Einführung
Auf dem heutigen Markt kann selbst eine kurze Unterbrechung des Dienstes zum Verlust des Kundenvertrauens und schließlich zu finanziellen Verlusten führen. Dies gilt insbesondere für Unternehmen, die in einem Sektor wie SaaS tätig sind.
Die Verwendung von Disaster Recovery als Service in Ihren Geschäftsprozessen ist unerlässlich, wenn Sie Hochverfügbarkeit und Geschäftskontinuität sicherstellen möchten. Failover und Failback sind einige der am häufigsten verwendeten Notfallwiederherstellungsmethoden.
In diesem Tutorial erklären wir, was Failover und Failback sind, wie sie funktionieren und was sie unterscheidet.

Failover vs. Failback:Zusammenfassung
Ob aufgrund eines unerwarteten Ausfalls, einer Naturkatastrophe oder einer geplanten Wartung, es gibt Zeiten, in denen die Produktionsumgebung vorübergehend nicht verfügbar ist. Failover und Failback sind Disaster-Recovery-Mechanismen, die dabei helfen, die Geschäftskontinuität im Falle eines plötzlichen Ausfalls aufrechtzuerhalten.
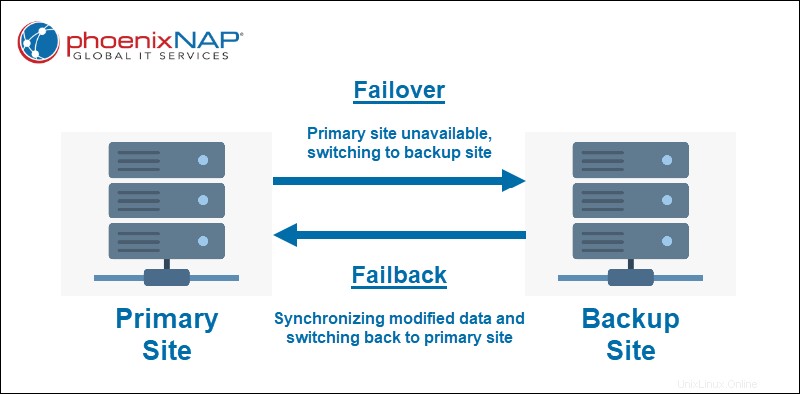
Failover ist der Prozess des Wechsels zu einer designierten Backup-Recovery-Einrichtung. Dies ist normalerweise ein Wiederherstellungsstandort, der eine replizierte Kopie aller Systeme und Daten Ihres primären Produktionsstandorts enthält. Alle während eines Failovers vorgenommenen Änderungen werden im virtuellen Speicher gespeichert.
Failback ist ein Business-Continuity-Mechanismus, der verwendet wird, wenn der primäre Produktionsstandort wieder in Betrieb ist. Die Produktion wird während eines Failbacks an ihren ursprünglichen (oder neuen) Standort zurückgeführt, und alle im virtuellen Speicher gespeicherten Änderungen werden synchronisiert.
Was ist ein Failover?
Failover ist der Prozess des nahtlosen Wechsels von einem primären Produktionsstandort zu einem Backup-Recovery-Standort. Ein Failover findet statt, wenn der primäre Standort aufgrund einer unerwarteten Katastrophe oder im Falle einer geplanten Wartung ausfällt.
Damit ein Failover funktioniert, muss ein Backup-Bare-Metal-Server oder eine virtuelle Maschine vorhanden sein, die als Wiederherstellungsstandortsystem fungiert und bereit ist, den primären Standort im Falle eines Ausfalls zu ersetzen. Da Failover ein wesentlicher Schritt bei der Notfallwiederherstellung ist, müssen die Backup-Systeme selbst gegen Ausfälle immun sein.
Failover und Disaster Recovery als Ganzes sind für Systeme erforderlich, die eine ständige Verfügbarkeit erfordern. Auf Serverebene verfolgt die Sicherungsumgebung den "Puls" des primären Servers und führt ein automatisches Failover durch, wenn ein Ausfall festgestellt wird.
Wie funktioniert ein Failover?
Es gibt zwei Möglichkeiten, ein Failover-System einzurichten:ein aktiv-aktiv und aktiv-passiv (oder Aktiv-Standby)-Konfiguration. Beide Setups erfordern mindestens zwei Knoten (Server oder VMs), um ordnungsgemäß zu funktionieren.
In einem aktiv-aktiv Setup laufen mehrere Knoten gleichzeitig. Dadurch können sie die Arbeitslast teilen und verhindern, dass ein Knoten überlastet wird. Wenn ein Knoten nicht mehr funktioniert, wird seine Arbeitslast von anderen aktiven Knoten übernommen, bis er wieder aktiviert wird.
Ein aktiv-passiv (Aktiv-Standby)-Setup umfasst auch mehrere Knoten, aber nicht alle sind gleichzeitig aktiv. Sobald ein aktiver Knoten nicht mehr funktioniert, wird ein passiver Knoten aktiviert und fungiert als Failover-Knoten. Wenn der primäre Knoten wieder funktioniert, schaltet der Backup-Knoten den Betrieb zurück auf den primären Knoten und wird wieder passiv.
Unabhängig von der Failover-Methode erfordern beide Konfigurationen, dass jeder Knoten eine identische Konfiguration hat. Dies gewährleistet Konsistenz und Stabilität beim Wechseln zwischen Websites.
Was ist ein Failback?
Failback ist der Prozess der Rückkehr zum primären Standort, nachdem die geplante oder ungeplante Störung behoben wurde. Failback folgt normalerweise als Teil eines Disaster-Recovery-Plans auf Failover.
Failback ist nicht die einzige Möglichkeit, ein Failover abzuschließen. Wenn Sie mit virtuellen Maschinen arbeiten, können Sie ein permanentes Failback durchführen, wodurch die virtuelle Backup-Maschine zum neuen primären Standort wird.
Wie funktioniert ein Failback?
Während eines Failover-Zustands interagieren Administratoren mit einer Backup-Site. Alle in diesem Zeitraum vorgenommenen Änderungen werden als Änderungsdaten gespeichert .
Sobald ein Failback auftritt, umfasst das Synchronisieren der primären Site und der Wiederherstellungs-Site das Kopieren von Änderungsdaten von der Wiederherstellung zum primären Standort. Dadurch wird eine vollständige Systemkopie überflüssig, was Zeit spart und die Zuverlässigkeit verbessert.
Die erfolgreiche Durchführung eines Failbacks erfordert einige Vorbereitungen. Berücksichtigen Sie die folgenden Schritte, bevor Sie zurück zur primären Website wechseln:
- Überprüfen Sie die Qualität und Netzwerkbandbreite der Verbindung zum primären Standort.
- Überprüfen Sie alle Daten auf der Backup-Site auf mögliche Fehler. Dies ist besonders wichtig für kritische Dateien und Dokumentationen.
- Testen Sie alle primären Systeme gründlich, bevor Sie ein Failback starten.
- Erstellen und implementieren Sie einen Failback-Plan, der Ausfallzeiten und Unannehmlichkeiten für Benutzer minimiert.