Für einen Systemadministrator ist es sehr üblich, eine Eingabe- oder Ausgabeumleitung durchzuführen bei seiner täglichen Arbeit.
Die Eingabe- und Ausgabeumleitung ist ein sehr leistungsfähiges Werkzeug, mit dem Sie mehrere Befehle miteinander verbinden und die Ausgabe mehrerer Befehle synthetisieren können.
Eingabe-/Ausgabeumleitung ist ein Kernkonzept von Unix-basierten Systemen – und es kann verwendet werden, um die Programmiererproduktivität zu steigern enorm.
Die Ein- und Ausgabeumleitung ist jedoch ein großes Thema, und es gibt ein paar Grundlagen, die Sie verstehen müssen, wenn Sie produktiv sein wollen.
Mit diesem Tutorial werden Sie alles verstehen dass es etwas über die Ein- und Ausgabeumleitung auf Linux-Systemen zu wissen gibt.
Wir werden über das Design des Linux-Kernels nachdenken auf Dateien sowie die Art und Weise, wie Prozesse funktionieren, um ein tiefes und vollständiges Verständnis davon zu bekommen, was Eingabe- und Ausgabeumleitung ist.
Einige Beispiele werden nebenbei bereitgestellt, um sicherzustellen, dass theoretisches Wissen mit praktischen Übungen verknüpft wird.
Bereit?
Was Sie lernen werden
Wenn Sie diesem Tutorial bis zum Ende folgen, werden Sie die folgenden Konzepte kennenlernen.
- Welche Dateideskriptoren sind und wie sie sich auf Standardeingaben und -ausgaben beziehen;
- Überprüfender Standardeingaben und -ausgaben für einen bestimmten Prozess unter Linux;
- Wie man Standardeingabe und -ausgabe umleitet unter Linux;
- So verwenden Sie Pipelines um Ein- und Ausgänge für lange Befehle zu verketten;
Das ist ein ziemlich langes Programm, schauen wir uns ohne weiteres an, was Dateideskriptoren sind und wie Dateien vom Linux-Kernel konzipiert werden.
1 – Was sind Linux-Prozesse?
Bevor Sie die Eingabe und Ausgabe auf einem Linux-System verstehen, ist es sehr wichtig, einige Grundlagen darüber zu haben, was Linux-Prozesse sind und wie sie mit Ihrer Hardware interagieren.
Wenn Sie nur an Befehlszeilen zur Eingabe- und Ausgabeumleitung interessiert sind, können Sie zu den nächsten Abschnitten springen. Dieser Abschnitt richtet sich an Systemadministratoren, die tiefer in das Thema einsteigen möchten.
a – Wie werden Linux-Prozesse erstellt?
Sie haben es wahrscheinlich schon einmal gehört, da es ein ziemlich beliebtes Sprichwort ist, aber unter Linux ist alles eine Datei .
Das bedeutet, dass Prozesse, Geräte, Tastaturen und Festplatten als Dateien dargestellt werden, die im Dateisystem leben.
Der Linux-Kernel kann diese Dateien unterscheiden, indem er ihnen einen Dateityp zuweist (zum Beispiel eine Datei, ein Verzeichnis, ein Softlink oder ein Socket), aber sie werden vom Kernel in derselben Datenstruktur gespeichert.
Wie Sie wahrscheinlich bereits wissen, werden Linux-Prozesse als Abzweigungen bestehender Prozesse erstellt, die bei neueren Distributionen der Init-Prozess oder der Systemd-Prozess sein können.
Wenn Sie einen neuen Prozess erstellen, verzweigt der Linux-Kernel einen übergeordneten Prozess und dupliziert eine Struktur, die die folgende ist.
b – Wie werden Dateien unter Linux gespeichert?
Ich glaube, dass ein Diagramm mehr als hundert Worte sagt, also werden Dateien konzeptionell auf einem Linux-System gespeichert.

Wie Sie sehen können, wird für jeden erstellten Prozess ein neues task_struct erstellt wird auf Ihrem Linux-Host erstellt.
Diese Struktur enthält zwei Referenzen, eine für Dateisystem-Metadaten (genannt fs ), wo Sie beispielsweise Informationen wie die Dateisystemmaske finden.
Die andere ist eine Struktur für Dateien, die das enthalten, was wir Dateideskriptoren nennen .
Es enthält auch Metadaten über die Dateien, die von dem Prozess verwendet werden, aber wir werden uns in diesem Kapitel auf Dateideskriptoren konzentrieren.
In der Informatik sind Dateideskriptoren Verweise auf andere Dateien, die derzeit vom Kernel selbst verwendet werden.
Aber was stellen diese Dateien überhaupt dar?
c – Wie werden Dateideskriptoren unter Linux verwendet?
Wie Sie wahrscheinlich bereits wissen, fungiert der Kernel als ein Schnittstelle zwischen Ihren Hardwaregeräten (ein Bildschirm, eine Maus, eine CD-ROM oder eine Tastatur).
Dies bedeutet, dass Ihr Kernel verstehen kann, dass Sie einige Dateien zwischen Festplatten übertragen oder beispielsweise ein neues Video auf Ihrem sekundären Laufwerk erstellen möchten.
Infolgedessen verschiebt der Linux-Kernel permanent Daten von Eingabegeräten (z. B. einer Tastatur) zu Ausgabegeräten (z. B. einer Festplatte).
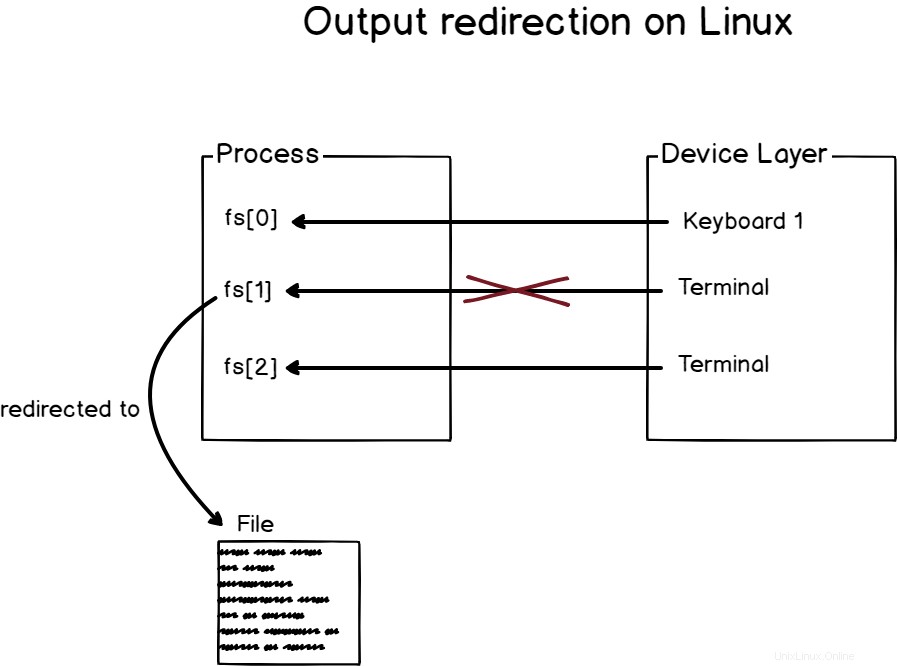
Unter Verwendung dieser Abstraktion sind Prozesse im Wesentlichen eine Möglichkeit, Eingaben zu manipulieren (wie gelesen Operationen), um verschiedene Ausgaben zu rendern (als write Operationen)
Aber woher wissen Prozesse, wohin Daten gesendet werden sollen?
Prozesse wissen, wohin Daten gesendet werden sollen, indem sie Dateideskriptoren verwenden
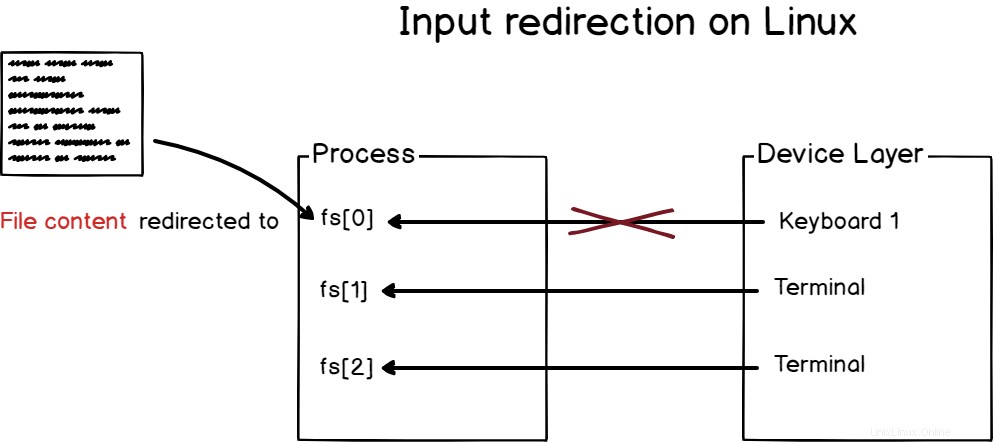
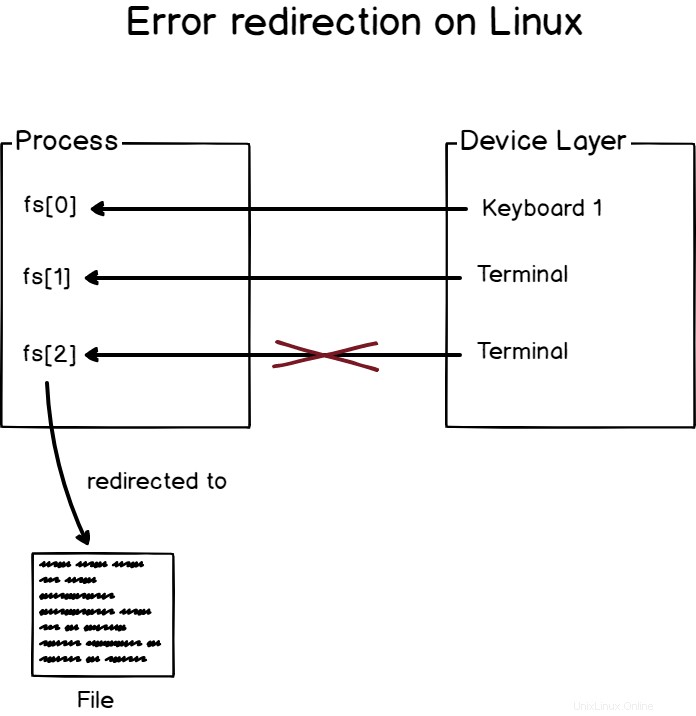
Unter Linux der Dateideskriptor 0 (oder fd[0]) ist der Standardeingabe zugeordnet
Ebenso der Dateideskriptor 1 (oder fd[1]) wird der Standardausgabe zugewiesen , und den Dateideskriptor 2 (oder fd[2]) wird dem Standardfehler. zugeordnet
Es ist eine Konstante auf einem Linux-System, für jeden Prozess sind die ersten drei Dateideskriptoren für Standardeingaben, -ausgaben und -fehler reserviert.
Diese Dateideskriptoren werden Geräten auf Ihrem Linux-System zugeordnet.
Geräte, die bei der Instanziierung des Kernels registriert wurden, können in /dev eingesehen werden Verzeichnis Ihres Hosts.
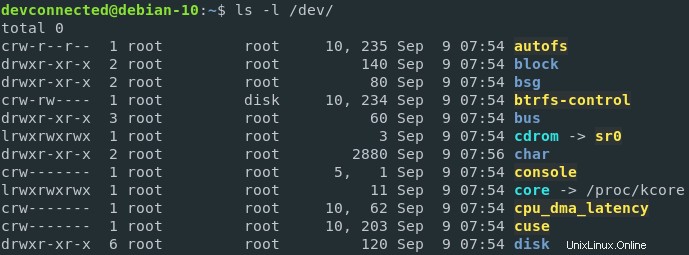
Wenn Sie sich die Dateideskriptoren eines bestimmten Prozesses ansehen, sagen wir zum Beispiel eines Bash-Prozesses, können Sie sehen, dass Dateideskriptoren im Wesentlichen weiche Links zu echten Hardwaregeräten auf Ihrem Host sind.
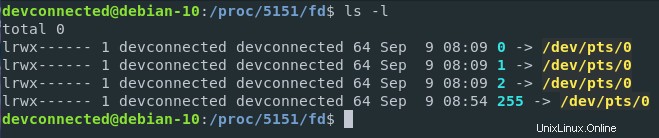
Wie Sie sehen können, kann ich beim Isolieren der Dateideskriptoren meines Bash-Prozesses (der die PID 5151 auf meinem Host hat) die Geräte sehen, die mit meinem Prozess interagieren (oder die vom Kernel für meinen Prozess geöffneten Dateien). /P>
In diesem Fall /dev/pts/0 stellt ein Terminal dar, das ein virtuelles Gerät (oder tty) in meinem virtuellen Dateisystem ist. Einfacher ausgedrückt bedeutet dies, dass meine Bash-Instanz (die in einer Gnome-Terminalschnittstelle läuft) auf Eingaben von meiner Tastatur wartet, sie auf dem Bildschirm ausgibt und sie ausführt, wenn sie dazu aufgefordert wird.
Jetzt, da Sie ein klareres Verständnis von Dateideskriptoren und ihrer Verwendung durch Prozesse haben, sind wir bereit, zu beschreiben, wie die Eingabe- und Ausgabeumleitung unter Linux durchgeführt wird .
2 – Was ist Ausgabeumleitung unter Linux?
Die Eingabe- und Ausgabeumleitung ist eine Technik, die verwendet wird, um umzuleiten/zu ändern Standardeingaben und -ausgaben, die im Wesentlichen ändern, wo Daten gelesen oder wohin Daten geschrieben werden.
Wenn ich zum Beispiel einen Befehl auf meiner Linux-Shell ausführe, könnte die Ausgabe direkt auf meinem Terminal ausgegeben werden (zum Beispiel ein cat-Befehl).
Mit der Ausgabeumleitung könnte ich jedoch die Ausgabe meines cat-Befehls zur Langzeitspeicherung in einer Datei speichern.
a – Wie funktioniert die Ausgabeumleitung?
Ausgabeumleitung ist die Umleitung der Ausgabe eines Prozesses an einen ausgewählten Ort wie Dateien, Datenbanken, Terminals oder andere Geräte (oder virtuelle Geräte), auf die geschrieben werden kann.
Schauen wir uns als Beispiel den echo-Befehl an.
Standardmäßig nimmt die echo-Funktion einen String-Parameter und gibt ihn auf dem Standard-Ausgabegerät aus.
Wenn Sie also die echo-Funktion in einem Terminal ausführen, wird die Ausgabe im Terminal selbst ausgegeben.

Nehmen wir nun an, dass ich möchte, dass die Zeichenfolge stattdessen zur Langzeitspeicherung in eine Datei gedruckt wird.
Um die Standardausgabe unter Linux umzuleiten, müssen Sie den Operator „>“ verwenden.
Um beispielsweise die Standardausgabe der echo-Funktion in eine Datei umzuleiten, sollten Sie
ausführen$ echo devconnected > fileWenn die Datei nicht vorhanden ist, wird sie erstellt.
Als nächstes können Sie sich den Inhalt der Datei ansehen und sehen, dass die Zeichenfolge „devconnected“ korrekt darin gedruckt wurde.

Alternativ ist es möglich, die Ausgabe umzuleiten, indem Sie die „1> ”-Syntax.
$ echo test 1> file
b – Ausgabeumleitung zu Dateien auf zerstörungsfreie Weise
Beim Umleiten der Standardausgabe in eine Datei haben Sie wahrscheinlich bemerkt, dass der vorhandene Inhalt der Datei gelöscht wird.
Manchmal kann es ziemlich problematisch sein, da Sie den vorhandenen Inhalt der Datei beibehalten und nur einige Änderungen an das Ende der Datei anhängen möchten.
Um Inhalte mithilfe der Ausgabeumleitung an eine Datei anzuhängen, verwenden Sie den Operator „>>“ anstelle des Operators „>“.
In Anbetracht des Beispiels, das wir gerade zuvor verwendet haben, fügen wir unserer vorhandenen Datei eine zweite Zeile hinzu.
$ echo a second line >> file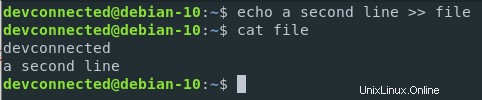
Großartig!
Wie Sie sehen können, wurde der Inhalt an die Datei angehängt, anstatt sie vollständig zu überschreiben.
c – Fallstricke bei der Ausgabeumleitung
Bei der Ausgabeumleitung könnten Sie versucht sein, einen Befehl in eine Datei auszuführen, nur um die Ausgabe in dieselbe Datei umzuleiten.
Umleitung auf dieselbe Datei
echo 'This a cool butterfly' > file
sed 's/butterfly/parrot/g' file > fileWas erwarten Sie in der Testdatei?
Das Ergebnis ist, dass die Datei komplett leer ist.

Warum?
Standardmäßig führt der Kernel beim Analysieren Ihres Befehls die Befehle nicht nacheinander aus.
Das bedeutet, dass es nicht auf das Ende des sed-Befehls wartet, um Ihre neue Datei zu öffnen und den Inhalt darin zu schreiben.
Stattdessen öffnet der Kernel Ihre Datei, löscht den gesamten Inhalt darin und wartet darauf, dass das Ergebnis Ihrer sed-Operation verarbeitet wird.
Da Ihre sed-Operation eine leere Datei sieht (weil der gesamte Inhalt durch die Ausgabeumleitungsoperation gelöscht wurde), ist der Inhalt leer.
Folglich wird nichts an die Datei angehängt und der Inhalt ist komplett leer.
Um die Ausgabe in dieselbe Datei umzuleiten, können Sie Pipes verwenden oder fortgeschrittenere Befehle wie
command … input_file > temp_file && mv temp_file input_fileSchützen einer Datei vor dem Überschreiben
Unter Linux ist es möglich, Dateien mit dem Operator „>“ vor dem Überschreiben zu schützen.
Sie können Ihre Dateien schützen, indem Sie den Parameter „noclobber“ in der aktuellen Shell-Umgebung festlegen.
$ set -o noclobberEs ist auch möglich, die Ausgabeumleitung einzuschränken durch Ausführen
$ set -CHinweis :Um die Ausgabeumleitung wieder zu aktivieren, führen Sie einfach set +C
aus
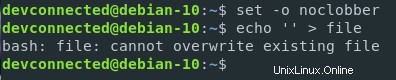
Wie Sie sehen können, kann die Datei beim Setzen dieses Parameters nicht überschrieben werden.
Wenn ich die Überschreibung wirklich erzwingen möchte, kann ich die „>| ”-Operator, um es zu erzwingen.

3 – Was ist Eingabeumleitung unter Linux?
a – Wie funktioniert die Eingabeumleitung?
Eingabeumleitung ist die Umleitung der Eingabe eines Prozesses auf ein bestimmtes Gerät (oder virtuelles Gerät), sodass der Lesevorgang von diesem Gerät beginnt und nicht von dem vom Kernel zugewiesenen Standardgerät.
Wenn Sie beispielsweise ein Terminal öffnen, interagieren Sie mit Ihrer Tastatur damit.
Es gibt jedoch Fälle, in denen Sie möglicherweise mit dem Inhalt einer Datei arbeiten möchten, da Sie den Inhalt der Datei programmgesteuert an Ihren Befehl senden möchten.
Um die Standardeingabe unter Linux umzuleiten, müssen Sie den „<“-Operator verwenden.
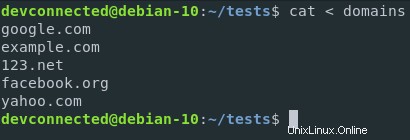
Nehmen wir als Beispiel an, Sie möchten den Inhalt einer Datei verwenden und einen speziellen Befehl darauf ausführen.
In diesem Fall werde ich eine Datei verwenden, die Domains enthält, und der Befehl wird ein einfacher Sortierbefehl sein.
Auf diese Weise werden Domains alphabetisch sortiert.
Mit der Eingabeumleitung kann ich den folgenden Befehl ausführen
Wenn ich diese Domänen sortieren möchte, kann ich den Inhalt der Domänendatei auf die Standardeingabe der Sortierfunktion umleiten.
$ sort < domains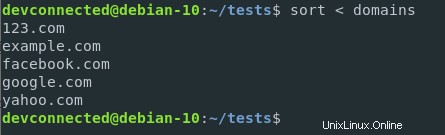
Mit dieser Syntax wird der Inhalt der Domänendatei an die Eingabe der Sortierfunktion umgeleitet. Sie unterscheidet sich deutlich von der folgenden Syntax
$ sort domainsAuch wenn die Ausgabe dieselbe sein mag, nimmt die Sortierfunktion in diesem Fall eine Datei als Parameter.
Im Beispiel der Eingabeumleitung wird die Sortierfunktion ohne Parameter aufgerufen.
Wenn der Funktion also keine Dateiparameter bereitgestellt werden, liest die Funktion sie standardmäßig aus der Standardeingabe.
In diesem Fall liest es den Inhalt der bereitgestellten Datei.
b – Umleitung der Standardeingabe mit einer Datei, die mehrere Zeilen enthält
Wenn Ihre Datei mehrere Zeilen enthält, können Sie trotzdem die Standardeingabe Ihres Befehls für jede einzelne Zeile Ihrer Datei umleiten.
Nehmen wir zum Beispiel an, Sie möchten eine Ping-Anfrage für jeden einzelnen Eintrag in der Domains-Datei haben.
Standardmäßig erwartet der Ping-Befehl, dass eine einzelne IP oder URL angepingt wird.
Sie können jedoch den Inhalt Ihrer Domänendatei an eine benutzerdefinierte Funktion umleiten, die für jeden Eintrag eine Ping-Funktion ausführt.
$ ( while read ip; do ping -c 2 $ip; done ) < ips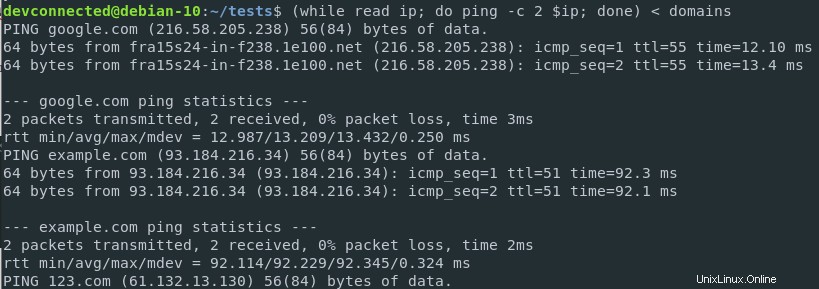
c – Kombination von Eingabeumleitung mit Ausgabeumleitung
Nachdem Sie nun wissen, dass die Standardeingabe auf einen Befehl umgeleitet werden kann, ist es hilfreich zu erwähnen, dass die Ein- und Ausgabeumleitung innerhalb desselben Befehls erfolgen kann.
Jetzt, da Sie Ping-Befehle ausführen, erhalten Sie die Ping-Statistiken für jede einzelne Website auf der Domänenliste.
Die Ergebnisse werden auf der Standardausgabe ausgegeben, die in diesem Fall das Terminal ist.
Aber was, wenn Sie die Ergebnisse in einer Datei speichern möchten?
Dies kann erreicht werden, indem Eingabe- und Ausgabeumleitungen auf demselben Befehl kombiniert werden .
$ ( while read ip; do ping -c 2 $ip; done ) < domains > stats.txt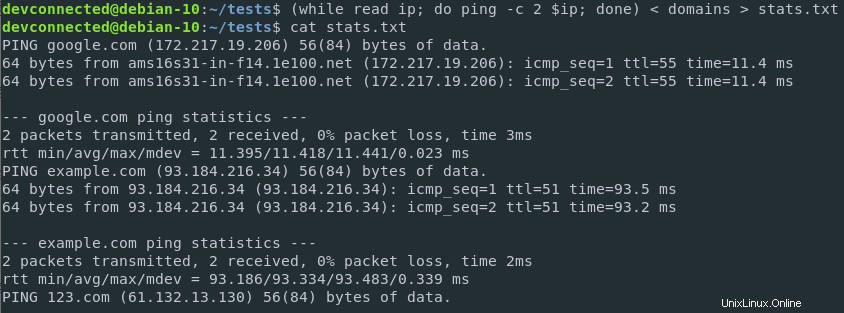
Toll!
Die Ergebnisse wurden korrekt in einer Datei gespeichert und können später von anderen Teams in Ihrem Unternehmen analysiert werden.
d – Standardausgabe vollständig verwerfen
In einigen Fällen kann es praktisch sein, die Standardausgabe vollständig zu verwerfen.
Dies kann daran liegen, dass Sie nicht an der Standardausgabe eines Prozesses interessiert sind oder dass dieser Prozess zu viele Zeilen auf der Standardausgabe ausgibt.
Um die Standardausgabe unter Linux vollständig zu verwerfen, leiten Sie die Standardausgabe nach /dev/null um.
Die Umleitung nach /dev/null führt dazu, dass Daten vollständig verworfen und gelöscht werden.
$ cat file > /dev/nullHinweis:Die Umleitung nach /dev/null löscht nicht den Inhalt der Datei, sondern verwirft nur den Inhalt der Standardausgabe.
4 – Was ist eine Standardfehlerumleitung unter Linux?
Abschließend, nach der Eingabe- und Ausgabeumleitung, lasst uns sehen, wie Standardfehler umgeleitet werden können.
a – Wie funktioniert die Standardfehlerumleitung?
Sehr ähnlich zu dem, was wir zuvor gesehen haben, leitet die Fehlerumleitung von Prozessen zurückgegebene Fehler an ein definiertes Gerät auf Ihrem Host um.
Wenn ich beispielsweise einen Befehl mit fehlerhaften Parametern ausführe, sehe ich auf meinem Bildschirm eine Fehlermeldung, die über den für Fehlermeldungen verantwortlichen Dateideskriptor verarbeitet wurde (fd[2]).
Beachten Sie, dass es keine trivialen Möglichkeiten gibt, eine Fehlermeldung von einer Standardausgabemeldung im Terminal zu unterscheiden, Sie müssen sich darauf verlassen, dass der Programmierer Fehlermeldungen an den richtigen Dateideskriptor sendet.
Um die Fehlerausgabe unter Linux umzuleiten, verwenden Sie die Datei „2> ”-Operator
$ command 2> fileNehmen wir das Beispiel des Ping-Befehls, um eine Fehlermeldung auf dem Terminal zu generieren.

Sehen wir uns nun eine Version an, bei der die Fehlerausgabe in eine Fehlerdatei umgeleitet wird.

Wie Sie sehen können, habe ich den Operator „2>“ verwendet, um Fehler in die Datei „error-file“ umzuleiten.
Wenn ich nur die Standardausgabe in die Datei umleiten würde, würde nichts dorthin gedruckt werden.

Wie Sie sehen können, wurde die Fehlermeldung auf meinem Terminal ausgegeben und meiner „normalen Datei“-Ausgabe wurde nichts hinzugefügt.
b – Kombinieren von Standardfehler mit Standardausgabe
In einigen Fällen möchten Sie vielleicht die Fehlermeldungen mit der Standardausgabe kombinieren und in eine Datei umleiten.
Dies kann besonders praktisch sein, da einige Programme nicht nur Standardmeldungen oder Fehlermeldungen zurückgeben, sondern eine Mischung aus beiden.
Nehmen wir das Beispiel von find Befehl.
Wenn ich einen find-Befehl im Stammverzeichnis ohne sudo-Rechte ausführe, bin ich möglicherweise nicht berechtigt, auf einige Verzeichnisse zuzugreifen, wie zum Beispiel Prozesse, die mir nicht gehören.
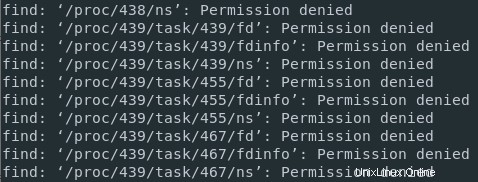
Als Folge wird es eine Mischung aus Standardnachrichten geben (die Dateien, die meinem Benutzer gehören) und Fehlermeldungen (beim Versuch, auf ein Verzeichnis zuzugreifen, das mir nicht gehört).
In diesem Fall möchte ich beide Ausgaben in einer Datei speichern.
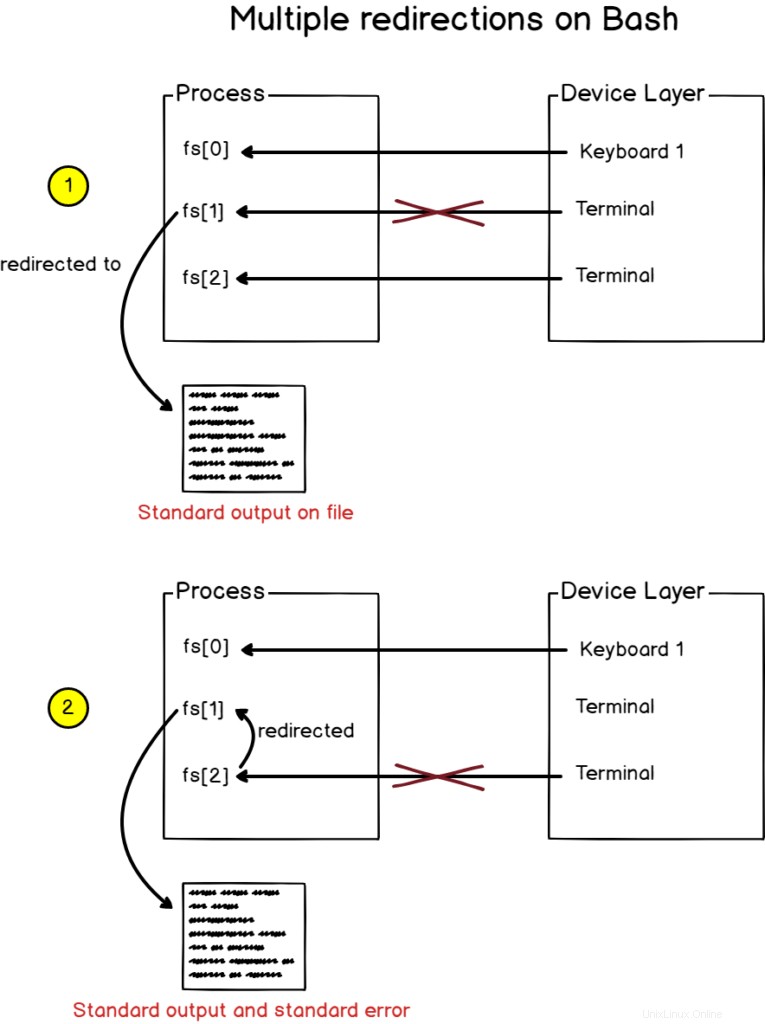
Um sowohl die Standardausgabe als auch die Fehlerausgabe in eine Datei umzuleiten, verwenden Sie die „2<&1“-Syntax mit vorangestelltem „>“.
$ find / -user devconnected > file 2>&1Alternativ können Sie auch das “&>“ verwenden Syntax als kürzerer Weg, um sowohl die Ausgabe als auch die Fehler umzuleiten.
$ find / -user devconnected &> fileAlso, was ist hier passiert?
Wenn bash mehrere Umleitungen sieht, verarbeitet es sie von links nach rechts.
Als Konsequenz wird die Ausgabe der Find-Funktion zunächst auf die Datei umgeleitet.
Als nächstes wird die zweite Umleitung verarbeitet und leitet den Standardfehler auf die Standardausgabe um (die zuvor der Datei zugewiesen war).
5 – Was sind Pipelines unter Linux?
Pipelines unterscheiden sich etwas von Umleitungen.
Bei der standardmäßigen Eingabe- oder Ausgabeumleitung haben Sie im Wesentlichen die Standardeingabe oder -ausgabe in eine benutzerdefinierte Datei überschrieben.
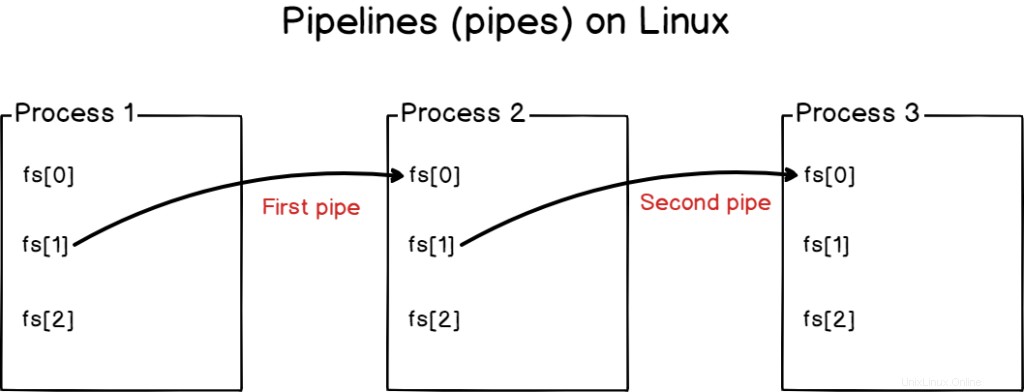
Mit Pipelines überschreiben Sie keine Eingaben oder Ausgaben, sondern verbinden sie miteinander.
Pipelines werden auf Linux-Systemen verwendet, um Prozesse miteinander zu verbinden und Standardausgaben von einem Programm mit der Standardeingabe eines anderen zu verknüpfen.
Mehrere Prozesse können mit Pipelines miteinander verknüpft werden (oder Rohre )
Pipes werden häufig von Systemadministratoren verwendet, um komplexe Abfragen zu erstellen indem Sie einfache Abfragen miteinander kombinieren.
Eines der beliebtesten Beispiele ist wahrscheinlich das Zählen der Zeilen in einer Textdatei, nachdem einige benutzerdefinierte Filter auf den Inhalt der Datei angewendet wurden.
Gehen wir zurück zu der Domaindatei, die wir in den vorherigen Abschnitten erstellt haben, und ändern wir ihre Ländererweiterungen so, dass sie .net-Domains enthalten.
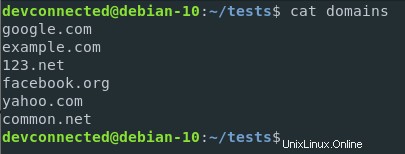
Nehmen wir nun an, Sie möchten die Anzahl der .com-Domains in der Datei zählen.
Wie würden Sie das ausführen? Durch die Verwendung von Pipes.
Zunächst möchten Sie die Ergebnisse filtern, um nur die .com-Domains in der Datei zu isolieren. Dann möchten Sie das Ergebnis an den „wc“-Befehl weiterleiten, um sie zu zählen.
So würden Sie .com-Domains in der Datei zählen.
$ grep .com domains | wc -l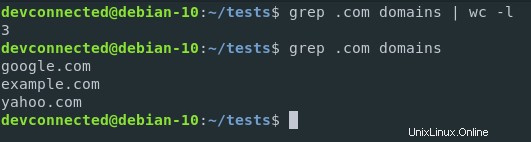
Folgendes ist mit einem Diagramm passiert, falls Sie es immer noch nicht verstehen können.
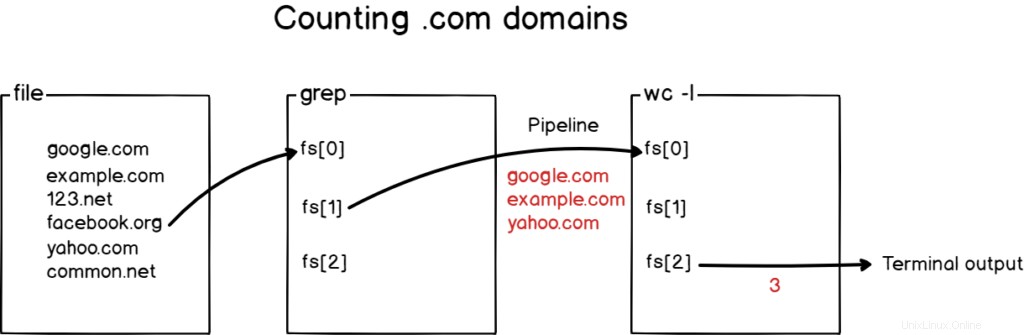
Großartig!
6 – Fazit
Im heutigen Tutorial haben Sie gelernt, was die Eingabe- und Ausgabeumleitung ist und wie sie effektiv verwendet werden kann, um Verwaltungsvorgänge auf Ihrem Linux-System durchzuführen.
Sie haben auch etwas über Pipelines (oder Pipes) gelernt die verwendet werden, um Befehle zu verketten, um längere und komplexere Befehle auf Ihrem Host auszuführen.
Wenn Sie sich für die Linux-Administration interessieren, haben wir auf devconnected eine ganze Kategorie dafür, also schauen Sie sich das unbedingt an!