Awk ist das beliebteste Dienstprogramm, das zum Zweck der Datenextraktion, Textverarbeitung und darüber hinaus zum Erstellen formatierter Berichte entwickelt wurde. Es ist sed viel ähnlicher, aber leistungsfähiger als sed, da sed Einschränkungen bei der Textverarbeitung hat. AWK hat keine spezifische Bedeutung für seinen Namen, da er nach den Anfangsbuchstaben seiner Entwickler Alfred Aho, Peter J. Weinberger und Brian Kernighan benannt wird.
In diesem Artikel werden wir 10 großartige awk-Befehle lernen, die Sie kennen müssen. Als Beispiel habe ich den folgenden Datensatz in der student.txt erstellt und hinzugefügt. Der Datensatz hat 4 Spalten, wobei das erste Feld den Vornamen, das zweite Feld den Nachnamen, das dritte das Alter und das letzte die Klasse enthält.

Spezifisches Feld mit Variable drucken
Awk hat viele vorgefertigte Variablen, die ihren jeweiligen Zweck haben. Mit diesem Befehl können wir alle spezifischen Felddaten mit $x drucken, wobei x sich auf die Position der Feldnummerierung bezieht.
$ awk '{print $1, $2}' student.txt

BEGIN-Variable
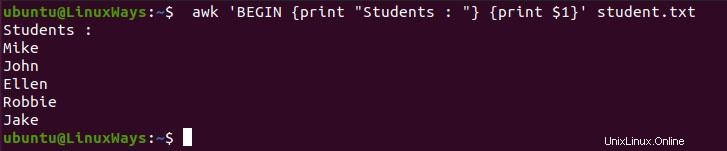
Die BEGIN-Variable wird verwendet, um Kopfzeilen oder Titel zu den resultierenden Daten hinzuzufügen, wenn das Skript ausgeführt wird, bevor die Daten verarbeitet werden. Es hilft bei der Indizierung beim Formatieren der Datentabellen. Im folgenden Beispiel habe ich etwas Text als Indizierung gedruckt und dann alle Studentennamen gedruckt.
$ awk 'BEGIN {print "Students : "} {print $1}' student.txt
END-Variable
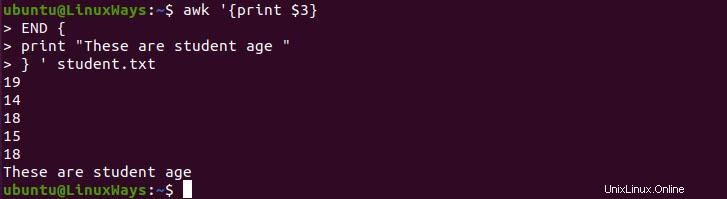
END ist genau das Gegenteil von BEGIN, da es das Skript nach der Datenverarbeitung ausführt. Es kann für die endgültige Berichterstattung des Datensatzes verwendet werden. Im folgenden Beispiel habe ich das gesamte Schüleralter gedruckt und dann einige Endnachrichten gedruckt.
$ awk '{print $3}
END {
print "These are student age "
} ' student.txt
Dateitrennzeichen
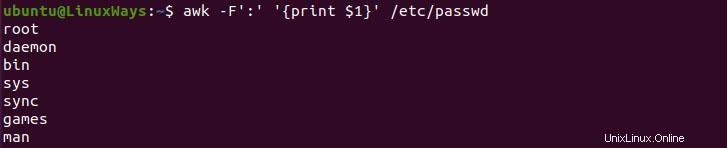
Leerzeichen und Tabstopps sind Standardtrennzeichen des awk-Befehls, aber wir können Text basierend auf anderen Trennzeichen wie Komma, Schrägstrich usw. trennen. Um dies zu erreichen, müssen wir das -F-Flag zum Befehl hinzufügen und das Trennzeichen in einem einfachen Anführungszeichen bereitstellen .
$ awk -F':' '{print $1}' /etc/passwd
Skript aus Datei ausführen
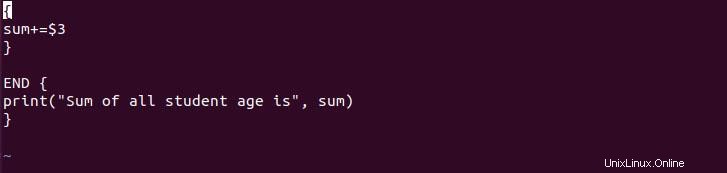
Wir können das awk-Skript auch aus der Datei ausführen, was uns die Tendenz gibt, Berichte effizient zu erstellen. Dazu müssen Sie die Datei erstellen, dann das Skript schreiben und es mit dem awk-Befehl ausführen. Für die Demo können Sie einen Dateinamen demo_script erstellen und das folgende Skript kopieren und einfügen.
$ vi demo_script
{
sum+=$3
}
END {
print("Sum of all student age is", sum)
}
Der awk-Befehl stellt ein -f-Flag bereit, um das Skript aus der Datei auszuführen.
$ awk -f demo_script student.txt

Mehrere Skripte verwenden
Wir können die mehreren Skripte mit dem Semikolon ausführen. Im folgenden Beispiel habe ich etwas Text ausgegeben, dann die Ausgabe mit awk geleitet und das geänderte Ergebnis ausgegeben.
$ echo "Hello, Dr. John" | awk '{$3="George"; print $0}' drucken

Anzahl der Zeilen zählen
Wir können die Nummer dem Bericht zuweisen, indem wir die NR-Variable verwenden, die eine eingebaute awk-Variable ist, die automatisch die Zeilennummer in den Bericht druckt.
$ awk '{print NR "\t" $0}' student.txt

Anzahl der Felder zählen
Manchmal haben wir beim Vorbereiten der Daten vergessen, Daten in die jeweilige Spalte einzufügen, was zu Unregelmäßigkeiten im Bericht führen kann. Wir können Felder mit der NF-Variablen zählen, was uns die Überprüfung und Anordnung der Berichte erleichtert.
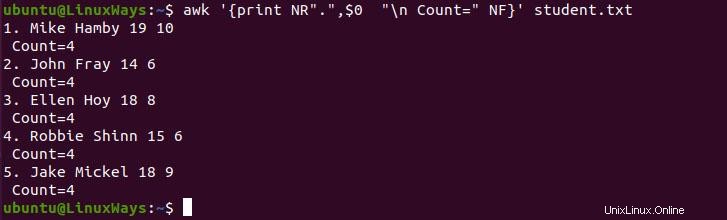
$ awk '{print NR".",$0 "\n Count=" NF}' student.txt
If-Bedingung
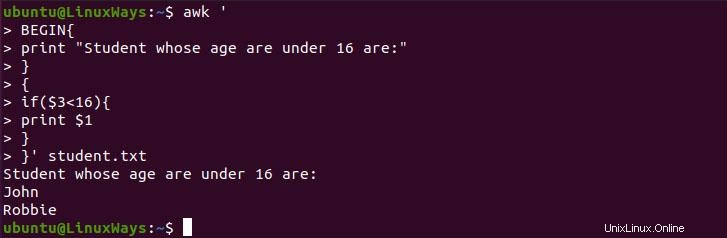
Wir können die if-Bedingung verwenden, um einen bedingten Bericht zu erstellen. Im folgenden Beispiel drucken wir alle Schüler, deren Alter unter 16 ist
$ awk '
BEGIN{
print "Student whose age are under 16 are:"
}
{
if($3<16){
print $1
}
}' student.txt
For-Schleife
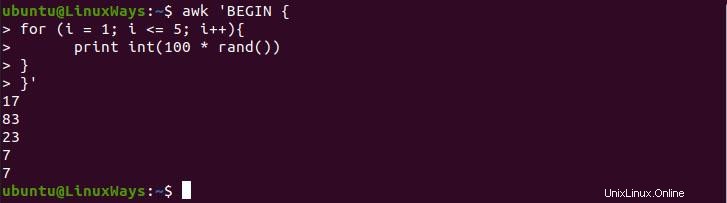
Im folgenden Beispiel verwenden wir die for-Schleife, um 5 Zufallszahlen nacheinander auszugeben. Zum Generieren von Zufallszahlen verwenden wir die Funktion rand(), die eine systemeigene Funktion ist. Diese Funktion generiert eine Zufallszahl in Dezimalzahl, also müssen wir 100 multiplizieren, um Zufallszahlen von 1 bis 100 zu erhalten.
$ awk 'BEGIN {
for (i = 1; i <= 5; i++){
print int(100 * rand())
}
}'
Schlussfolgerung
In diesem Artikel haben wir die 10 großartigen awk-Befehle und -Skripte kennengelernt. Ich hoffe, dass Ihnen dieser Artikel gefallen wird.