In dieser Artikelserie behandeln wir das gesamte Cloudera Hadoop Cluster Building Gebäude mit Vendor und Industriell empfohlene Best Practices.
Teil 1 :Best Practices für die Bereitstellung von Hadoop Server auf CentOS/RHEL 7Teil 2 :Einrichten von Hadoop-Voraussetzungen und SicherheitshärtungTeil 3 :So installieren und konfigurieren Sie den Cloudera Manager unter CentOS/RHEL 7Teil 4 :So installieren Sie CDH und konfigurieren Dienstplatzierungen auf CentOS/RHEL 7Teil 5 :Hochverfügbarkeit für Namenode einrichtenTeil 6 :Hochverfügbarkeit für Resource Manager einrichtenTeil 7 :Hive mit Hochverfügbarkeit installieren und konfigurierenTeil 8 :So installieren und konfigurieren Sie Sentry (Autorisierungstool)Teil 9 :So installieren Sie Kerberos (Kerberisierung des Clusters) für die Hadoop-AuthentifizierungTeil 10 :So optimieren Sie Cluster (Yarn Tuning) unter CentOS/RHEL 7Betriebssystem Installation und Ausführen von OS Stufe Voraussetzungen sind die ersten Schritte zum Erstellen eines Hadoop-Clusters . Hadoop kann auf den verschiedenen Arten von Linux-Plattformen ausgeführt werden:CentOS , RedHat , Ubuntu , Debian , SUSE usw. In der Echtzeitproduktion sind die meisten Hadoop-Cluster basieren auf RHEL/CentOS verwenden wir CentOS 7 zur Demonstration in dieser Reihe von Tutorials.
In einer Organisation kann die Betriebssysteminstallation mit Kickstart durchgeführt werden . Wenn es sich um einen 3- bis 4-Knoten-Cluster handelt, ist eine manuelle Installation möglich, aber wenn wir einen großen Cluster mit mehr als 10 Knoten aufbauen, ist es mühsam, das Betriebssystem einzeln zu installieren. In diesem Szenario kommt die Kickstart-Methode ins Spiel, wir können mit der Masseninstallation mit Kickstart fortfahren.
Erzielen einer guten Leistung aus einer Hadoop-Umgebung Dies hängt von der Bereitstellung der richtigen Hardware und Software ab. Erstellen Sie also einen Produktions-Hadoop-Cluster erfordert viel Überlegung bezüglich Hardware und Software.
In diesem Artikel werden wir verschiedene Benchmarks zur Betriebssysteminstallation und einige Best Practices für die Bereitstellung von Cloudera Hadoop Cluster Server durchgehen auf CentOS/RHEL 7 .
Wichtige Überlegungen und Best Practices für die Bereitstellung von Hadoop Server
Im Folgenden finden Sie die Best Practices für die Einrichtung und Bereitstellung von Cloudera Hadoop Cluster Server auf CentOS/RHEL 7 .
- Hadoop-Server erfordern keine Enterprise-Standard-Server, um einen Cluster zu erstellen, es wird handelsübliche Hardware benötigt.
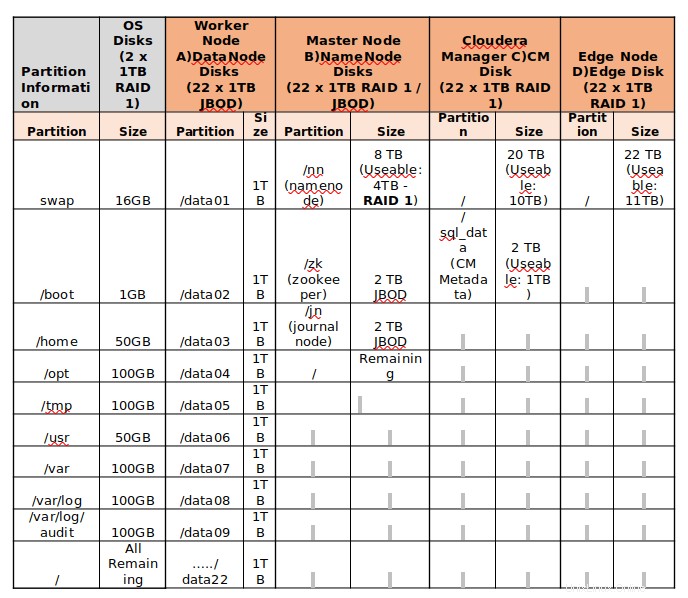
- Im Produktionscluster werden 8 bis 12 Datenträger empfohlen. Je nach Art der Arbeitsbelastung müssen wir darüber entscheiden. Wenn der Cluster für rechenintensive Anwendungen vorgesehen ist, empfiehlt es sich, 4 bis 6 Laufwerke zu haben, um E/A-Probleme zu vermeiden.
- Datenlaufwerke sollten beispielsweise einzeln partitioniert werden – beginnend bei /data01 nach /data10 .
- RAID-Konfiguration wird für Worker-Knoten nicht empfohlen, da Hadoop selbst Fehlertoleranz für Daten bereitstellt, indem die Blöcke standardmäßig in 3 repliziert werden. Also JBOD eignet sich am besten für Worker-Knoten.
- Für Master-Server RAID 1 ist die beste Vorgehensweise.
- Das Standarddateisystem auf CentOS/RHEL 7.x ist XFS . Hadoop unterstützt XFS, ext3 und ext4. Das empfohlene Dateisystem ist ext3, da es auf gute Leistung getestet wurde.
- Alle Server sollten dieselbe OS-Version haben, zumindest dieselbe Nebenversion.
- Es hat sich bewährt, homogene Hardware zu haben (alle Worker-Knoten sollten die gleichen Hardwaremerkmale haben (RAM, Speicherplatz und Kern usw.).
- Je nach Cluster-Arbeitslast (Ausgeglichene Arbeitslast, Rechenintensiv, I/O-Intensiv) und Größe wird die Ressourcenplanung (RAM, CPU) pro Server unterschiedlich sein.
Finden Sie das folgende Beispiel für die Festplattenpartitionierung von Servern mit 24 TB Speicher.
Installieren von CentOS 7 für die Bereitstellung von Hadoop-Servern
Dinge, die Sie vor der Installation von CentOS 7 wissen müssen Server für Hadoop Server .
- Für Hadoop-Server reicht eine minimale Installation aus (Worker-Knoten ), in einigen Fällen kann die GUI nur für Master-Server oder Management-Server installiert werden, wo wir Browser für Web-UIs von Management-Tools verwenden können.
- Das Konfigurieren von Netzwerken, Hostnamen und anderen betriebssystembezogenen Einstellungen kann nach der Installation des Betriebssystems vorgenommen werden.
- In Echtzeit werden Serveranbieter ihre eigene Konsole haben, um beispielsweise mit den Servern zu interagieren und sie zu verwalten – Dell-Server haben iDRAC, ein Gerät, das in Server eingebettet ist. Mithilfe dieser iDRAC-Schnittstelle können wir das Betriebssystem mit einem Betriebssystem-Image in unserem lokalen System installieren.
In diesem Artikel haben wir das Betriebssystem installiert (CentOS 7 ) in der virtuellen VMware-Maschine. Hier werden wir nicht mehrere Festplatten haben, um Partitionen durchzuführen. CentOS ähnelt RHEL (gleiche Funktionalität), also sehen wir die Schritte zur Installation von CentOS .
1. Laden Sie zunächst das ISO-Image von CentOS 7.x in Ihr lokales Windows-System herunter und wählen Sie es beim Booten der virtuellen Maschine aus. Wählen Sie „CentOS 7 installieren“. ‘ wie gezeigt.
2. Wählen Sie die Sprache aus , der Standardwert ist Englisch, und klicken Sie auf Weiter .
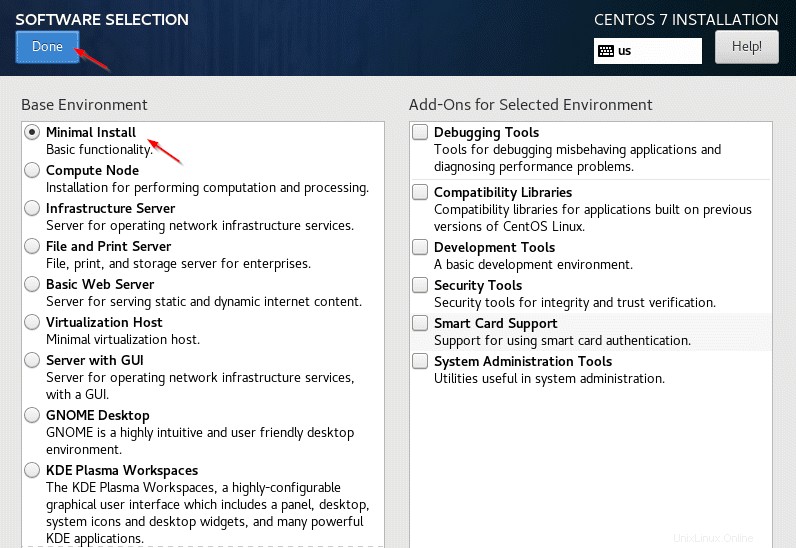
3. Softwareauswahl – Wählen Sie die „Minimalinstallation“. “ und klicken Sie auf „Fertig ‘.
4. Legen Sie das Root-Passwort fest da es uns zur Einstellung auffordert.
5. Installationsziel – Dies ist der wichtige Schritt, um vorsichtig zu sein. Wir müssen die Festplatte auswählen, auf der das Betriebssystem installiert werden soll. Für das Betriebssystem sollte eine dedizierte Festplatte ausgewählt werden. Klicken Sie auf „Installationsziel“. ‘ und wählen Sie die Festplatte aus, in Echtzeit werden mehrere Festplatten vorhanden sein, wir müssen auswählen, vorzugsweise ‚sda ‘.

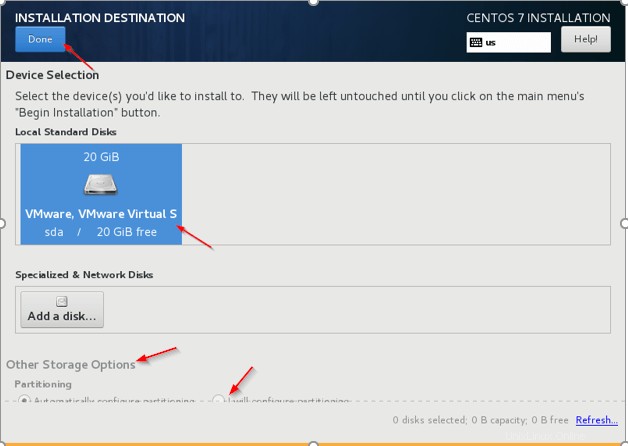
6. Andere Speicheroptionen – Wählen Sie die zweite Option (Ich werde die Partitionierung konfigurieren), um die betriebssystembezogene Partitionierung wie /var zu konfigurieren , /var/log , /home , /tmp , /opt , /swap .

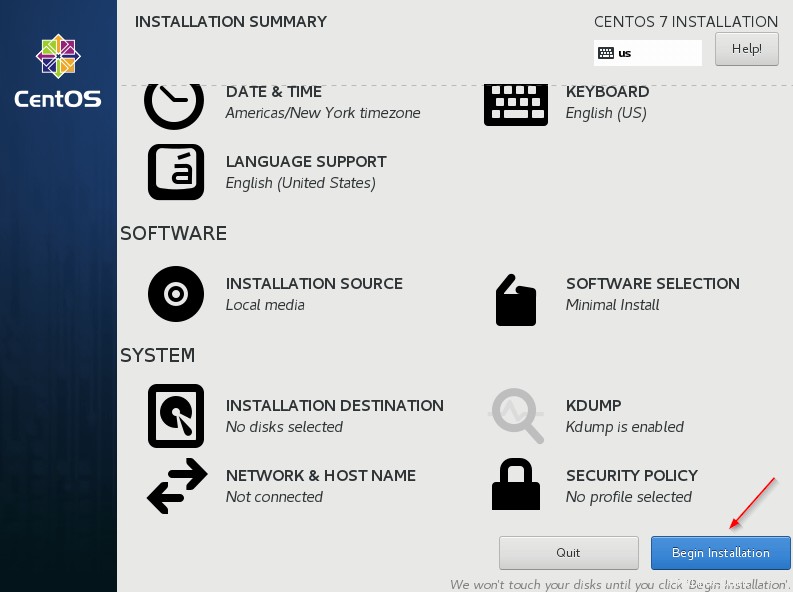
7. Sobald Sie fertig sind, beginnen Sie mit der Installation.
8. Sobald die Installation abgeschlossen ist, starten Sie den Server neu.
9. Melden Sie sich beim Server an und legen Sie den Hostnamen fest.
# hostnamectl status # hostnamectl set-hostname tecmint # hostnamectl status
Zusammenfassung
In diesem Artikel haben wir die Installationsschritte des Betriebssystems und Best Practices für die Partitionierung des Dateisystems durchgegangen. Dies sind alles allgemeine Richtlinien. Je nach Art der Arbeitslast müssen wir uns möglicherweise auf mehr Nuancen konzentrieren, um die beste Leistung des Clusters zu erzielen. Cluster-Planung ist Kunst für Hadoop Administrator. Im nächsten Artikel werden wir uns ausführlich mit den Voraussetzungen auf Betriebssystemebene und der Sicherheitshärtung befassen.