Einführung
Kubernetes bietet ein außergewöhnliches Maß an Flexibilität für die Orchestrierung eines großen Clusters verteilter Container.
Die schiere Anzahl der verfügbaren Funktionen und Optionen kann eine Herausforderung darstellen. Die Anwendung von Best Practices hilft Ihnen, potenzielle Hürden zu vermeiden und von Anfang an eine sichere und effiziente Umgebung zu schaffen.
Verwenden Sie die beschriebenen Best Practices für Kubernetes um optimierte Container zu erstellen, Bereitstellungen zu rationalisieren, zuverlässige Dienste zu verwalten und einen vollständigen Cluster zu verwalten.

Container sichern und optimieren
Container bieten viel weniger Isolation als virtuelle Maschinen. Sie sollten Container-Images immer überprüfen und die Benutzerberechtigungen streng kontrollieren.
Die Verwendung kleiner Container-Images steigert die Effizienz, schont Ressourcen und reduziert die Angriffsfläche für potenzielle Angreifer.
Nur vertrauenswürdige Container-Images verwenden
Vorgefertigte Container-Images sind leicht zugänglich und äußerst nützlich. Öffentliche Images können jedoch schnell veraltet sein, Exploits, Fehler oder sogar bösartige Software enthalten, die sich schnell in einem Kubernetes-Cluster verbreitet.
Verwenden Sie nur Bilder aus vertrauenswürdigen Repositorys und scannen Sie Bilder immer auf potenzielle Schwachstellen. Zahlreiche Online-Tools wie Anchore oder Clair bieten eine schnelle statische Analyse von Container-Images und informieren Sie über potenzielle Bedrohungen und Probleme. Nehmen Sie sich einen Moment Zeit, um Container-Images zu scannen, bevor Sie sie bereitstellen, und vermeiden Sie potenziell katastrophale Folgen.
Nicht-Root-Benutzer und schreibgeschützte Dateisysteme
Ändern Sie den integrierten Sicherheitskontext, um zu erzwingen, dass alle Container nur mit Nicht-Root-Benutzern und mit einem schreibgeschützten Dateisystem ausgeführt werden.
Vermeiden Sie es, Container als Root-Benutzer auszuführen. Eine Sicherheitsverletzung kann schnell eskalieren, wenn sich ein Benutzer zusätzliche Berechtigungen erteilen kann.

Wenn ein Dateisystem schreibgeschützt ist, besteht nur eine geringe Chance, den Inhalt des Containers zu manipulieren. Anstatt Systemdateien zu bearbeiten, müsste der gesamte Container entfernt und ein neuer an seine Stelle gesetzt werden.
Erstellen Sie kleine und mehrschichtige Bilder
Kleine Bilder beschleunigen Ihre Builds und benötigen weniger Speicherplatz. Durch effizientes Schichten eines Bildes kann die Bildgröße erheblich reduziert werden. Versuchen Sie, Ihre Bilder von Grund auf neu zu erstellen, um optimale Ergebnisse zu erzielen.
Verwenden Sie mehrere FROM-Anweisungen in einer einzigen Dockerfile, wenn Sie viele verschiedene Komponenten benötigen. Diese Funktion erstellt Abschnitte, die jeweils auf ein anderes Basisbild verweisen. Das endgültige Image speichert nicht mehr die vorherigen Schichten, sondern nur die Komponenten, die Sie von jeder benötigen, wodurch der Docker-Container viel schlanker wird.
Jede Ebene wird basierend auf FROM gezogen Befehl, der sich im bereitgestellten Container befindet.
Benutzerzugriff mit RBAC einschränken
Die rollenbasierte Zugriffskontrolle (RBAC) stellt sicher, dass kein Benutzer mehr Berechtigungen hat, als er zum Erledigen seiner Aufgaben benötigt. Sie können RBAC aktivieren, indem Sie beim Starten des API-Servers das folgende Flag anhängen:
--authorization-mode=RBACRBAC verwendet rbac.authorization.k8s.io API-Gruppe, um Autorisierungsentscheidungen über die Kubernetes-API zu steuern.
Stdout- und Stderr-Protokolle
Es ist üblich, Anwendungsprotokolle an stdout zu senden (Standardausgabe)-Stream und Fehlerprotokolle in stderr (Standardfehler) Stream. Sobald eine App in stdout und stderr schreibt, leitet eine Container-Engine wie Docker Datensätze um und speichert sie in einer JSON-Datei.
Kubernetes-Container, -Pods und -Knoten sind dynamische Einheiten. Protokolle müssen konsistent und ständig verfügbar sein. Es wird daher empfohlen, Ihre clusterweiten Protokolle in einem separaten Backend-Speichersystem aufzubewahren.
Kubernetes kann in eine Vielzahl vorhandener Protokollierungslösungen integriert werden, z. B. den ELK-Stack.
Bereitstellungen optimieren
Eine Kubernetes-Bereitstellung richtet eine Vorlage ein, die sicherstellt, dass Pods betriebsbereit sind, regelmäßig aktualisiert oder zurückgesetzt werden, wie vom Benutzer definiert.
Die Verwendung eindeutiger Labels, Flags, verknüpfter Container und DaemonSets kann Ihnen eine feinkörnige Kontrolle über den Bereitstellungsprozess geben.
Verwenden des Datensatz-Flags
Wenn Sie --record anhängen Flag, das ausgeführte kubectl Befehl wird als Anmerkung gespeichert. Indem Sie den Rollout-Verlauf der Bereitstellung überprüfen, können Sie Aktualisierungen in CHANGE-CAUSE leicht nachverfolgen Spalte.
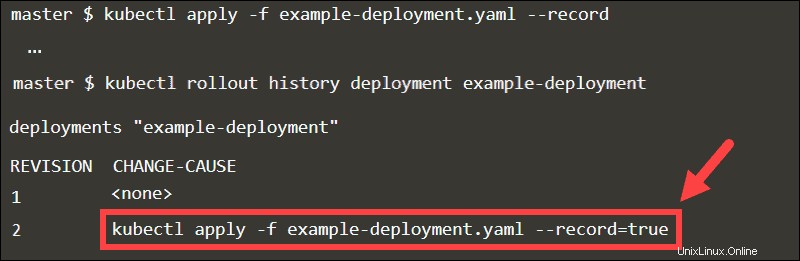
Rollback zu einer beliebigen Revision durch Angabe der Revisionsnummer im Undo-Befehl.
kubectl rollout undo deployment example-deployment --to-revision=1
Ohne --record Flag, wäre es schwierig, die spezifische Revision zu identifizieren.
Beschreibende Labels
Versuchen Sie, so viele aussagekräftige Labels wie möglich zu verwenden. Labels sind Schlüssel/Wert-Paare, die es Benutzern ermöglichen, Pods in aussagekräftigen Teilmengen zu gruppieren und zu organisieren. Die meisten Funktionen, Plugins und Lösungen von Drittanbietern benötigen Labels, um Pods identifizieren und automatisierte Prozesse steuern zu können.
Beispielsweise sind Kubernetes-DaemonSets von Bezeichnungen und Knotenselektoren abhängig, um die Pod-Bereitstellung innerhalb eines Clusters zu verwalten.
Mehrere Prozesse innerhalb eines Pods erstellen
Nutzen Sie die Container-Linking-Fähigkeiten von Kubernetes, anstatt zu versuchen, jedes Problem innerhalb eines Containers zu lösen. Es stellt effektiv mehrere Container auf einem einzigen Kubernetes-Pod bereit. Ein gutes Beispiel ist das Auslagern von Sicherheitsfunktionen an einen Proxy-Sidecar Behälter.
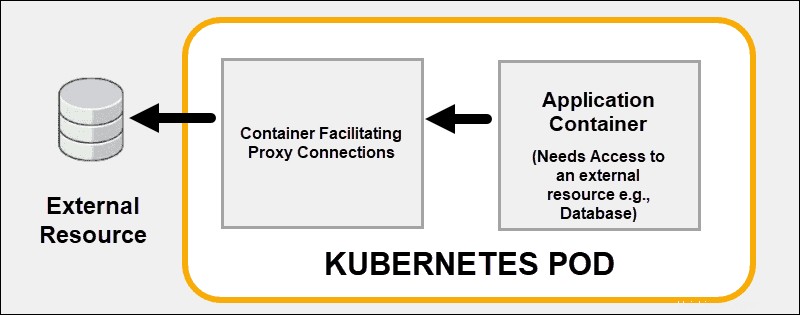
Ein gekoppelter Container kann die Kernfunktionalität des Hauptcontainers unterstützen oder verbessern oder dem Hauptcontainer helfen, sich an seine Bereitstellungsumgebung anzupassen.
Init-Container verwenden
Ein oder mehrere Init-Container führen normalerweise Hilfsaufgaben oder Sicherheitsprüfungen durch, die Sie nicht in den Hauptanwendungscontainer aufnehmen möchten. Sie können Init-Container verwenden, um sicherzustellen, dass ein Dienst bereit ist, bevor Sie den Hauptcontainer des Pods initialisieren.
Jeder Init-Container muss erfolgreich vollständig ausgeführt werden, bevor der nachfolgende Init-Container startet. Init-Container können den Start des Hauptcontainers des Pods verzögern, bis eine Vorbedingung erfüllt ist. Ohne diese Vorbedingung startet Kubernetes den Pod neu. Sobald die Voraussetzung erfüllt ist, beendet sich der Init-Container selbst und lässt den Hauptcontainer starten.
Vermeiden Sie die Verwendung des neuesten Tags
Verwenden Sie kein Tag oder :latest -Tag beim Bereitstellen von Containern in einer Produktionsumgebung. Das neuste Tag erschwert die Feststellung, welche Version des Images ausgeführt wird.
Eine effektive Methode, um sicherzustellen, dass der Container immer dieselbe Version des Images verwendet, besteht darin, den eindeutigen Image-Digest als Tag zu verwenden. In diesem Beispiel wird eine Redis-Image-Version mit ihrem eindeutigen Digest bereitgestellt:
[email protected]:675hgjfn48324cf93ffg43269ee113168c194352dde3eds876677c5cbKubernetes aktualisiert die Image-Version nicht automatisch, es sei denn, Sie ändern den Digest-Wert.
Bereitschafts- und Aktivitätstests einrichten
Lebendigkeit und Bereitschaftstests Helfen Sie Kubernetes dabei, den Zustand Ihrer Anwendungen zu überwachen und zu interpretieren. Wenn Sie eine Lebendigkeitsprüfung definieren und ein Prozess die Anforderungen erfüllt, stoppt Kubernetes den Container und startet eine neue Instanz, die seinen Platz einnimmt.
Bereitschaftstests führen Audits auf Pod-Ebene durch und bewerten, ob ein Pod Datenverkehr akzeptieren kann. Wenn ein Pod nicht reagiert, löst eine Bereitschaftsprüfung einen Prozess aus, um den Pod neu zu starten.
Die Dokumentation zum Konfigurieren von Bereitschafts- und Aktivitätstests ist auf der offiziellen Kubernetes-Website verfügbar.
Verschiedene Dienstarten ausprobieren
Indem Sie lernen, wie Sie verschiedene Diensttypen nutzen, können Sie den internen und externen Pod-Datenverkehr effektiv verwalten. Ihr Ziel ist es, eine stabile Netzwerkumgebung zu schaffen, indem Sie zuverlässige Endpunkte wie IPs, Ports und DNS verwalten.
Statische Ports mit NodePort
Stellen Sie Pods für externe Benutzer bereit, indem Sie den Diensttyp auf NodePort setzen. Wenn Sie einen Wert in nodePort angeben Feld reserviert Kubernetes diese Portnummer über alle Knoten hinweg und leitet den gesamten eingehenden Datenverkehr weiter, der für die Pods bestimmt ist, die Teil des Dienstes sind. Auf den Dienst kann sowohl über die interne Cluster-IP als auch über die IP des Knotens mit dem reservierten Port zugegriffen werden.

Benutzer können den NodePort-Dienst von außerhalb des Clusters kontaktieren, indem sie Folgendes anfordern:
NodeIP:NodePortVerwenden Sie immer eine Portnummer innerhalb des für NodePort konfigurierten Bereichs (30000-32767). Wenn eine API-Transaktion fehlschlägt, müssen Sie mögliche Portkollisionen beheben.
Ingress vs. LoadBalancer
Der LoadBalancer-Typ macht Dienste extern verfügbar, indem er den Load Balancer Ihres Anbieters verwendet. Jeder Dienst, den Sie mit dem LoadBalancer-Typ verfügbar machen, erhält seine IP. Wenn Sie über viele Dienste verfügen, können je nach Anzahl der verfügbaren Dienste ungeplante zusätzliche Kosten anfallen.
Eine Standardkonfigurationsanforderung besteht darin, einen Ingress-Controller mit einer vorhandenen statischen öffentlichen IP-Adresse bereitzustellen. Die statische öffentliche IP-Adresse bleibt bestehen, wenn der Eingangscontroller gelöscht wird. Dieser Ansatz ermöglicht Ihnen die konsistente Verwendung aktueller DNS-Einträge und Netzwerkkonfigurationen während des gesamten Lebenszyklus Ihrer Anwendungen.
Zuordnung externer Dienste zu einem DNS
Der ExternalName-Typ ordnet einem Selektor keine Dienste zu, sondern verwendet stattdessen einen DNS-Namen. Verwenden Sie den externenNamen -Parameter zum Zuordnen von Diensten mithilfe eines CNAME-Eintrags. Ein CNAME-Eintrag ist ein vollständig qualifizierter Domänenname und keine numerische IP.
Clients, die eine Verbindung zum Dienst herstellen, umgehen den Dienstproxy und stellen direkt eine Verbindung zur externen Ressource her. In diesem Beispiel der pnap-service wird admin.phoenixnap.com zugeordnet externe Ressource.

Zugriff auf den pnap-Dienst funktioniert genauso wie bei anderen Diensten. Der entscheidende Unterschied besteht darin, dass die Umleitung jetzt auf DNS-Ebene erfolgt.
Anwendungsdesign
Die automatisierte Bereitstellung von Containern mit Kubernetes stellt sicher, dass die meisten Vorgänge jetzt ohne direkte menschliche Eingabe ausgeführt werden. Gestalten Sie Ihre Anwendungen und Container-Images so, dass sie austauschbar sind und keine ständige Mikroverwaltung erfordern.
Fokus auf individuelle Dienstleistungen
Versuchen Sie, Ihre Anwendung in mehrere Dienste aufzuteilen, und vermeiden Sie es, zu viele Funktionen in einem einzigen Container zu bündeln. Es ist viel einfacher, Apps horizontal zu skalieren und Container wiederzuverwenden, wenn sie sich auf eine Funktion konzentrieren.
Gehen Sie beim Erstellen Ihrer Anwendungen davon aus, dass Ihre Container kurzfristige Einheiten sind, die regelmäßig angehalten und neu gestartet werden.
Helm-Charts verwenden
Helm, der Kubernetes-Anwendungspaketmanager, kann den Installationsprozess rationalisieren und Ressourcen sehr schnell im gesamten Cluster bereitstellen. Die Helm-Anwendungspakete heißen Charts.
Anwendungen wie MySQL, PostgreSQL, MongoDB, Redis, WordPress sind gefragte Lösungen. Anstatt mehrere komplexe Konfigurationsdateien zu erstellen und zu bearbeiten, können Sie sofort verfügbare Helm Charts bereitstellen.
Verwenden Sie den folgenden Befehl, um die erforderlichen Bereitstellungen, Dienste, PersistentVolumeClaims und Secrets zu erstellen, die zum Ausführen von Kafka Manager auf Ihrem Cluster erforderlich sind.
helm install --name my-messenger stable/kafka-managerSie müssen nicht mehr bestimmte Komponenten analysieren und lernen, wie man sie konfiguriert, um Kafka ordnungsgemäß auszuführen.
Knoten- und Pod-Affinität nutzen
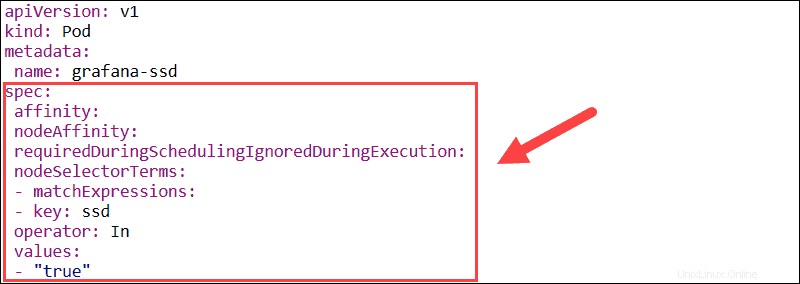
Das Affinitätsmerkmal wird verwendet, um sowohl die Knotenaffinität als auch die Inter-Pod-Affinität zu definieren. Mit der Knotenaffinität können Sie die Knoten angeben, auf denen ein Pod geplant werden kann, indem Sie vorhandene Knotenbezeichnungen verwenden.
- requiredDuringSchedulingIgnoredDuringExecution – Legt obligatorische Einschränkungen fest, die erfüllt sein müssen, damit ein Pod für einen Knoten geplant werden kann.
- preferredDuringSchedulingIgnoredDuringExecution – Definiert Präferenzen, die ein Planer priorisiert, aber nicht garantiert.
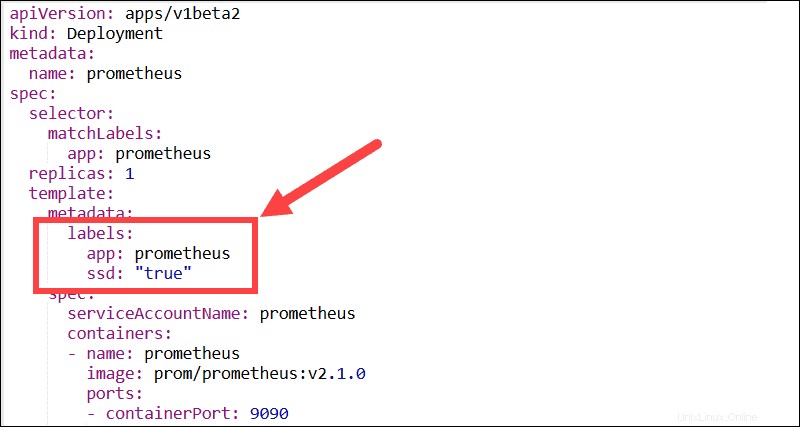
Wenn sich die Node-Labels zur Laufzeit ändern und die Affinitätsregeln des Pods nicht mehr erfüllt sind, wird der Pod nicht vom Node entfernt. Der nodeSelector Der Parameter begrenzt Pods mithilfe von Labels auf bestimmte Knoten. In diesem Beispiel wird der Grafana-Pod nur auf Knoten geplant, die über die ssd verfügen Bezeichnung.
Die Pod-Affinitäts-/Anti-Affinitätsfunktion erweitert die Arten von Beschränkungen, die Sie ausdrücken können. Anstatt Knotenlabels zu verwenden, können Sie vorhandene Podlabels verwenden, um die Knoten abzugrenzen, auf denen ein Pod geplant werden kann. Mit dieser Funktion können Sie Regeln festlegen, sodass einzelne Pods basierend auf Labels anderer Pods geplant werden.
Knotenfehler und Toleranzen
Kubernetes versucht automatisch, Pods an Standorten mit der geringsten Arbeitslast bereitzustellen. Mit Knoten- und Pod-Affinität können Sie steuern, auf welchem Knoten ein Pod bereitgestellt wird. Taints können die Bereitstellung von Pods auf bestimmten Knoten verhindern, ohne vorhandene Pods zu ändern. Pods, die Sie auf einem fehlerhaften Knoten bereitstellen möchten, müssen sich für die Verwendung des Knotens anmelden.
- Flecken – Verhindern Sie, dass neue Pods auf Knoten geplant werden, definieren Sie Knotenpräferenzen und entfernen Sie vorhandene Pods von einem Knoten.
- Toleranzen – Aktivieren Sie, dass Pods nur auf Knoten mit vorhandenen und passenden Taints geplant werden.
Markierungen und Toleranzen erzielen optimale Ergebnisse, wenn sie zusammen verwendet werden, um sicherzustellen, dass Pods auf den richtigen Knoten geplant werden.
Ressourcen mit Namespaces gruppieren
Verwenden Sie Kubernetes-Namespaces, um große Cluster in kleinere, leicht identifizierbare Gruppen zu unterteilen. Namespaces ermöglichen es Ihnen, separate Test-, QA-, Produktions- oder Entwicklungsumgebungen zu erstellen und angemessene Ressourcen innerhalb eines eindeutigen Namespace zuzuweisen. Die Namen von Kubernetes-Ressourcen müssen nur innerhalb eines einzigen Namespace eindeutig sein. Verschiedene Namespaces können Ressourcen mit demselben Namen haben.
Wenn mehrere Benutzer Zugriff auf denselben Cluster haben, können Sie Benutzer einschränken und ihnen erlauben, innerhalb der Grenzen eines bestimmten Namespaces zu agieren. Das Trennen von Benutzern ist eine großartige Möglichkeit, Ressourcen abzugrenzen und potenzielle Namens- oder Versionskonflikte zu vermeiden.
Namespaces sind Kubernetes-Ressourcen und außergewöhnlich einfach zu erstellen. Erstellen Sie eine YAML-Datei, die den Namespace-Namen definiert, und verwenden Sie kubectl, um sie an den Kubernetes-API-Server zu senden. Anschließend können Sie den Namensraum verwenden, um die Bereitstellung zusätzlicher Ressourcen zu verwalten.