszeit und Einhaltung von Vorschriften .
Der Elastic-Stack schließt die Branchenlücke mit Protokolldaten. Die Software kann Daten aus mehreren Quellen zuverlässig in eine skalierbare zentralisierte Datenbank parsen, was sowohl historische als auch Echtzeitanalysen ermöglicht.
Wie funktioniert Elastic Stack?
Der Elastic Stack folgt bestimmten logischen Schritten, die alle konfigurierbar sind.
1. Ein Computer oder Server erstellt Protokolldateien. Alle Computer haben Protokolldateien, die Ereignisse auf dem System in einem schwer lesbaren Format dokumentieren. Einige Systeme, wie z. B. Server-Cluster, generieren riesige Mengen an Protokolldateien.
Elastic Stack ist jedoch darauf ausgelegt, skalierbare Datenmengen zu verwalten.
2. Die verschiedenen verfügbaren Informationsdateien werden von einem Beats gesammelt Anwendung. Verschiedene Beats erreichen Sie verschiedene Teile des Servers, lesen Sie die Dateien und versenden Sie sie.
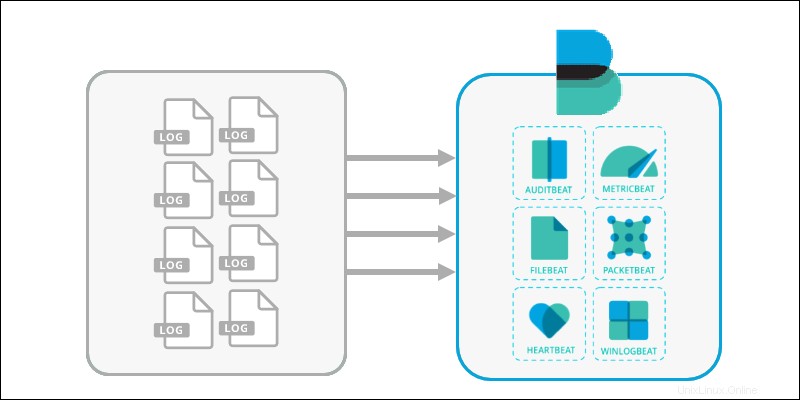
Einige Benutzer können Beats ganz überspringen und Logstash direkt verwenden. Andere können Beats direkt mit Elasticsearch verbinden.
3. Logstash ist so konfiguriert, dass es Daten von den verschiedenen Beats erreicht und sammelt Anwendungen (oder direkt aus verschiedenen Quellen).
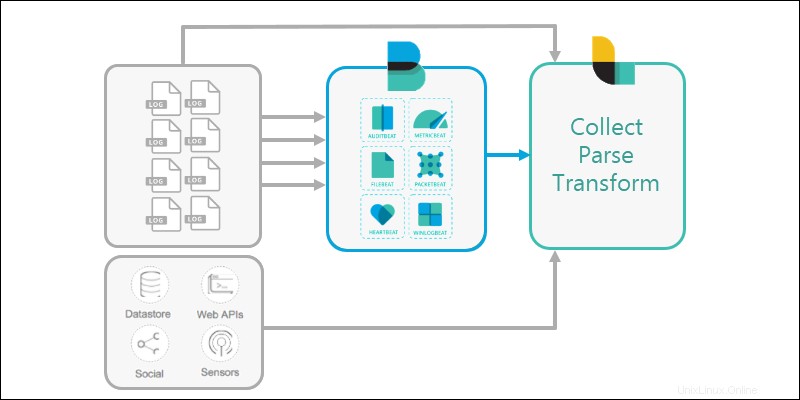
In größeren Konfigurationen Logstash kann Daten aus mehreren Systemen filtern und die Informationen an einem Ort sammeln.
4. Elasticsearch wird als skalierbare, durchsuchbare Datenbank zum Speichern von Daten verwendet. Elasticsearch ist das Lager, in dem Logstash oder Beats Pipe alle Daten.
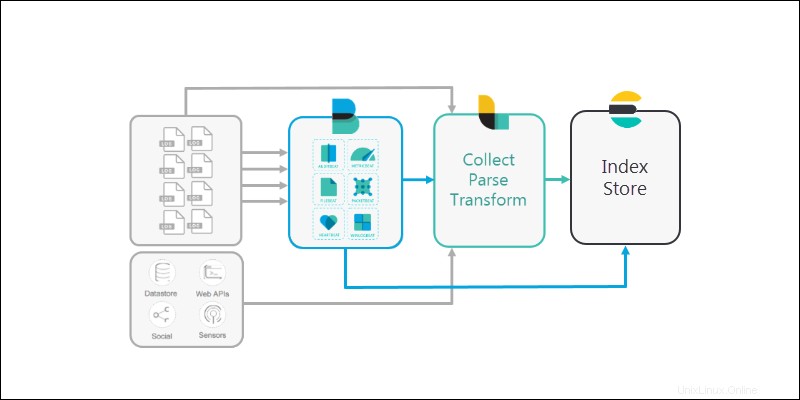
5. Schließlich Kibana bietet eine benutzerfreundliche Oberfläche, mit der Sie die gesammelten Daten überprüfen können.
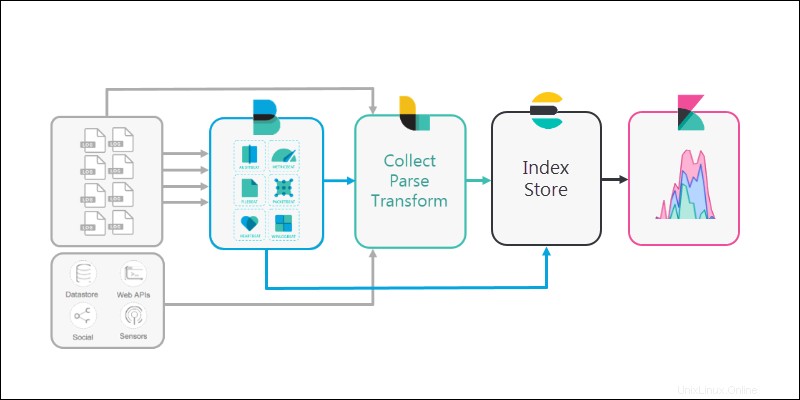
Es ist hochgradig konfigurierbar, sodass Sie die Metriken an Ihre Bedürfnisse anpassen können. Kibana bietet auch Diagramme und andere Tools zum Visualisieren und Interpretieren von Mustern in den Daten.
ELK-Stack-unterstützende Anwendungen
Zusätzliche Anwendungen von Drittanbietern erweitern den Elastic Stack und bieten breitere Anwendungsmöglichkeiten. Einige externe Anwendungen, die vom ELK-Stack unterstützt werden, sind:
- Apache Kafka
Kafka ist eine Echtzeit-Streaming-Verteilungsplattform. Das bedeutet, dass es mehrere Datenquellen gleichzeitig lesen kann. Kafka fungiert als Datenpuffer und hilft, Datenverluste oder -unterbrechungen beim schnellen Streamen von Dateien zu verhindern.
- Redis
Redis ist eine NoSQL-Schlüsselwertdatenbank mit unglaublichen Lese-/Schreibgeschwindigkeiten und verschiedenen Datentypen. Wenn Redis dem Elastic-Stack hinzugefügt wird, dient es oft als Puffer für Datenstromspitzen, um sicherzustellen, dass keine Daten verloren gehen.
- Hadoop
Hadoop ist ein Datenspeichersystem mit massiver Stapelverarbeitung. Die Indizierung von Daten aus Hadoop in die Echtzeit-Elasticsearch-Engine schafft eine interaktive, bidirektionale Datenermittlungs- und Visualisierungsplattform.
Die Hadoop-Unterstützung erfolgt über den Elasticsearch-Hadoop Connector, der volle Unterstützung für Spark, Streaming, Hive, Storm, MapReduce und andere Tools bietet.
- RabbitMQ
RabbitMQ ist eine Messaging-Plattform. Benutzer von Elastic Stack verwenden diese Software, um eine stabile, gepufferte Warteschlange von Protokolldateien aufzubauen.
- Nginx
Nginx ist vor allem als Webserver bekannt, der auch als Reverse-Proxy eingerichtet werden kann. Es kann verwendet werden, um den Netzwerkverkehr zu verwalten oder einen Sicherheitspuffer zwischen Ihrem Server und dem Internet zu erstellen.
ELK-Stack-Vorteile und -Nachteile
Der Elastic-Stack hat bestimmte Vor- und Nachteile.
Vorteile
- Der Elastic-Stack und die Komponenten können kostenlos ausprobiert und verwendet werden.
- ELK bietet zahlreiche Hosting-Optionen, ob vor Ort oder als Managed Service bereitgestellt.
- Die Möglichkeit, die Protokollierung aus komplexen Cloud-Umgebungen zu zentralisieren, ermöglicht erweiterte Suchen und das Erstellen von Korrelationen aus mehreren Quellen auf einer einzigen Plattform.
- Echtzeitanalyse und -visualisierung verkürzen die Zeit, die zum Gewinnen von Erkenntnissen benötigt wird, und ermöglichen eine kontinuierliche Überwachung.
- Client-Unterstützung für mehrere Programmiersprachen, einschließlich JavaScript, Python, Perl, Go usw.
Nachteile
- Die Bereitstellung des Stacks ist ein komplexer Prozess und hängt von den Anforderungen ab. Sehen Sie sich unser Tutorial zum Bereitstellen des Elastic-Stacks auf Kubernetes an.
- Das Erweitern und Warten des ELK-Stacks ist kostspielig und erfordert Rechenleistung und Datenspeicherung basierend auf dem Datenvolumen und der Speicherzeit.
- Stabilität und Betriebszeit werden problematisch, wenn die Datenmengen aufgrund nicht vorhandener Indizierungsbeschränkungen wachsen.
- Die Datenaufbewahrung und -archivierung erfordert im Allgemeinen mehrere Knoten, Rechenleistung und Ressourcen.
Elasticsearch-Übersicht
Elasticsearch ist der Kern des Elastic Stacks. Es hat zwei Hauptaufgaben:
- Speicherung und Indexierung von Daten.
- Suchmaschine zum Abrufen von Daten.
Zu den technischen Elasticsearch-Details gehören:
- Robuste Programmiersprachenunterstützung für Clients (Java, PHP, Ruby, C#, Python).
- Verwendet eine REST-API – Anwendungen, die für Elasticsearch geschrieben wurden, sind hervorragend mit Webanwendungen kompatibel.
- Reaktionsfähige Ergebnisse – Benutzer sehen Daten fast in Echtzeit.
- Verteilte Architektur – Elasticsearch kann viele verschiedene Server ausführen und eine Verbindung herstellen. Der Elastic Stack kann einfach skaliert werden, wenn die Infrastruktur wächst.
- Umgekehrte Indexierung – Elasticsearch indiziert nach Schlüsselwörtern, ähnlich wie der Index in einem Buch. Dies trägt dazu bei, Abfragen für große Datensätze zu beschleunigen.
- Shards – Wenn Ihre Daten zu groß für Ihren Server sind, kann Elasticsearch sie in Teilmengen namens Shards aufteilen .
- Nicht relational (NoSQL) – Elasticsearch verwendet eine nicht relationale Datenbank, um sich von den Beschränkungen der strukturierten/tabellarischen Datenspeicherung zu befreien.
- Apache Lucene – Dies ist die Basissuchmaschine, auf der Elasticsearch basiert.
Logstash-Übersicht
Logstash ist ein Tool zum Sammeln und Sortieren von Daten aus verschiedenen Quellen. Logstash kann einen Remote-Server erreichen, einen bestimmten Satz von Protokollen sammeln und sie in Elasticsearch importieren.
Es kann Daten sortieren, filtern und organisieren. Darüber hinaus enthält es mehrere Standardkonfigurationen, oder Sie können Ihre eigenen erstellen. Dies ist besonders hilfreich, um Daten einheitlich (oder lesbar) zu strukturieren.
Technische Eigenschaften von Logstash:
- Akzeptiert eine Vielzahl von Datenformaten und -quellen – Dies hilft, verschiedene Datensätze an einem zentralen Ort zu konsolidieren.
- Manipuliert Daten in Echtzeit – Wenn Daten aus Quellen gelesen werden, analysiert Logstash sie und restrukturiert sie sofort.
- Flexible Ausgabe – Logstash wurde für Elasticsearch entwickelt, aber wie viele Open-Source-Projekte kann es für den Export in andere Dienstprogramme neu konfiguriert werden.
- Plug-in-Unterstützung – Eine breite Palette von Add-ons kann hinzugefügt werden, um die Funktionen von Logstash zu verbessern.
Kibana-Übersicht
Sie können Elasticsearch von einer Befehlszeile aus verwenden, indem Sie es einfach installieren. Aber Kibana bietet Ihnen eine grafische Oberfläche, um Daten intuitiver zu generieren und anzuzeigen.
Hier sind einige der technischen Details:
- Dashboard-Oberfläche – Konfigurieren Sie Diagramme, Datenquellen und Metriken auf einen Blick.
- Konfigurierbare Menüs – Erstellen Sie Datenvisualisierungen und Menüs zum schnellen Navigieren oder Durchsuchen von Datensätzen.
- Plug-ins – Durch das Hinzufügen von Plug-ins wie Canvas können Sie Ihrer grafischen Benutzeroberfläche strukturierte Ansichten und Echtzeitüberwachung hinzufügen.
Erfahren Sie in unserem Leitfaden Complete Kibana Tutorial to Visualize and Query Data, wie Sie Kibana verwenden.
Beats-Übersicht
Beats läuft auf dem überwachten System. Es sammelt und versendet Daten an ein Ziel wie Logstash oder Elasticsearch.
Sie können Beats verwenden, um Daten direkt in Elasticsearch zu importieren, wenn Sie einen kleineren Datensatz verwenden.

Alternativ können Beats verwendet werden, um Daten in verwaltbare Streams aufzuteilen, die dann in Logstash geparst werden, um von Elasticsearch gelesen zu werden.

Für einen einzelnen Server können Sie Elasticsearch, Kibana und ein paar Beats installieren. Jeder Beats sammelt Daten und sendet sie an Elasticsearch. Anschließend sehen Sie sich die Ergebnisse in Kibana an.
Alternativ können Sie Beats auf mehreren Remote-Servern installieren und dann Logstash konfigurieren, um die Daten von den Servern zu sammeln und zu parsen. Diese Daten werden an Elasticsearch gesendet und dann in Kibana sichtbar.
| Beat | Datenerfassung | Beschreibung |
|---|---|---|
| Auditbeat | Prüfdaten | Eine aufgeladene Version von Linux auditd. Es kann anstelle von auditd direkt mit Ihrem Linux-System interagieren Prozess. Wenn Sie bereits auditd-Regeln eingerichtet haben, liest Auditbeat aus Ihrer vorhandenen Konfiguration. |
| Filebeat | Protokolldateien | Liest und versendet Systemprotokolldateien. Es ist nützlich für Serverprotokolle wie Hardwareereignisse oder Anwendungsprotokolle. |
| Funktionsschlag | Cloud-Daten | Versendet Daten aus einer serverlosen oder Cloud-Infrastruktur. Wenn Sie einen in der Cloud gehosteten Dienst ausführen, verwenden Sie ihn, um Daten aus der Cloud zu sammeln und nach Elasticsearch zu exportieren. |
| Herzschlag | Verfügbarkeit | Zeigt Betriebszeit und Reaktionszeit an. Verwenden Sie dies, um kritische Server oder andere Systeme im Auge zu behalten und sicherzustellen, dass sie laufen und verfügbar sind. |
| Journalbeat | Systemd-Journale | Weiterleitung, Zentralisierung und Versand von systemd-Journalprotokollen. |
| Metricbeat | Metriken | Liest metrische Daten – CPU-Nutzung, Speicher, Festplattennutzung, Netzwerkbandbreite. Verwenden Sie dies als aufgeladenen Systemressourcenmonitor. |
| Packetbeat | Netzwerkverkehr | Analysiert den Netzwerkverkehr. Verwenden Sie es, um Latenz und Reaktionsfähigkeit oder Nutzungs- und Verkehrsmuster zu überwachen. |
| Winlogbeat | Windows-Ereignisprotokolle | Sendet Daten aus dem Windows-Ereignisprotokoll. Verfolgen Sie Anmeldeereignisse, Installationsereignisse und sogar Hardware- oder Anwendungsfehler. |
ELK-Stack-Anwendungsfälle
Die Protokollüberwachung in Echtzeit aus verschiedenen Ressourcen bietet dem Elastic Stack viele kreative Anwendungsfälle.
- Sicherheitsüberwachung und -warnung . Ein Serverüberwachungs- und Warnsystem ist eine wichtige Sicherheitsanwendung für den ELK-Stack. Die Überprüfung auf ungewöhnliche Anfragen oder die Erkennung von Serverangriffen mit einem Echtzeit-Warnsystem kann dazu beitragen, Schäden zu mindern, sobald sie auftreten.
- E-Commerce-Lösungen . Volltextsuche, Indexierung, Aggregationen und schnelle Antworten schaffen eine bessere Benutzererfahrung. Die visuelle Überwachung von Suchtrends und -verhalten trägt zur Verbesserung der Trendanalyse bei.
- Web Scraping . Die Möglichkeit, unstrukturierte Daten aus verschiedenen Quellen zu sammeln, zu indizieren und zu durchsuchen, macht es einfach, Web-Scraping-Informationen zu sammeln und zu visualisieren.
- Verkehrsüberwachung . Die Überwachung von Website-Verkehrsdaten hilft dabei, anzuzeigen, dass ein Server überlastet ist. Implementieren Sie eine Load-Balancing-Anwendung (wie Nginx), um den Datenverkehr auf andere Server zu verlagern.
- Fehlererkennung . Wenn Sie eine neue Anwendung bereitstellen, können Sie Fehler für diese Anwendung überwachen. Diese können helfen, Bereiche schnell zu identifizieren, um Fehler zu beheben oder das Anwendungsdesign zu verbessern.
Elastic Stack generiert Daten, die Sie verwenden können, um Probleme zu lösen und fundierte Geschäftsentscheidungen zu treffen.